自监督学习-SLAPS: Self-Supervision Improves Structure Learning for Graph Neural Networks
自监督学习-SLAPS: Self-Supervision Improves Structure Learning for Graph Neural Networks
标签:自监督学习、图神经网络
动机&背景
- 当可用的图结构表现出高度的同质性 (即连接的节点通常属于同一类) 时, 图神经网路在半监督分类上展现很好的性能
- 在研究图神经在图结构不容易获得情况下对 (半监督) 分类问题的适用性, 这个问题的现有方法是在修复节点之间的相似图或者同时学习
GNN参数和图结构相似, 在这两种情况下, 一个主要目标时构建或学习一个与标签具有高度同质性的图结构, 以帮助GNN分类, 后一种方法有时被称为潜在图学习 - 发现一个潜在图学习方法的饥饿问题, 即距离标记节点较远的节点对之间边没有得到足够的监督, 这导致血虚原理标记节点的不良结构, 因此泛化能力差, 针对这一问题突出一种采用多任务学习的框架的解决方案, 在该框架中, 用自监督任务补充分类任务, 自监督任务基于假设: 适合预测节点特征的图结构也适合预测节点标签。 它的工作原理是屏蔽一些输入特征(或向它们添加噪声)并训练一个单独的
GNN,旨在更新邻接矩阵,使其能够恢复被屏蔽(或噪声)的特征。 该任务是通用的,可以与几种现有的潜在图学习方法结合使用
贡献
- 发现潜在图学习饥饿问题, 距离标记节点较远的节点对之间的边没有得到足够的监督
- 通过自监督对发现的问题突出一种解决方案
- 提出了
SLAPS, 一个采用自监督解决方案的潜在图学习模型 - 在多个数据集上综合测试了该模型
思想
多任务学习框架, 对于正常的分类任务增加一个自监督任务 (也就是对于原特征矩阵加噪(掩蔽一些节点的信息)然后与邻接矩阵一起进行输入输出一个没有噪声的矩阵最后最小化损失函数).
相关工作
Similarity graph
推断图结构的一种方法是选择相似性度量,并将两个节点之间的边权重设置为它们的相似性。为了获得稀疏结构,可以创建一个 kNN 相似度图,只连接相似度超过某个预定阈值的节点对,或者进行采样
Fully connected graph
另一种方法是从一个完全连通的图开始,并使用可用的元数据分配边权重,或者采用通过注意力机制为每个边提供权重的 GNN 变体
Latent graph learning
代替基于初始特征的相似性图,可以使用具有可学习参数的图生成器 (比如:基于具有可学习参数的双线性相似函数创建了完全连通图; 为每个可能的边学习伯努利分布,并通过从这些分布中采样来创建图结构; 输入结构被更新以基于标签和模型预测增加同质性; 提出了一种迭代方法,该方法多次迭代将节点投影到潜在空间,并从潜在表示构造邻接矩阵; 通过学习每个输入特征的权重,将节点投影到潜在空间; 多层感知器用于投影 ; GNN 用于投影;它使用节点特征和初始图结构)
框架
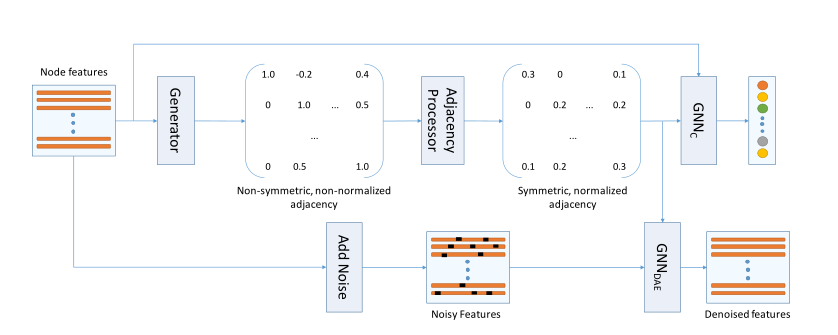
对于特征矩阵, 首先经过生成器 \(G:~~\mathbb{R}^{n \times f} \rightarrow \mathbb{R}^{n \times n}\) , 生成一个邻接矩阵 \(\widetilde{A}\), 经过一个边处理器 \(A = \frac{1}{2} D^{-\frac{1}{2}}(P(\widetilde{A}) + P(\widetilde{A})^T)D^{-\frac{1}{2}}\), 得到对称化和归一化的邻接矩阵 \(A\), 随后经过一个分类器 $GNN_C:\mathbb{R}^{n×f} ×\mathbb{R}^{n×n} → \mathbb{R}^{n×| C |} $ 得到每个节点的对应标签的概率值后最小化分类损失. 在应自监督方面, 向原特征矩阵添加噪声得到一个含有噪声的特征矩阵 \(\widetilde{X}\), 然后利用噪声特征矩阵 \(\widetilde{X}\) 和对称化和归一化的矩阵 \(A\) 输入到 \(GNN_{DAE}\) 中, 输出一个没有噪声的特征矩阵 \(X\), 然后最小化损失函数 \(\mathcal{L} = L(X_{idx}, GNN_{DAE}(\widetilde{X},A;\theta_{GNN_{DAE}})_{idx})\)
算法
Generator
这个生成器是一个参数为 \(\theta_{G}\) 的函数 \(G:~\mathbb{R} ^{n \times f} \rightarrow \mathbb{R}^{n \times n}\) , 该函数以节点特征 \(X \in \mathbb{R} ^{n \times f}\) 为输入输出一个矩阵 \(\widetilde{A} \in \mathbb{R}^{n \times n}\) , 我们考虑一下两个图生成器 (把更复杂的图生成器和具有易处理临界计算的模型作为未来的工作)
Full parameterization
对于这个生成器, \(\theta_{G} \in \mathbb{R} ^ {n \times n}\) 和生成器函数被定义为 \(\widetilde{A}= G_{FP}(X; \theta_{G}) = \theta_{G}\), 这个生成器忽略输入节点特征而是直接优化邻接矩阵, FP 对于学习恩赫邻接矩阵都是简单而灵活的, 但是增加 \(n^2\) 的参数这限制了可伸缩性, 并且使得模型容易过拟合.
MLP-kNN
此时的 \(\theta_{G}\) 类似于多层感知机 (MLP) 的权重, \(\widetilde{A} = G_{FP}(X, \theta_{G}) = kNN(MLP(X))\), $MLP:~\mathbb{R}^{n \times f} \rightarrow \mathbb{R}^{n \times f'} $ 用于更新节点的表示 \(X'\) (也是一个矩阵), \(kNN:~~\mathbb{R}^{n \times f'} \rightarrow \mathbb{R}^{n \times n}\) 生成一个稀疏矩阵.
Initialization and variants of MLP-kNN
让 \(A^{kNN}\) 表示通过在初始节点特征上应用 kNN 函数创建的邻接矩阵. 使用 \(\theta_{G}\) 去初始化然后生成初始的 \(A^{kNN}\) (比如 \(\widetilde{A} = A^{kNN}\) 在训练前), 对于 FP, 直接初始化 \(\theta_{G}\) 去初始化 \({A}^{kNN}\) . 对于 MLP-kNN ,考虑两个版本. 第一个为 MLP ,我们保持输入维度在所有层中相同. 另一个称为 MLP-D, 我们考虑具有对角权重矩阵的 MLP (除了主对角线, 权重矩阵中的所有其他参数都为零). 对于这两种变体, 我们用单位矩阵初始化 \(\theta_{G}\) 中的权重矩阵,以确保 MLP 的输出最初与其输入相同,并且在这些输出上创建的 kNN 图等效于 \(A^{kNN}\)(或者可以使用其他 MLP变体, 但在主要训练开始之前预训练权重以输出 \(A^{kNN}\)). MLP-D 可以认为是给不同的特征分配不同的权重,然后计算节点相似度
Adjacency processor
通过生成器生成的矩阵 \(\widetilde{A}\) 可能有负值也可能有正值或者是非对称和没有进行归一化的, 所以我们设 \(A = \frac{1}{2} D^{-\frac{1}{2}}(P(\widetilde{A}) + P(\widetilde{A})^T)D^{-\frac{1}{2}}\), 子式 \(P(\widetilde{A}) + P(\widetilde{A})^T\) 的结果是使矩阵对称
Classifier
分类器是一个函数 $GNN_C:\mathbb{R}^{n×f} ×\mathbb{R}^{n×n} → \mathbb{R}^{n×| C |} $ 参数为 \(θ_{GNN_C}\). 它将节点特征 \(X\) 和生成的邻接矩阵 \(A\) 作为输入,并为每个节点提供每个类的 logits . \(C\) 对应于类,\(|C|\) 对应于类的数量。我们使用两层 GCN,\(θ_{GNN_C}= \{W^{(1)},W^{(2)}\}\) 并将我们的分类器定义为 \(GNN_C(A,X;θ_{GNN_C}) = AReLU(AXW^{(1)})W^{(2)}\). 但是也可以使用其他 GNN 变体。分类任务的训练损失 \(\mathcal{L}_C\) 是通过取 softmax 最大值来产生每个节点的概率分布,然后计算交叉熵损失来计算
Using only the first three components leads to supervision starvation (仅用前三个组件会导致监督不够充分问题 (饥饿问题))
在训练中两个没有标签的节点 \(v_i\) 和 \(v_j\) 根据生成的结构没有直接相连任何有标签的的节点, 然后由于两层 GCN 基于节点的两跳邻居对节点进行预测, 分类损失不受 \(v_i\) 和 \(v_j\) 边的影响, \(v_i\) 和 \(v_j\) 没有受到监督, 把不影响损失函数 \(\mathcal{L}_C\) 的边称为饥饿边, 这些边是有问题的, 因为尽管他们可能不会影响训练损失, 但是测试时的预测取决于这些边, 如果没有足够监督的情况下学习他们的值, 模型可能会在测试时做出不佳的预测. 如下图:
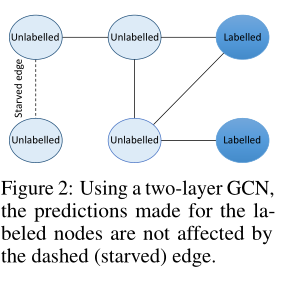
定理: 假设 \(\mathcal{G}(m, n)\) 是一个有 \(n\) 个节点和 \(m\) 条边的 \(Erdos-Renyi\) 图, 假设我们有随机均匀选择的 \(q\) 个节点的标签。具有两层 GCN 的边是饥饿边的概率等于: \((1 - \frac{q}{n})(1 - \frac{q}{n - 1})\prod_{i = 1}^{2q}(1 - \frac{m - 1}{\tbinom{n}{2} -i})\)
Self-supervision
自监督任务是基于自动编码器, 设 \(GNN_{DAE}: \mathbb{R}^{n \times f} \times \mathbb{R}^{n \times n} \rightarrow \mathbb{R}^{n \times f}\), 是一个带有参数 \(\theta_{GNN_{DAE}}\) 的 GNN, 输入节点特征和一个生成的矩阵然后更新节点特征后以相同的维度进行输出, 训练 \(GNN_{DAE}\) 是以带有噪声的特征向量 \(X\) 和作为输入经过出力后输出没有草绳的特征向量 \(X\) , 让 \(X_{idx}\) 代表于我们添加了噪声的 \(X\) 元素对应的索引, \(idx\) 代表这些索引的值. 在训练中, 我们最小化:
最后模型训练最小化:
实验
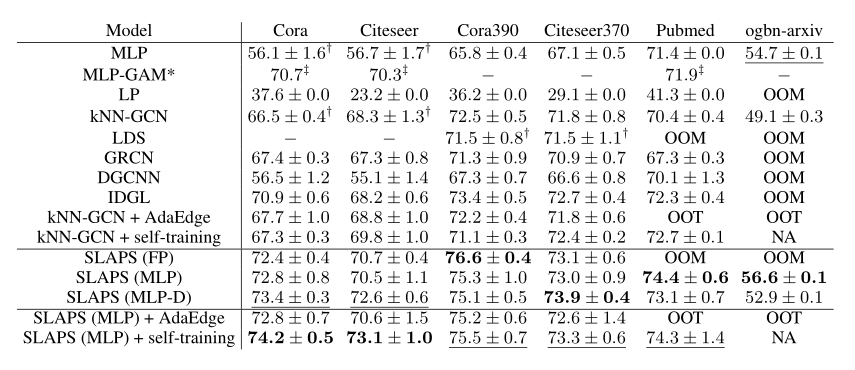
节点分类任务
总结
提出了SLAPS : 一种从数据中同时学习图神经网络的参数和节点连接的图结构的模型。并且发现了图结构学习中出现的监督饥饿问题,尤其是当训练数据稀缺时。基于此提出了一种解决监督饥饿问题的方法,即在训练目标的基础上增加一个动机良好的自我监督任务

 浙公网安备 33010602011771号
浙公网安备 33010602011771号