

DINOv2
(一)data processing
1.1 对uncurated data进行去重
copy detection pipeline - "A Self-Supervised Descriptor for Image Copy Detection" 简称方法SSCD,是基于SimCLR的改进
使用SSCD方法对图片抽取embedding,然后进行K-NN聚类(K=64),只保留其中一张 =》744M
2.1 检索,增加新数据,提高数据多样性
sample based similarity
适用于精选数据集中比较大的数据集,以精选数据集的每个图片为query,选取超过阈值的与之最相似的k个(k=4和32)uncurated的图片
cluster based simlarity
适用于适用于精选数据集中比较小的数据集,将未整理的数据基于k-means聚类成10w个不同聚类,并从每个聚类中抽取10,000张与精选数据集中样本图像相似的,然后丢弃其余部分。
最终LVD-142M
(二)training
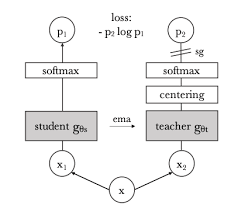
2.1 image-level objective
student 模型输出的embedding和teacher 模型输出的embedding之间的cross entropy loss
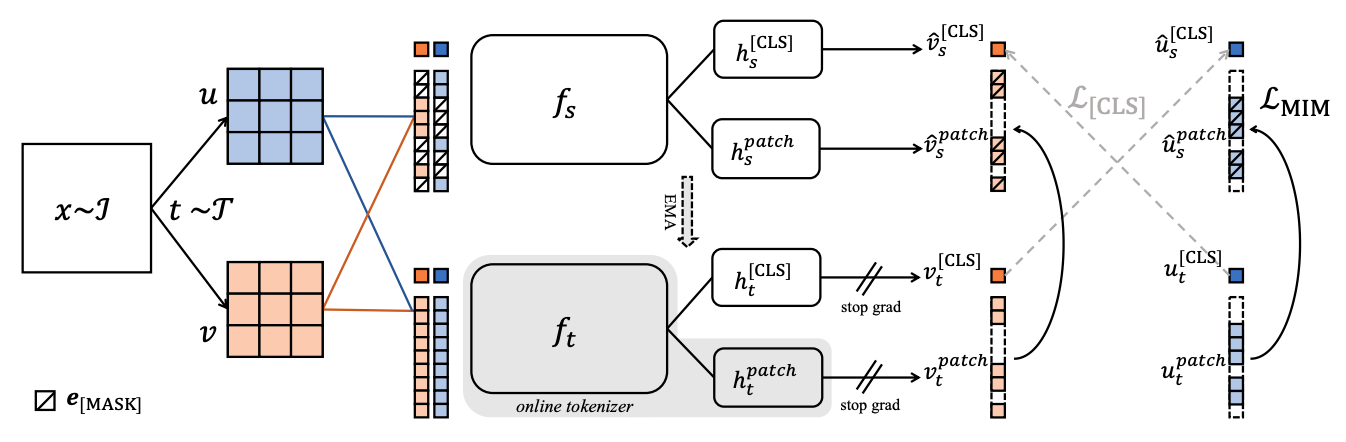
2.2 patch-level objective(来自iBot)
cross-view tokens loss + masked image modelling loss(重建被masked的patch损失)
2.3 Koleo regularization
2.4 518*518
https://blog.csdn.net/qq_51659249/article/details/142699887

 浙公网安备 33010602011771号
浙公网安备 33010602011771号