人工智能实战_团队展示
作业要求
| 标题 | 内容 |
|---|---|
| 这个作业属于哪个课程 | 班级博客的链接 |
| 这个作业的要求在哪里 | 作业要求的链接 |
| 我在这个课程的目标是 | 完成一个完整的项目,学以致用 |
| 这个作业在哪个具体方面帮助我实现目标 | 展示博客 |
一、事后诸葛亮会议
大多数学校的软件工程会议都是一些诺言'我们还会继续开发的',然后跑没影子。
引自构建之法
会议核心是:如果你可以重新来过,什么方面可以做的更好?为什么?为什么?
项目
(1) 设想与目标
- 我们的软件要解决什么问题?是否定义得很清楚?是否对典型用户和典型场景有清晰的描述?
用户给出上联,程序对出下联;
用户给出图片,给出推荐的场景,用户选择希望的场景,然后生成对联。
定义的清楚,在模型指定的输出范围内,即用户给出选择在模型可预测范围内,定义的算明确。能够识别80种场景,8种情感,90种对象。 - 我们达到目标了么(原计划的功能做到了几个? 按照原计划交付时间交付了么? 原计划达到的用户数量达到了么?)
原计划功能共两个,做了一个半?安装原计划交付时间交付了,虽然很差,也硬着头皮交付了。原计划并没有用户数量,不过给了几个用户尝试,没有做成app,做了一个本地服务器,可以接受用户输出,没有域名,没法做成服务器大家都用。 - 和上一个阶段相比,团队软件工程的质量提高了么? 在什么地方有提高,具体提高了多少,如何衡量的?
这只是第二个阶段,软件工程质量相对第一个有微小的进步,之前无法预测,空想一堆,现在实现了一部分功能。 - 用户量, 用户对重要功能的接受程度和我们事先的预想一致么? 我们离目标更近了么?
实际上预想并没有用户量的打算,打算开发出好玩的程序,给同学们使用,但是当时是有app想法的,但是最后没有实现,我们离目标近了一微小步。 - 有什么经验教训? 如果历史重来一遍, 我们会做什么改进?
对联项目是一个很难的项目,如何处理图片到诗的问题,以及如何让用户选择。我们是缺少从图片到诗的数据集,网络上,实际只有图片到英文到诗的数据集,我们要实现图片到对联的数据集,实际上是难实现了。
我们在tensor2tensor decoder花了很长时间,我们缺少linux系统,我们电脑安装了cuda9.2,cudnn9.2.4, tensorflow1.12.2的windows系统,系统硬件不够,git bash无法导入Anaconda包,用Colab云平台,但是install tensorflow1.4.0需要cuda8,但是如何在虚拟机安装cuda8.0是一个问题,查了很多文献无法查,程序出现了很多问题,开始对linux规则学习花了一定时间。!ls, !cp, !mv, !rm, !echo,pwd等等,之前没有linux基础。后来因为tensorflow版本出了很大的问题,终于完成训练,但是decode编程又出现无法预知的错误,一言难尽。后来我们尝试了新版本的t2t,tensorflow编写,看了很多t2t Problem,Translate源代码,网上教材,一言难尽。。。
现在问自己问题,历史重来一遍
历史重来一遍,我会直接学习T2T最新版本,从源代码部分阅读T2T而不是看各种非现版本的教程,导致各种飘飘所以然!
为什么?因为理论上调用包解决问题是很简单的事情,并觉得没有必要学习T2T源代码知识。
为什么不想学后来又学没学好?学了很多杂七杂八版本错误的T2T内容。
为什么不敢学?T2T transformer用到了很多机制Attention,Bert,现阶段并没有对这块NLP内容有一定理解?
为什么对NLP没有一定理解要选对联项目?因为觉得MNIST太简单了,没有想到MNIST可以做challenge的算式识别。
为什么没有向老师取得数据集? 因为没有考虑到如何从对象出诗。为什么不问助教?之前问了几个助教较为简单的问题,后续不好意思了,如果有数据集,至少可以考虑Google models:Show and Tell model进行inference。(无用户选择块)
归根结底:眼高手低,太膨胀了,想做用户选择,不够沉心学习T2T源代码,缺少数据集
(2) 计划
- 是否有充足的时间来做计划?
我们准备了一周半时间正式启动,开始学习,现在看来,时间是不充足的,对预想过程太简单了。
为什么不留充足时间开始?最近连续几周都有考试,时间上比较赶。
为什么有考试就不能做项目?自己不够优秀,不能兼顾考试和项目。
连续两个考试你能不能兼顾?学业还是略微艰难的,考试我也会花不到这个项目的时间复习去做。。。 - 团队在计划阶段是如何解决同事们对于计划的不同意见的?
我们团队很小,其实同学没有不同意见,加油去做。 - 你原计划的工作是否最后都做完了? 如果有没做完的,为什么?
差最后一部分,缺少数据集,归根结底是如何从识别出来的对象,情感,场景出对联是一个问题。 - 有没有发现你做了一些事后看来没必要或没多大价值的事?
没有必要学习以前版本的T2T,既然你无法安装旧版本Tensorflow,cuda,你去改T2T源代码解决tensorflow deprecated问题,终究最后无法实现。 - 是否每一项任务都有清楚定义和衡量的交付件?
其实就几个任务:
上联到下联:可以训练,在测试集评估效果;
图片到对联:首先是对图片object_detection, scene detection, sentiment detection.
再给用户选择,依此出对联。 - 是否项目的整个过程都按照计划进行,项目出了什么意外?有什么风险是当时没有估计到的,为什么没有估计到?
没预估到T2T和Tensorflow兼容出现很大问题,没预估到Windows跑T2T出现很大的问题,git bash里面并没有python包,意味着我无法再本机实现。没预估到如何从识别出来的对象,场景,情感出对联,开始想着用检索的方式,但是实际上,我们识别出来的对象是现代的事物,识别出的场景是现代的场景,与数据集不符合!! - 在计划中有没有留下缓冲区,缓冲区有作用么?
- 将来的计划会做什么修改?(例如:缓冲区的定义,加班)
我们学到了什么? 如果历史重来一遍, 我们会做什么改进?
至少从老师获取数据集,用show and tell model 类似的模型去做img2txt。
(3) 资源
- 我们有足够的资源来完成各项任务么?
我们没用足够的资源,但是可能校园云平台可以用,但是由于校园云平台以后用不到了,就只在Colab解决出现的各种问题。 - 各项任务所需的时间和其他资源是如何估计的,精度如何?
各项任务所需时间,我们是打算完成对联任务,资源就是Colab,本机进行本地代码编写,精度上,ssd-mobilenet: COCO-mAP 32, scene-detection:AI Challenger 2017,top-3 acc:94.346% - 测试的时间,人力和软件/硬件资源是否足够? 对于那些不需要编程的资源 (美工设计/文案)是否低估难度?
- 你有没有感到你做的事情可以让别人来做(更有效率)?
有什么经验教训? 如果历史重来一遍, 我们会做什么改进?
数据集,可能可以尝试其他的资源,多问
二、效果展示
- 对于对联项目:做了一个本地服务器
现在对微软对联和网上项目,我们对联进行对比:
| 上联 |我们下联|微软下联|target|
| ----------- | ----------- |----------- |----------- |
| 今日失梦想成咸鱼 |来年与青春结伴鸾|昔年有青春在夕阳 |
| 上海自来水来自海上|中山落叶松叶落山中|中国出人才人出国中|
| 风弦未拨心先乱 |雨箭初射意未休|燕市空对月时闲|夜幕已沉梦更闲|
| 花梦粘于春袖口 |诗情叠动柳裙头|雨声入吴月诗心|莺声溅落柳枝头|
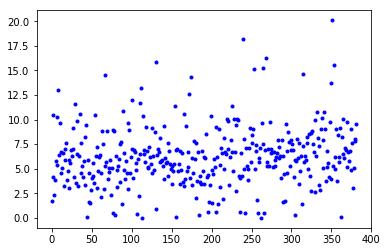
|天古天今,地中地外,古今中外存天地|风狂雨骤,云外云中,风月山川入画图|None|湖南湖北 ,山东山西 ,南北东西有湖山| - 损失曲线
我们现在使用cross_entropy进行分析,我们之前考虑的损失问题,看T2T文档,每次loss的分析实际上是针对一个batch分析,但是不同诗的loss差距很大,所以看上去损失不收敛。
![]()
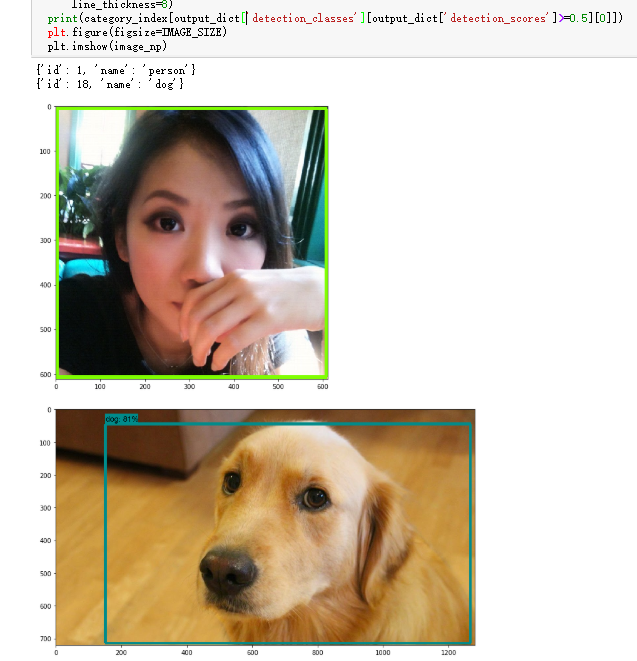
- 对于对象识别项目,我们对随机取两张图识别对象,
![]()

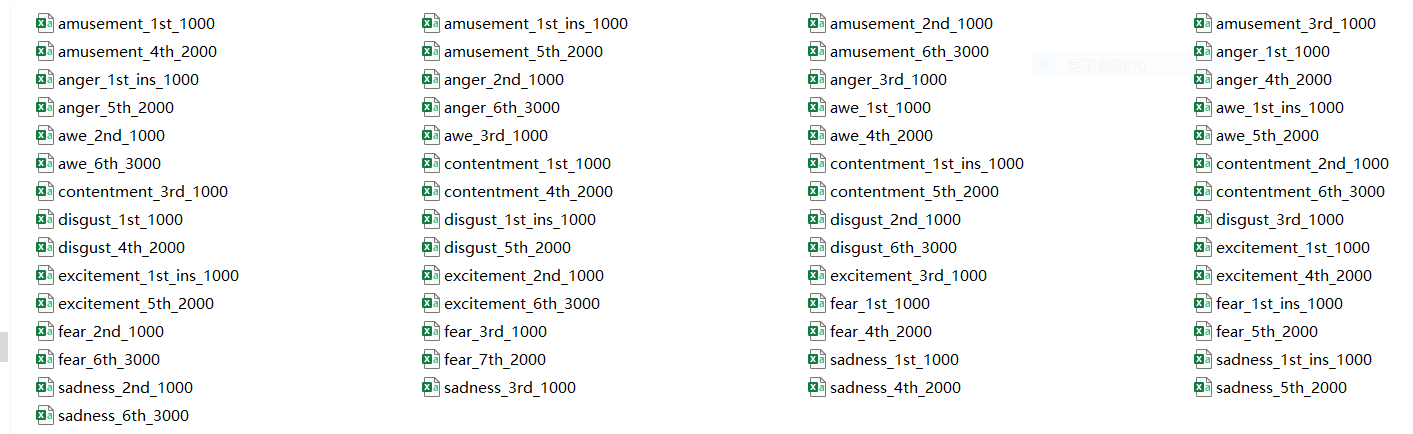
还有收集的数据集,包含情感amusement, anger, awe, contentment, disgust, excitement, fear ,sadness
第三种情感分析由于最终不知道如何生成对联就没有训练,实际上,训练一个分类模型,pretrained in imagenet ,freeze lower layer还是比较容易的。。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号