wordcount简单总结
WordCount作业完成情况
项目 WordCount[^stackedit]在经过8个小时的加紧赶工后,做出了一个大概的样子
目录
概述
WordCount的基础功能需求分析大致如下:对程序设计语言源文件统计字符数、单词数、行数,统计结果以指定格式输出到默认文件result.txt中,或者通过指定命令完成在其他目录的其他文件中输出
思路:
- WordCount我由于追求功能单一,在转换为exe时更方便,而编写在一个类里
- 首先利用java读写文件的方便性,导入io包,用BufferReader和BufferWriter方法读写需要的文件
- 之后利用二元树数组特性来统计出现某些特殊条件的个数
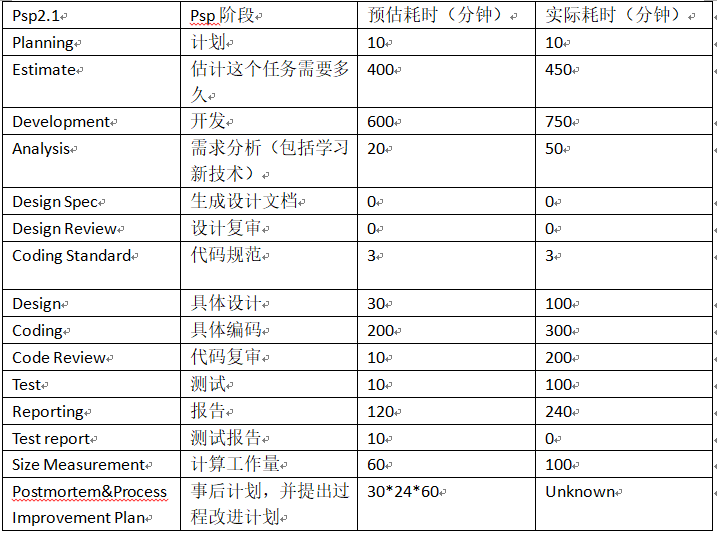
PSP图
初始化和创建流的代码
-import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
import java.util.TreeMap;
import jdk.internal.org.objectweb.asm.tree.IntInsnNode;
public class WordCount{
@SuppressWarnings("resource")
public static void main(String[] args) throws IOException {
String nurl = args[5];//把新url赋初值
String url = args[3];//原url赋初值
BufferedReader bread = new BufferedReader(new FileReader("E:\新建文件夹\something.txt"));//建立读取流
BufferedWriter bw = new BufferedWriter(new FileWriter("E:\新建文件夹\result.txt"));//建立输出流
boolean one;boolean two;boolean three;boolean four;
one=two=three=four=false;//建立四个动作的状态并赋初值
Tip: 参数调用参考 https://blog.csdn.net/zdwssq/article/details/16355057
三个统计方法和一个改变输出的代码
-TreeMap '<'Character, Integer> tm = new TreeMap<>();//使用二元树数组,通过key值和计数值来统计
//当读取流的值不为空时,如果此时键值为空,则计数值为1,并赋予键值,如果不为空,计数值加一并把键值赋予新的节点
int a;
while(( a=bread.read())!=-1) {
if(!tm.containsKey((char)a)) {
tm.put((char)a, 1);
}
else {
tm.put((char)a, tm.get((char)a)+1);
}
}
bread.close();//关闭读取流
方法代码
int i = 1;
//使用if语句判断语句不管在第一第二或第三时都能检测到并改变动作的状态,此时之后的方法就可以使用了
while(i1||i2||i3||i4) {
...
}
i++;
}
int con=0;
//如果状态1是真,则统计代码行数
if(one) {
...
}
}
}
//如果状态2是真,则统计单词数
if(two) {
...
}
}
}
//如果状态3是真,则统计字符数
if(three) {
...
}
}
bw.write("字符数: "+(con-2));
}
bw.close();//关闭写入流
}
}
测试用例

测试结果

其他的情况就不一 一截图了。
gitee网站
[xinz] (https://gitee.com/outmanxp/WorkCount/tree/master)
测试评价
还有很多不足之处,就是因为平时积累的编程经验太少了,导致很多时候在做无用功,如果效率满配的情况下,我觉得我也不会在半夜发这个博客了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号