无监督-TOPOTER: UNSUPERVISED LEARNING OF TOPOLOGY TRANSFORMATION EQUIVARIANT REPRESENTATIONS
无监督-TOPOTER: UNSUPERVISED LEARNING OF TOPOLOGY TRANSFORMATION EQUIVARIANT REPRESENTATIONS
标签:无监督学习、图神经网络
动机
- 当前的 GCNN 监督训练要求标签量非常的大,而在缺乏标签也正是 GCNN 的性能就会受限的关键
- 转换等变化表示已经应用在图数据结构中,但只是应用于节点的等变换,拓扑结构的等变换表示没有进行探索
贡献
- 提出了拓扑转换等变表示 (Topology Transformation Equivariant Representation(TopoTER)) 学习,以无监督的方式推断表示节点的特征表示,它可以通过探索连通拓扑的图转换来表征图的内在结构和相关特征
- 提出的 TopoTER 从信息理论的角度来看, 通过最大化之间的互信息特征表示和拓扑变换, 可轻松转换和应用之间的交叉熵最小化预测在一个端到端的图卷积、自动编码架构上
思想
通过拓扑变换将图进行编码解码重构图强制模型学习图的特征表示
定义
符号定义
一个无向图 \(\mathcal{G} = \{\mathcal{V}, \mathcal{E}, A\}\), 顶点集合 \(|\mathcal{V}| = N\), 边集合 \(\mathcal{E} = M\), \(A\) 是一个邻接矩阵, 特征矩阵 \(X \in \mathbb{R} ^{N \times C}\)
拓扑变换
定义拓扑变换 \(t\) 表示在原图 \(\mathcal{G}\) 边集 \(\mathcal{E}\) 加入或者移除边, 假设一个伯努利分布 \(\mathcal{B}(p)\), \(p\) 被顶i为每条边被修改的概率, 我们生成一个随机矩阵 \(\sum = \{ \sigma_{i,j}\}_{N \times N}\) , $\sum ~ ~\mathcal{B}(p) $, 我们可以得到扰动后的邻接矩阵
该策略通过拓扑变换 \(t\) 生成变换后的图, 比如\(\widetilde{A} = t(A)\), 当 \(p = 0\) 时原图没有进行变换, 这个变换矩阵 \(\widetilde{A}\) 也可以被写为原始邻接矩阵和拓扑扰动矩阵 \(\Delta A\)
\(\Delta A = \{\delta_{i, j}\}_{N \times N}\) 编码为边的扰动, \(\delta_{i,j} \in \{-1, 0, 1\}\), \(0\) 表示没有进行改变, \(1\) 表示加边, \(-1\) 表示移除边. 如下图表示的变换
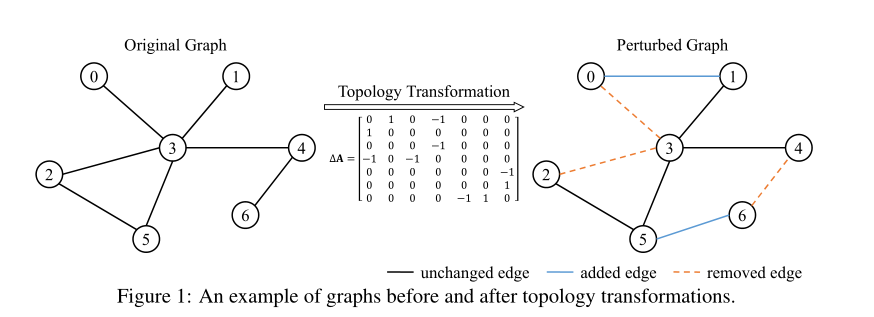
框架
对于一个原图 \(G(X,A)\) , 首先通过拓扑特征变换得到另一个图 \(G(X,\widetilde{A})\), 然后将这两个图分别送进 GCNN 编码器 \(E(\cdot)\) 进行编码 (这两个编码器共享权重), 分别得到两个的图的表示 \(H, \widetilde{H} \in \mathbb{R}^{N \times F}\) , 通过将这两图特征表示相减得到 \(\Delta H \in \mathbb{R} ^{N \times F}\) , 然后通过 \(\Delta H\) 重新构造得到边表示, 最后通过线性层得到 \(\hat{\Delta A}\)
算法
Topology Transformation
从 \(\mathcal{E}\) 中随机采样一个边集进行拓扑扰动---添加边或者删除边, 不仅能够在不同尺度上表征局部体结构, 而且减少了估计计算效率的边变换参数的数量, 特别的, 在每次迭代训练中, 我们采样所有有边相连的节点 \(S_1\), 然后随机生成没有没有边的节点对 \(S_0\)
然后随机切分 \(S_0\) 和 \(S_1\) 进两个不相交的集合:
\(r\) 是边扰动比率, 对于每一个在\(S_{0}^{(1)},S_{1}^{(1)}\)节点对 \((i, j)\), 我们翻转原始图邻接矩阵中的边, 如果 \(a_{i,j} = 0\), \(a_{i,j} = 0\), 我们使 \(a_{i,j} = 1\) , 反之亦然; 对于每一个在\(S_{0}^{(2)},S_{1}^{(2)}\)节点对 \((i, j)\), 我们保持原来的类型. 对采样的拓扑变换参数分为四类, s四种类型的比率为: \(r : r : (1 - r): (1 - r)\):
- 向没有边相连的节点对增加一个边, \(\{t: ~ a_{i,j} = 0 \mapsto \widetilde{a}_{i,j} = 1, (i, j) \in S_{0}^{(1)}\}\)
- 在原有边的的节点进行删边, \(\{t: ~ a_{i,j} = 1 \mapsto \widetilde{a}_{i,j} = 0, (i, j) \in S_{1}^{(1)}\}\)
- 保持原来没有边的节点, \(\{t: ~ a_{i,j} = 0 \mapsto \widetilde{a}_{i,j} = 0, (i, j) \in S_{0}^{(2)}\}\)
- 保持原来有边的节点, \(\{t: ~ a_{i,j} = 1 \mapsto \widetilde{a}_{i,j} = 1, (i, j) \in S_{1}^{(2)}\}\)
Representation Encoder
我们训练一个编码器进行编码 \(E:~(X,A) \mapsto E(X,A)\) 对图中的节点特征进行编码, 我们利用共享权值 GCNNs 来提取图信号中每个节点的特征表示, 以 GCN 为例:
\(D\) 是一个度矩阵 \(A+I\), \(W \in \mathbb{R}^{C \times F}\) 是一个学习参数矩阵, \(H = [h_1, h_2,...,h_N]^T \in \mathbb{R}^{N \times F}\), 相似的转换后的节特征也是共享权重 \(W\):
因此我们可以获得原图和转换后图的表示 \(H、\widetilde{H}\)
Transformation Decoder
通过 \(\widetilde{H}, H\) 促使我们训练一个编码器 \(D:~(\widetilde{H}, H) \mapsto \hat{\Delta A}\) , 通过变换前后的联合表示来估计拓扑变换, 我们首先沿着特征通道获取变换前后提取的特征表示之间的差异:
因此,我们可以通过节点间的特征差异 \(\Delta H\),通过构造边表示为,来预测节点 $i $ 和节点 \(j\) 之间的拓扑转换
\(\odot\) 表示两个向量哈达玛积来捕获特征表示, \(|| \cdot ||_1\) 表示 \(l_1\) 范式归一个向量, 然后,将节点 \(i\) 和 \(j\) 的边缘表示 \(e_{i,j}\) 送入若干线性层,用于预测拓扑变换:
最小化该损失函数
\(f\) 表示变换类型, \(f \in \{0, 1, 2, 3\}\), \(y\) 是每个变换参数类型二进制指示符.
实验
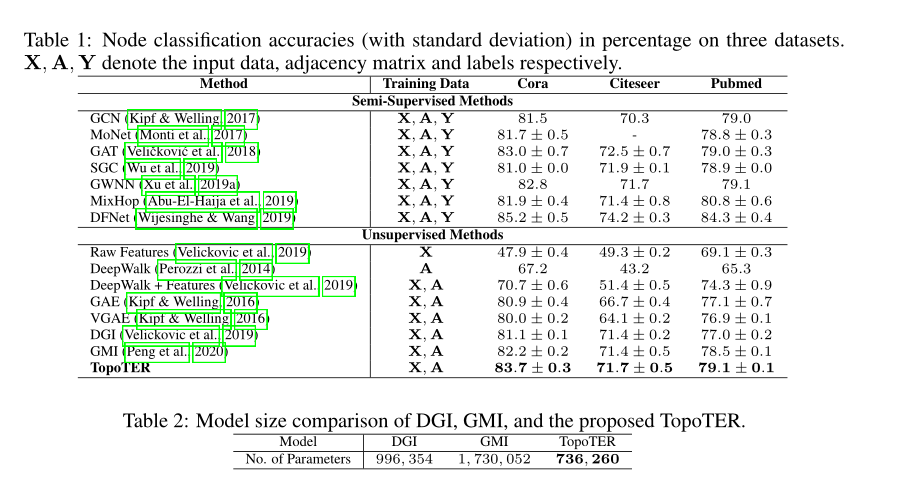
在节点分类上与半监督和无监督的进行比较.
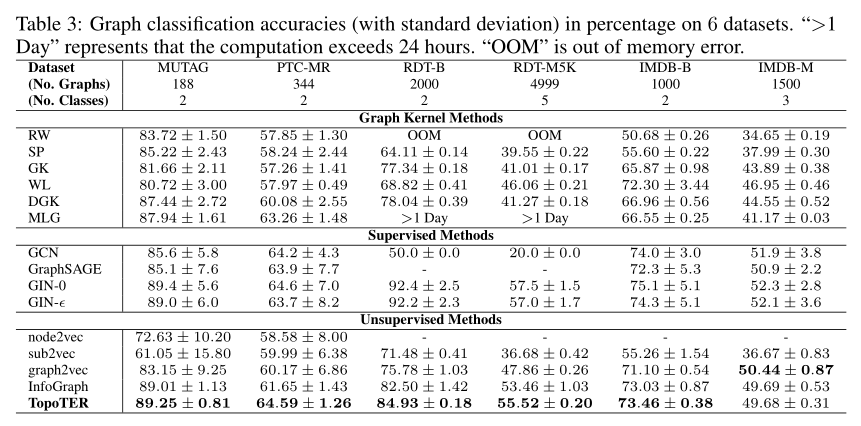
在图分类上与图核方法和监督和无监督方法进行比较.
总结
提出拓扑转换等变表示(TopoTER)来学习图数据的无监督表示。通过最大化拓扑转换和转换前后特征表示之间的相互信息,TopoTER强制编码器学习内在的图特征表示,这些特征表示包含关于应用拓扑转换下结构的足够信息

 浙公网安备 33010602011771号
浙公网安备 33010602011771号