
FinRL(1)从零开始:深度强化学习在多股票交易中的应用

每天都是刷手机,无所事事,找点事做。
本文将以 FinRL-Tutorials 仓库中的 Stock_NeurIPS2018_SB3.ipynb 为基础,学习如何使用 FinRL 框架和 Stable Baselines3 库来训练多个深度强化学习算法进行股票交易。
这个 Jupyter notebook 实现了一个基于深度强化学习的多股票交易系统,使用 FinRL 框架训练了 5 种不同的 DRL 算法(A2C、DDPG、PPO、TD3、SAC)在道琼斯工业平均指数的30只成分股上进行交易,训练集数据区间为 2010-01-01 到 2021-10-01,交易集数据区间为 2021-10-01 到 2023-03-01,通过 Yahoo Finance 获取历史数据并添加技术指标和风险指标,构建了 291 维状态空间的交易环境,在样本外数据(即交易数据集)上进行回测并与基准策略对比,最终生成交易策略的性能评估和可视化结果。
本文不会涉及该 Jupyter notebook 中所用到的深度强化学习算法的原理及实现细节,仅对 FinRL 的使用及提及的金融术语进行记录。
以下是与该 Jupyter notebook 一致的目录,方便查看。
第 1 部分: 任务说明 (Task Discription)
第 2 部分: 安装软件包 (Install Python Packages)
第 3 部分: 下载数据 (Download Data)
第 4 部分: 数据预处理 (Preprocess Data)
第 5 部分: 构建 OpenAI Gym 风格的市场环境 (Build Market Environment in OpenAI Gym-style)
第 6 部分: 训练深度强化学习智能体 (Train DRL Agents)
第 7 部分: 回测结果分析 (Backtesting Results)
第 1 部分: 任务说明 (Task Discription)
首先说明本 jupyter 笔记的目标:
-
使用深度强化学习训练股票交易智能体
-
将股票交易建模为马尔可夫决策过程(MDP)
-
目标函数是最大化累积收益
-
使用道琼斯工业平均指数(DJIA)的30只成分股作为交易标的
DJIA(Dow Jones Industrial Average):道琼斯工业平均指数,是美国历史最悠久的股价指数之一,通常被视为衡量美国股市整体表现的重要指标,其 30 只成分股多为美国知名大型企业。
其中,与深度强化学习算法相关的元素:
-
状态\(s\):状态空间代表智能体对市场环境的感知。就像人类交易者分析各类信息一样,智能体被动观察多种特征,并通过与市场环境交互(通常是回放历史数据)进行学习。具体的状态空间包括现金、持仓、技术指标等,后续会详细介绍。
-
动作\(a\):动作空间包含智能体在每个状态下可执行的允许动作。例如,动作集合可表示为 \(a ∈ {−1, 0, 1}\),其中−1、0、1分别代表卖出、持有和买入。当动作涉及多股操作时,动作集合则为 \(a ∈{−k, ..., −1, 0, 1, ..., k}\),例如“买入10股苹果公司(AAPL)股票”或“卖出10股苹果公司(AAPL)股票”,对应的动作值分别为10和−10。
-
奖励函数 \(r(s, a, s′)\):奖励是激励智能体学习更优策略的机制。例如,奖励可定义为智能体在状态 \(s\) 下执行动作 \(a\) 并到达新状态 \(s′\) 时,投资组合价值的变化量,即 \(r(s, a, s′) = v′ − v\),其中 \(v′\) 和 \(v\) 分别代表智能体在状态 \(s′\) 和状态 \(s\) 下的投资组合价值。
第 2 部分: 安装软件包 (Install Python Packages)
这一小节指导用户安装必要的库,注意:如果是在本地运行,需要将 condacolab 相关的代码注释掉。
## install required packages
!pip install swig
!pip install wrds
!pip install pyportfolioopt
## install finrl library
!pip install -q condacolab # 若本地运行,注释掉此行代码
import condacolab # 若本地运行,注释掉此行代码
condacolab.install() # 若本地运行,注释掉此行代码
!apt-get update -y -qq && apt-get install -y -qq cmake libopenmpi-dev python3-dev zlib1g-dev libgl1-mesa-glx swig
!pip install git+https://github.com/AI4Finance-Foundation/FinRL.git # FinRL 若安装失败,可以下载源码后自行安装
第 3 部分: 下载数据 (Download Data)
如这篇文章所述,通过 Yahoo Finance API 下载数据需要梯子并设置代理。
下载的数据被存放在df这个 DataFrame 变量中。
# 配置代理
import os
proxy = 'http://127.0.0.1:7890'
os.environ['HTTP_PROXY'] = proxy
os.environ['HTTPS_PROXY'] = proxy
df = YahooDownloader(start_date = TRAIN_START_DATE,
end_date = TRADE_END_DATE,
ticker_list = config_tickers.DOW_30_TICKER).fetch_data()
让我们看看df的形状:
df.shape
(97013, 8)
按照data和tic列对df进行重新排序,然后查看前5行数据。
df.sort_values(['date','tic'],ignore_index=True).head()
| date | open | high | low | close | volume | tic | day | |
|---|---|---|---|---|---|---|---|---|
| 0 | 2010-01-04 | 7.6225 | 7.66071 | 7.585 | 6.50528 | 493729600 | AAPL | 0 |
| 1 | 2010-01-04 | 56.630001 | 57.869999 | 56.560001 | 42.888943 | 5277400 | AMGN | 0 |
| 2 | 2010-01-04 | 40.810001 | 41.099998 | 40.389999 | 33.675961 | 6894300 | AXP | 0 |
| 3 | 2010-01-04 | 55.720001 | 56.389999 | 54.799999 | 43.777538 | 6186700 | BA | 0 |
| 4 | 2010-01-04 | 57.650002 | 59.189999 | 57.509998 | 41.156910 | 7325600 | CAT | 0 |
其中,表格中各列的含义如下:
-
date
表示交易日期,格式为“年-月-日”。例如表格中的“2010-01-04”即2010年1月4日,是记录的交易发生日期。 -
open
表示该股票在当日的开盘价,即交易日开始时的第一笔成交价格。例如第一行的“7.622500”是AAPL股票在2010年1月4日的开盘价。 -
high
表示该股票在当日的最高价,即交易日内出现的最高成交价格。例如第二行的“57.869999”是AMGN股票在当日的最高成交价。 -
low
表示该股票在当日的最低价,即交易日内出现的最低成交价格。例如第三行的“40.389999”是AXP股票在当日的最低成交价。 -
close
表示该股票在当日的收盘价,即交易日结束时的最后一笔成交价格(未复权),是衡量当日股价表现的重要指标。 -
volume
表示该股票在当日的成交量,即全天的交易总股数。例如第一行的“493729600”表示AAPL股票在当日成交了4.93亿多股。 -
tic
表示股票代码(ticker symbol),是识别上市公司的唯一标识。例如“AAPL”是苹果公司的股票代码,“BA”是波音公司的股票代码。 -
day
表示星期几的标识,以0表示周一,6表示周日。
第 4 部分: 数据预处理 (Preprocess Data)
这一小节对下载得到的数据进行预处理,也就是特征工程。处理过后的数据存放在processed_full中。
processed_full.sort_values(['date','tic'],ignore_index=True).head(10)
代码解释:
sort_values(['date','tic']): 按照日期(date)和股票代码(tic)进行排序ignore_index=True: 重新生成索引,忽略原来的索引head(10): 只显示前10行数据
| date | tic | open | high | low | close | volume | day | macd | boll_ub | boll_lb | rsi_30 | cci_30 | dx_30 | close_30_sma | close_60_sma | vix | turbulence | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2010-01-04 | AAPL | 7.6225 | 7.66071 | 7.585 | 6.50528 | 493729600 | 0 | 0 | 6.526809 | 6.494997 | 100 | 66.666667 | 100 | 6.50528 | 6.50528 | 20.040001 | 0 |
| 1 | 2010-01-04 | AMGN | 56.630001 | 57.869999 | 56.560001 | 42.888943 | 5277400 | 0 | 0 | 6.526809 | 6.494997 | 100 | 66.666667 | 100 | 42.888943 | 42.888943 | 20.040001 | 0 |
| 2 | 2010-01-04 | AXP | 40.810001 | 41.099998 | 40.389999 | 33.675961 | 6894300 | 0 | 0 | 6.526809 | 6.494997 | 100 | 66.666667 | 100 | 33.675961 | 33.675961 | 20.040001 | 0 |
| 3 | 2010-01-04 | BA | 55.720001 | 56.389999 | 54.799999 | 43.777538 | 6186700 | 0 | 0 | 6.526809 | 6.494997 | 100 | 66.666667 | 100 | 43.777538 | 43.777538 | 20.040001 | 0 |
| ... |
上述表格中,除了原始数据中所包含的开盘价、最高价、最低价、收盘价(即 OHLC 价格数据)及成交量信息之外,预处理还基于原始数据,计算得到以下用于量化分析的技术指标列:
-
macd
指数平滑异同平均线(Moving Average Convergence Divergence),通过计算短期与长期指数移动平均线的差值,反映价格趋势的强弱和转折信号。 -
boll_ub
布林带上限(Bollinger Band Upper Bound),布林带由三条线组成,上限为中轨(通常是20日移动平均线)加上2倍标准差,用于判断股价是否处于超买[1]区间。 -
boll_lb
布林带下限(Bollinger Band Lower Bound),为中轨减去2倍标准差,用于判断股价是否处于超卖[2]区间。 -
rsi_30
30日相对强弱指数(Relative Strength Index),通过比较近30天内股价上涨和下跌的幅度,衡量资产的超买(通常>70)或超卖(通常<30)状态,取值范围0-100。 -
cci_30
30日商品通道指数(Commodity Channel Index),用于判断股价是否偏离其正常波动范围,超过100视为超买,低于-100视为超卖。 -
dx_30
30日动向指数(Directional Movement Index),衡量价格趋势的强度,取值范围0-100,数值越高表示趋势越强。 -
close_30_sma
30日收盘价简单移动平均线(30-day Simple Moving Average),指近30个交易日收盘价的算术平均值,用于平滑短期波动,识别中长期趋势。 -
close_60_sma
60日收盘价简单移动平均线,逻辑同30日SMA,但周期更长,反映更长期的趋势。 -
vix
波动率指数(Volatility Index),通常指标普500波动率指数,反映市场对未来30天的预期波动率,数值越高表示市场恐慌情绪越强。 -
turbulence
湍流指数,衡量资产价格的极端波动情况,用于识别市场危机或剧烈震荡时期(如2008年金融危机),辅助风险控制。
接下来,为后续的均值方差优化(Mean Variance Optimization, MVO)准备数据。
vo_df = processed_full.sort_values(['date','tic'],ignore_index=True)[['date','tic','close']]
代码解释:
[['date','tic','close']]: 只选择三列数据 - 日期、股票代码和收盘价- 将结果赋值给新变量
mvo_df
为什么MVO只需要这三列?
在均值方差优化中,只需要:
- date: 时间序列信息
- tic: 股票标识符
- close: 收盘价,用于计算收益率和构建投资组合
其他技术指标(如MACD、RSI等)在MVO中不需要,因为MVO是基于历史价格数据计算最优权重分配的传统投资组合优化方法,而深度强化学习算法会使用更多的技术指标作为状态特征。
第 5 部分: 构建 OpenAI Gym 风格的市场环境 (Build Market Environment in OpenAI Gym-style)
使用data_split函数将完整的数据集processed_full按照时间范围分割成两个子集:
- 训练集 (train): 从 TRAIN_START_DATE 到 TRAIN_END_DATE 的数据,包含 85,753 行数据。
- 交易集 (trade): 从 TRADE_START_DATE 到 TRADE_END_DATE 的数据,包含 10,237 行数据。
train = data_split(processed_full, TRAIN_START_DATE,TRAIN_END_DATE)
trade = data_split(processed_full, TRADE_START_DATE,TRADE_END_DATE)
接下来计算状态空间:
stock_dimension = len(train.tic.unique())
state_space = 1 + 2*stock_dimension + len(INDICATORS)*stock_dimension
print(f"Stock Dimension: {stock_dimension}, State Space: {state_space}")
Stock Dimension: 29, State Space: 291
-
上述的打印输出中,为什么只有29只股票,而不是30只呢?
这是因为,DJIX中的DOW作为独立公司是在2019年4月从陶氏杜邦分拆出来的,它没有2010-2019年的历史数据,所以,它在训练数据分割时被合理过滤掉,因为DOW在训练期间还不存在。 -
1 + 2stock_dimension + len(INDICATORS)stock_dimension
-
1- 现金余额
表示智能体当前持有的现金数量,用于跟踪可用资金。 -
2*stock_dimension- 持仓信息stock_dimension= 29(29只股票)- 包含两部分信息:
- 当前持仓数量:每只股票的持有股数
- 持仓价值:每只股票的当前市值
所以是 2 × 29 = 58 维
-
len(INDICATORS)*stock_dimension- 技术指标len(INDICATORS):技术指标的数量,本文件中是8:['macd', 'boll_ub', 'boll_lb', 'rsi_30', 'cci_30', 'dx_30', 'close_30_sma', 'close_60_sma']- 每个技术指标对每只股票都计算一次
所以是 技术指标数量 8 × 29 维
所以,状态空间的维数是:
state_space= 1 + 229 + 829
= 1 + 58 + 232
= 291 维 -
接下来,使用StockTradingEnv函数创建环境:
e_train_gym = StockTradingEnv(df = train, **env_kwargs)
将FinRL的 StockTradingEnv 环境转换为Stable Baselines3兼容的环境格式:
env_train, _ = e_train_gym.get_sb_env()
print(type(env_train))
<class 'stable_baselines3.common.vec_env.dummy_vec_env.DummyVecEnv'>
为什么需要转换?
因为 FinRL的 StockTradingEnv 是基于OpenAI Gym 的,而使用 Stable Baselines3 需要特定的环境格式,在转换之后可以无缝使用SB3的算法进行训练。如果没有这个转换,就无法使用Stable Baselines3的强化学习算法进行训练。
第 6 部分: 训练深度强化学习智能体 (Train DRL Agents)
# 1. 创建智能体管理器
agent = DRLAgent(env = env_train)
# 2. 获取A2C模型
model_a2c = agent.get_model("a2c")
# 3. 训练A2C模型
trained_a2c = agent.train_model(model=model_a2c,
tb_log_name='a2c',
total_timesteps=50000)
其中,
DRLAgent是FinRL框架中的核心类,它用于统一管理多种强化学习算法,提供标准化的接口来创建和训练不同的模型。DRLAgent中的get_model("a2c")方法用于获取指定的A2C算法模型,该模型使用Stable Baselines3的A2C实现。DRLAgent中的train_model()方法用于训练模型。
接下来,又依次创建了 DDPG、PPO、TD3 和 SAC 算法模型,并进行训练。
在训练完成之后,再往后就是使用智能体进行交易了。不过,在交易之前,还有两个名词需要了解。
-
vix
VIX(Volatility Index)波动率指数,也被称为"恐慌指数"。它被用来衡量市场对未来30天波动率的预期,数值越高表示市场越恐慌/波动。 -
turbulence
湍流指数:衡量市场极端波动的指标,它基于多只股票的价格波动计算得出。数值越高表示市场波动越极端,用于识别市场危机或异常波动时期。
vix 和 turbulence对比如下表所示:
| 指标 | VIX | 湍流指数 |
|---|---|---|
| 计算基础 | 期权隐含波动率 | 多股票价格波动 |
| 预测性 | 未来30天预期 | 当前市场状态 |
| 覆盖范围 | 标普500 | 投资组合中的股票 |
| 用途 | 市场恐慌程度 | 投资组合风险 |
介绍这两个指标,主要是因为在创建交易环境时需要用到它们俩。
# 创建一个用于回测的交易环境,用于测试训练好的模型在样本外数据上的表现。当市场湍流指数超过70时,认为市场处于极端波动状态,指定使用VIX指数作为风险指标
e_trade_gym = StockTradingEnv(df = trade, turbulence_threshold = 70,risk_indicator_col='vix', **env_kwargs)
# 这行代码被注释掉了,原本用于将FinRL环境转换为Stable Baselines3格式。在回测阶段,直接使用FinRL环境进行预测,不需要转换为SB3格式,因为不进行训练
# env_trade, obs_trade = e_trade_gym.get_sb_env()
以下表格是训练环境和交易环境的对比:
| 参数 | 训练环境 | 交易环境 |
|---|---|---|
| 数据 | train (2010-2021) | trade (2021-2023) |
| 湍流阈值 | 未设置 | 70 |
| 风险指标 | 未指定 | VIX |
| 用途 | 模型训练 | 模型回测 |
下面的代码使用训练好的A2C模型在交易环境中进行预测,生成交易策略和账户价值变化。
其中,返回的df_account_value_a2c是账户价值变化的时间序列,包含每个交易日的账户总价值,用于计算收益率和性能指标。
df_actions_a2c是每个交易日的交易动作,包含对每只股票的买卖决策,用于分析交易策略。
trained_moedl = trained_a2c
df_account_value_a2c, df_actions_a2c = DRLAgent.DRL_prediction(
model=trained_moedl,
environment = e_trade_gym)
第 6.5 部分: 计算MVO基准
Mean Variance Optimization (MVO),翻译中文为均值方差优化,它作为传统投资组合优化方法的代表,通过数学优化方法找到最优的资产配置权重。
这个小节的目的是提供一个传统方法的对比基准,帮助读者理解深度强化学习在投资组合管理中的优势和特点。
对于这一小节,我们不必深究,只需要知道一点,这里使用MVO作为传统投资组合优化方法的代表,提供了一个对比参照的基准,经过计算,其账户价值变化的时间序列保存在MVO_result变量中。
第 7 部分: 回测结果分析 (Backtesting Results)
第7节是性能评估和对比分析阶段,将5个DRL算法、1个传统MVO和1个基准指数的结果汇总并进行全面的性能分析。
数据整理和标准化:
# 将所有算法的账户价值数据标准化
df_result_a2c = df_account_value_a2c.set_index(df_account_value_a2c.columns[0])
df_result_ddpg = df_account_value_ddpg.set_index(df_account_value_ddpg.columns[0])
df_result_td3 = df_account_value_td3.set_index(df_account_value_td3.columns[0])
df_result_ppo = df_account_value_ppo.set_index(df_account_value_ppo.columns[0])
df_result_sac = df_account_value_sac.set_index(df_account_value_sac.columns[0])
基准对比数据准备:
# 获取道琼斯指数作为基准
df_dji_ = get_baseline(ticker="^DJI", start=TRADE_START_DATE, end=TRADE_END_DATE)
# 计算基准的统计指标
stats = backtest_stats(df_dji_, value_col_name='close')
# 转换为以美元为单位的账户价值: 指数值 / 初始指数值 * 初始资金
df_dji = pd.DataFrame()
df_dji['date'] = df_account_value_a2c['date']
df_dji['account_value'] = df_dji_['close'] / df_dji_['close'][0] * env_kwargs["initial_amount"]
数据合并和对比:
# 将所有策略结果合并到一个DataFrame中
result = pd.merge(df_result_a2c, df_result_ddpg, ...)
result.columns = ['a2c', 'ddpg', 'td3', 'ppo', 'sac', 'mean var', 'dji']
可视化:
# 绘制所有策略的收益曲线对比图
plt.figure()
result.plot()
以下表格列出了各策略:
| 策略 | 类型 | 说明 |
|---|---|---|
| A2C | 强化学习 | Advantage Actor-Critic |
| DDPG | 强化学习 | Deep Deterministic Policy Gradient |
| TD3 | 强化学习 | Twin Delayed Deep Deterministic Policy Gradient |
| PPO | 强化学习 | Proximal Policy Optimization |
| SAC | 强化学习 | Soft Actor-Critic |
| Mean Var | 传统方法 | 均值方差优化 (MVO) |
| DJI | 基准 | 道琼斯工业平均指数 |
绘制的图如下所示,横轴是时间,纵轴是账户价值。初始金额是100万美元。
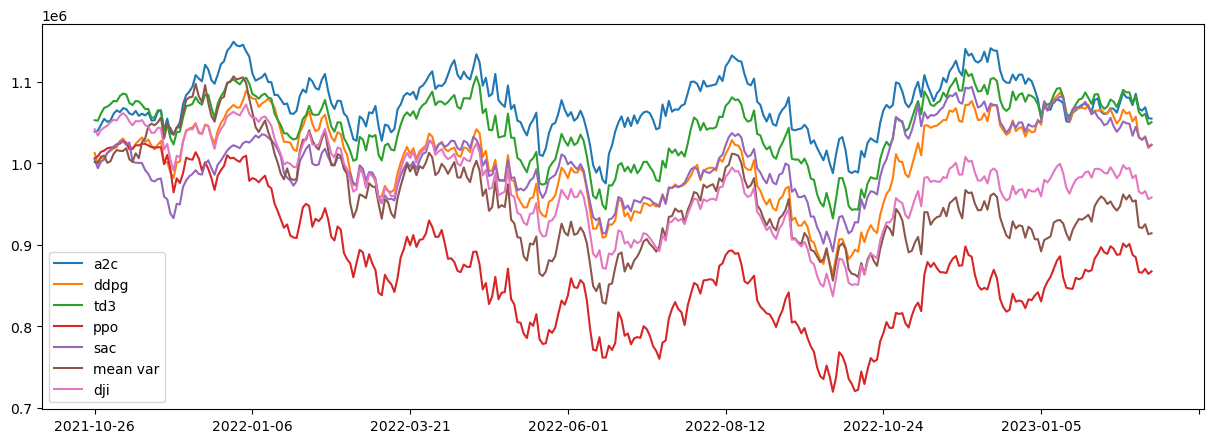
最后,咱来分析一下得到的这张图。
-
时间范围:
- 回测期间:2021年10月1日 - 2023年3月1日
- 市场环境:经历了2022年的市场波动和调整
-
策略表现排名:
-
表现最佳:A2C 和 TD3
- A2C(蓝色线):最终账户价值约110万美元,收益率约10%
- TD3(绿色线):表现与A2C相近,波动性略大
- 特点:在2022年市场下跌中表现相对稳定,反弹能力强
-
表现良好:DDPG 和 SAC
- DDPG(橙色线):最终收益为正,但波动较大
- SAC(紫色线):表现中等,有一定波动性
- 特点:能够跑赢基准,但风险控制有待改进
-
基准表现:DJI
- DJI(粉色线):作为市场基准,最终略高于初始资金
- 特点:代表被动投资的表现,波动相对较小
-
表现不佳:PPO 和 Mean Var
- PPO(红色线):表现最差,最终账户价值约80万美元,亏损约20%
- Mean Var(棕色线):传统MVO方法表现也不理想,最终略低于初始资金
- 问题:在2022年市场波动中损失较大
-
-
关键观察:
-
1. 市场环境影响
- 2022年初-中期:所有策略都经历下跌,反映了市场整体疲软
- 2022年中期-2023年初:市场反弹,但策略表现分化明显
-
2. 风险收益特征
- 高收益策略:A2C、TD3 - 收益高但波动适中
- 中等策略:DDPG、SAC - 收益中等,波动较大
- 低效策略:PPO、Mean Var - 收益低或为负
-
3. 算法特性分析
- Actor-Critic类(A2C):表现稳定,适合股票交易
- Policy Gradient类(PPO):在此任务中表现不佳
- 传统优化(Mean Var):在动态市场中适应性不足
-
-
实际意义:
-
1. 算法选择建议
- 首选:A2C、TD3 - 风险调整收益最优
- 次选:DDPG、SAC - 有一定潜力但需优化
- 避免:PPO - 在此任务中表现不佳
-
2. 投资策略启示
- 主动管理有效:部分DRL策略确实跑赢了市场基准
- 算法差异显著:不同强化学习算法表现差异很大
- 传统方法局限:静态优化在动态市场中适应性不足
-
3. 风险管理
- 波动性控制:需要关注策略的波动性,避免过度风险
- 市场适应性:策略需要能够适应不同的市场环境
-
-
总结:
这张图清楚地展示了:
- 深度强化学习在股票交易中的潜力:A2C和TD3表现优异
- 算法选择的重要性:不同算法表现差异巨大
- 市场环境的影响:2022年的市场波动对所有策略都是考验
- 传统方法的局限性:MVO在动态市场中表现不佳
这为实际应用提供了有价值的参考:选择A2C或TD3算法,并做好风险管理,可能获得优于市场基准的收益。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号