
scrapy批量获取小说书籍详情信息
![]() 先通过这张图来简单回顾一下Scrapy的工作原理。
先通过这张图来简单回顾一下Scrapy的工作原理。
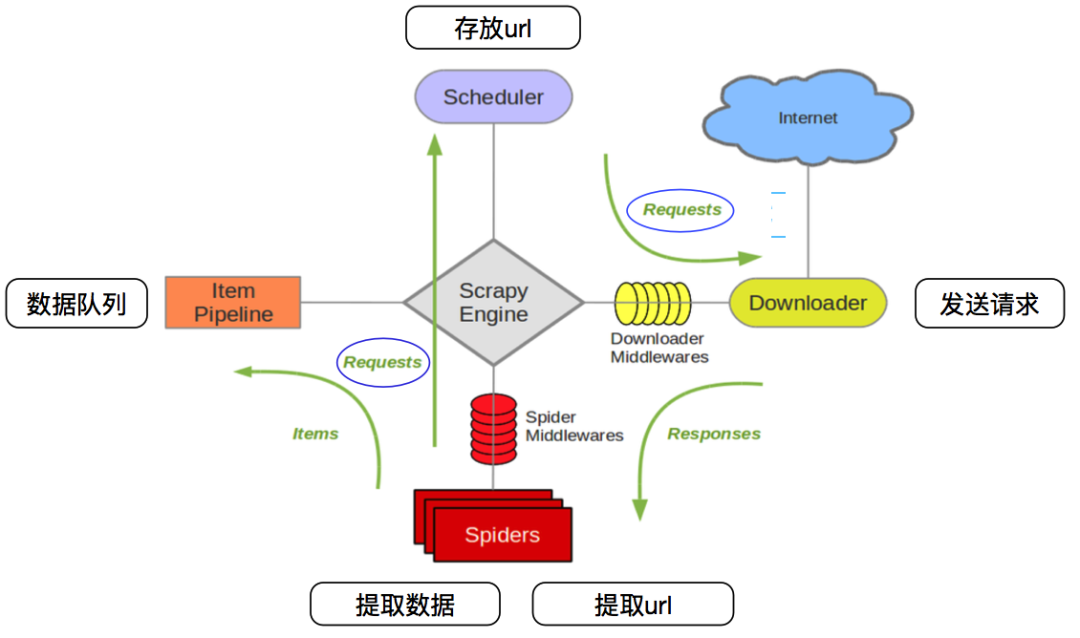
引擎(Scrapy Engine): 用来处理整个系统的数据流处理, 触发事务(框架核心),可以类比为指挥部。
调度器(Scheduler): 用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回。 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址。
下载器(Downloader): 用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的)
爬虫(Spiders): 主要是解析页面信息, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面
项目管道(Pipeline): 负责处理爬虫从网页中抽取的实体,一般是持久化实体或者清理不需要的信息。
下载器中间件(Downloader Middlewares): 位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。
爬虫中间件(Spider Middlewares): 介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出。
调度中间件(Scheduler Middewares): 介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
1、先创建一个scrapy项目
可以使用cmd命令行或者在pycharm中创建,我这是在pycharm中建立
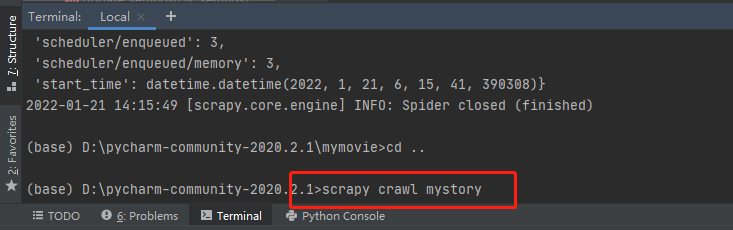
2、生成一个爬虫
通过cd mystory 命令到mystory项目下生成一个爬虫
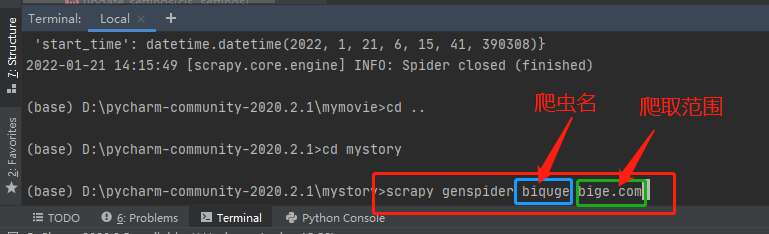
然后。。。你可以看到创建成功的项目文件
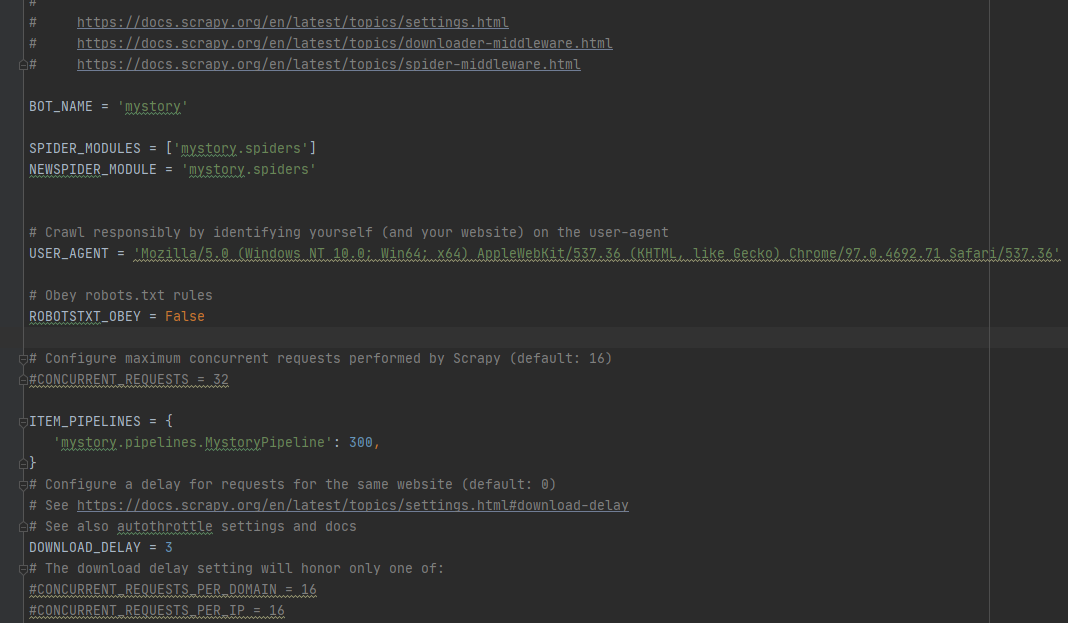
3、setting 配置
USER_AGENT 一定不要进行更改配置,不然很容易被辨别为机器爬虫,可以换成现在正在使用的浏览器的user_agent。
ROBOTSTXT_OBEY 是否遵循机器人(爬虫)协议,默认是TRUE,改为FALSE。
ITEM_PIPELINES 根据项目需要打开一个或多个,数字是优先级,越小优先级越高。
DOWNLOAD_DELAY 控制下爬取速度,频繁快速的访问网站也容易被识别为爬虫。
还有其它的很多其他的,可以根据项目实际需要进行配置,上面这些是比较基础常用的。
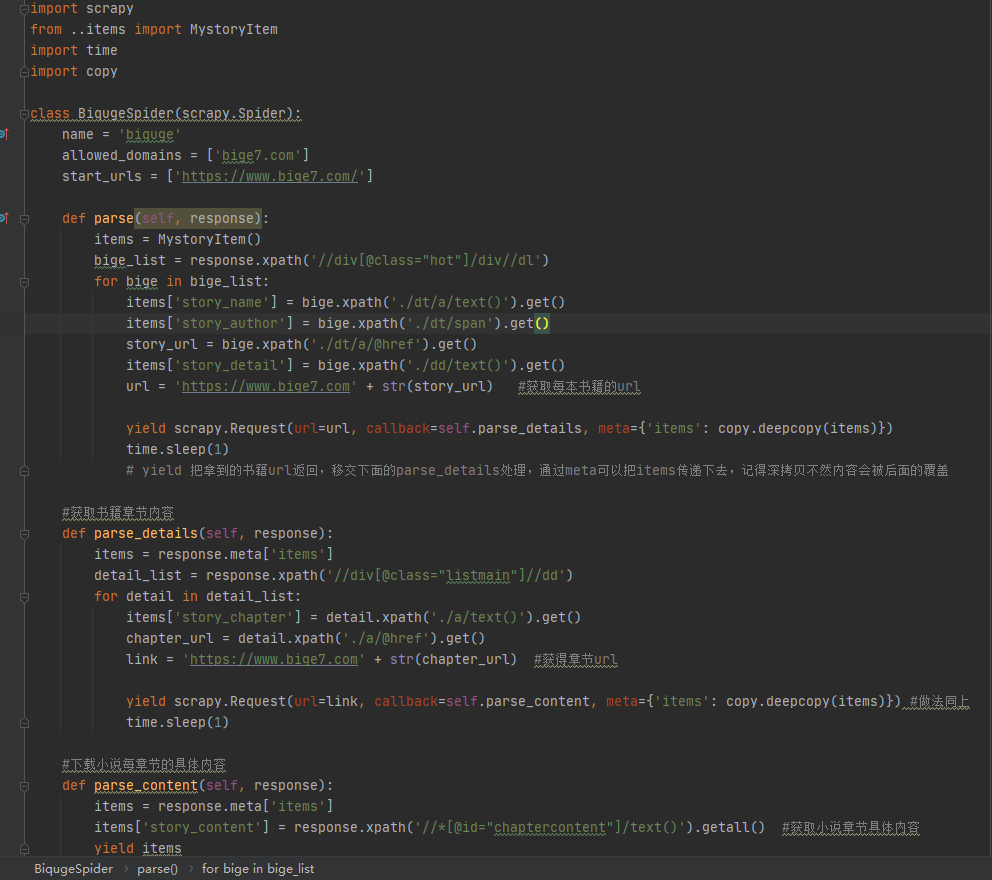
4、爬虫biquge,页面解析
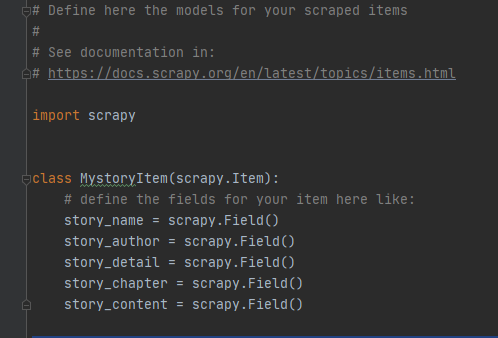
5、items
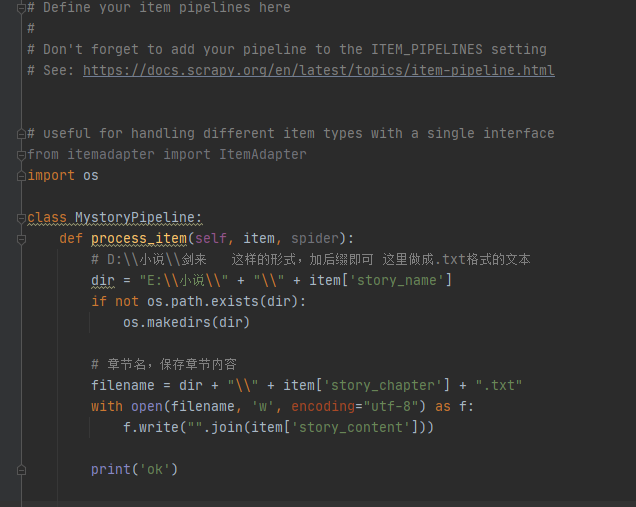
6、pipelines
最后。。。运行
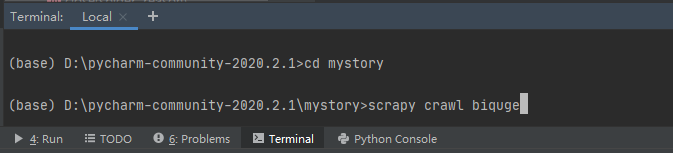
结果展示。。。
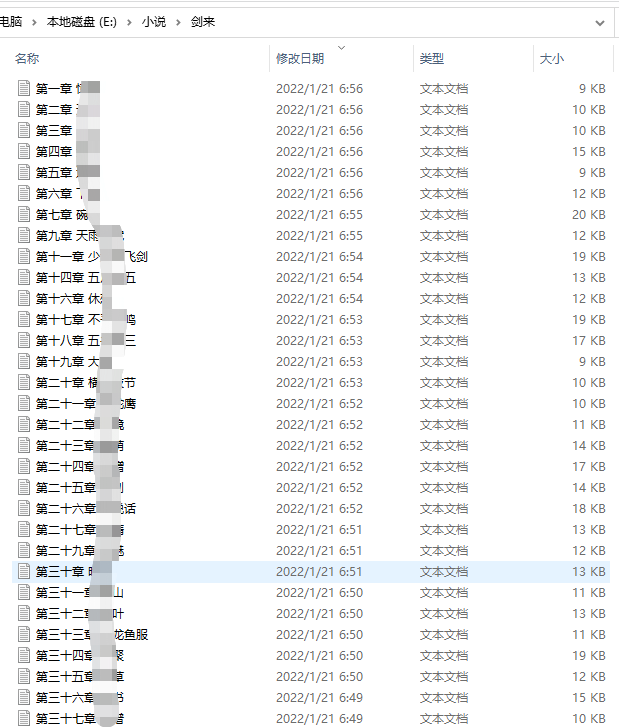
好了,分享就到这啦!如有不对之处也欢迎大家指出交流哦。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号