golang工具:二.PProf性能剖析
应用程序在运行时,总是会出现一些你意想不到的问题,例如:CPU使用率过高,内存不断增大(疑似内存泄露),或者是Goroutine数量不断增加(goroutine泄露)。那么在这些问题出现时如何进行排查呢,这里介绍pprof工具。
pprof是什么
pprof是析性能分析数据的工具,可以生成可视化的文本和图形报告帮助分析程序问题和数据。
基本使用
package main
import (
"net/http"
_ "net/http/pprof" // 会自动注册 handler 到 http server,方便通过 http 接口获取程序运行采样报告
"runtime"
"time"
)
func main() {
runtime.SetMutexProfileFraction(1) // 开启对锁调用的跟踪
runtime.SetBlockProfileRate(1) // 开启对阻塞操作的跟踪
go Loop()
_ = http.ListenAndServe(":9000", nil)
}
func Loop() {
for i := 0; i < 10000000000; i++ {
time.Sleep(time.Microsecond*100)
}
}
这里要在import中添加_ "net/http/pprof"来获取采样报告,然后运行程序,访问http://127.0.0.1:9000/debug/pprof/查看报告。
通过web报告分析
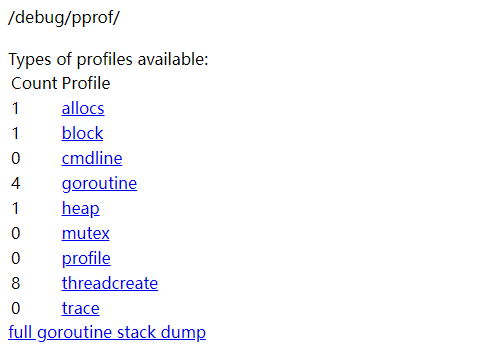
allocs:查看过去所有内存分配的样本。
block:查看导致阻塞同步的堆栈跟踪。
cmdline: 当前程序的命令行的完整调用路径。
goroutine:查看当前所有运行的 goroutines 堆栈跟踪。
heap:查看活动对象(堆)的内存分配情况。
mutex:查看导致互斥锁的竞争持有者的堆栈跟踪。
profile: 默认进行 30s 的 CPU Profiling,得到一个分析用的 profile 文件。
threadcreate:查看创建新 OS 线程的堆栈跟踪。
点击页面的某一项还可以看到更详细的信息
通过互交式终端分析
直接通过命令行,来完成对正在运行的应用程序 pprof 的抓取和分析。
package main
import (
"net/http"
_ "net/http/pprof" // 会自动注册 handler 到 http server,方便通过 http 接口获取程序运行采样报告
"runtime"
"time"
)
func main() {
runtime.SetMutexProfileFraction(1) // 开启对锁调用的跟踪
runtime.SetBlockProfileRate(1) // 开启对阻塞操作的跟踪
go G()
// 这里可以指定监听ip,例如:_ = http.ListenAndServe("127.0.0.1:9000", nil)
_ = http.ListenAndServe(":9000", nil)
}
func G() {
for i := 0; i < 10000; i++ {
go func() {
s := make([]int,1000)
for i := 0; i < 10000; i++ {
s = append(s,i)
time.Sleep(time.Millisecond*500)
}
}()
time.Sleep(time.Millisecond*5)
}
}
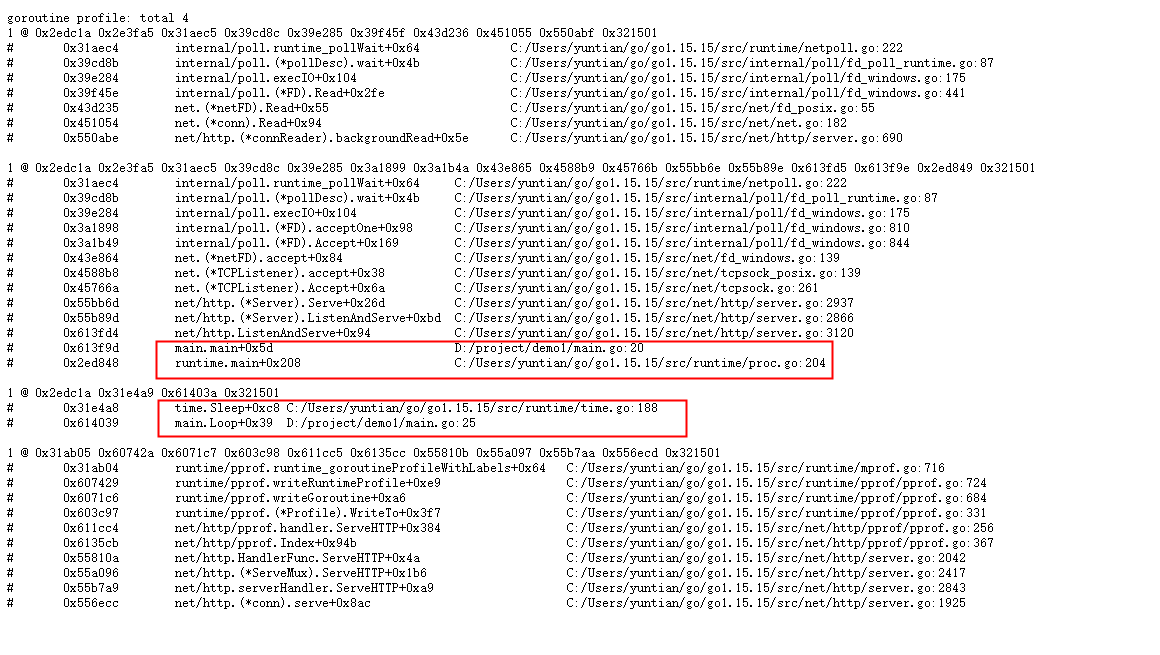
再起一个命令行输入命令:
go tool pprof http://127.0.0.1:9000/debug/pprof/heap?seconds=60
这里的heap可以换成上面的goroutine,profile等任意一个,参数seconds如果不填默认30s。
然后就可以得到互交界面:

上面Saved profile... 这里保持了文件。
Type: inuse_space 分析应用程序的常驻内存占用情况。
这里还可以用命令:o tool pprof -alloc_objects http://127.0.0.1:9000/debug/pprof/heap
(alloc_objects:分析应用程序的内存临时分配情况; inuse_objects:每个函数所分别的对象数量; alloc_space:查看分配的内存空间大小)。
top命令
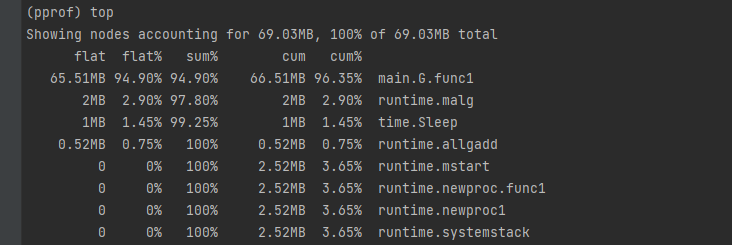
查看内存使用情况,从高到低排序:
- flat:函数自身的运行耗时。
- flat%:函数自身在 CPU 运行耗时总比例。
- sum%:函数自身累积使用 CPU 总比例。
- cum:函数自身及其调用函数的运行总耗时。
- cum%:函数自身及其调用函数的运行耗时总比例。
- 最后一个是函数名。
list+函数名 命令
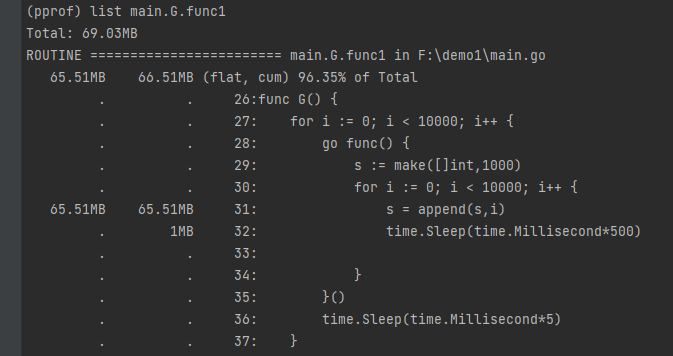
可以具体的看到函数在哪一行消耗的内存。
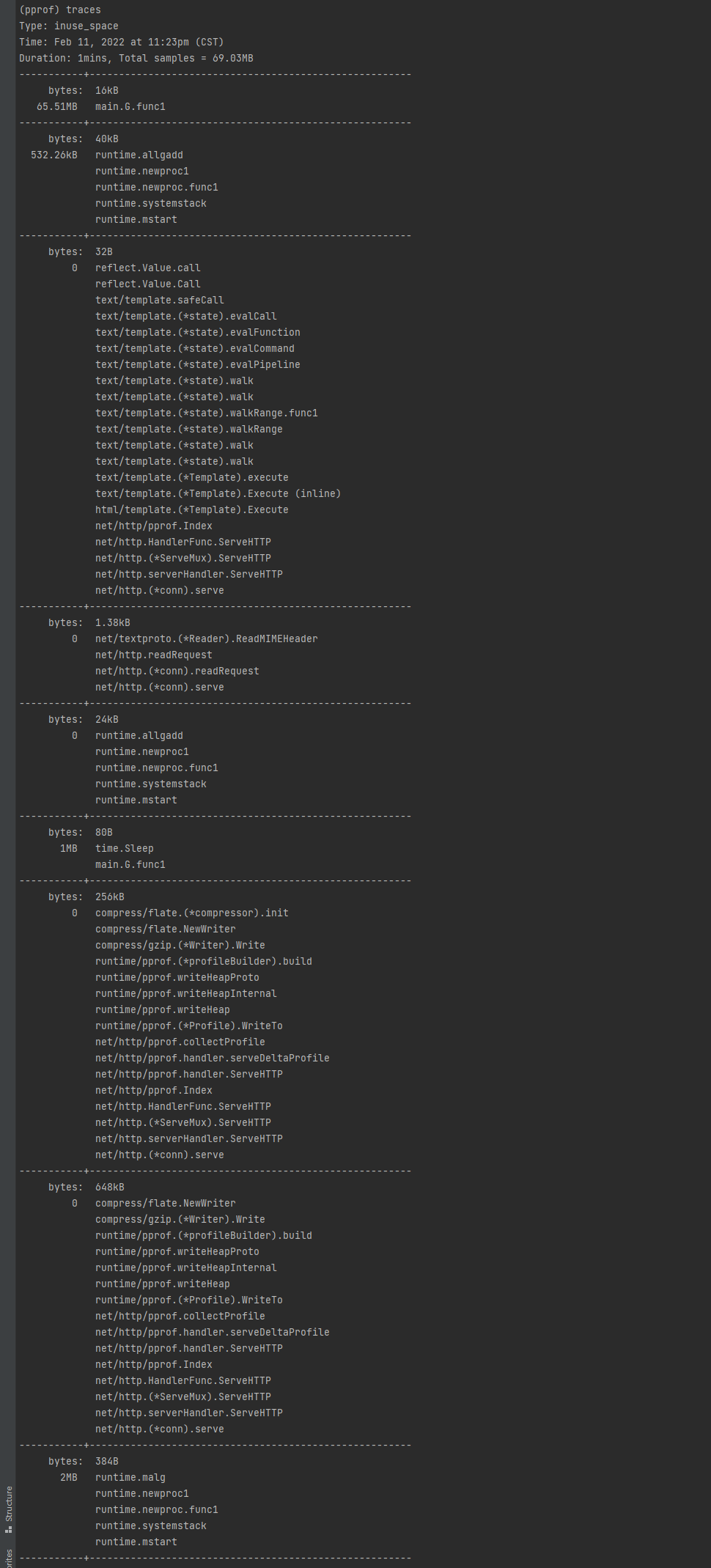
traces 命令
这个命令会打印出对应的所有调用栈,以及指标信息,可以让我们很便捷的查看到整个调用链路有什么,分别在哪里使用了多少个内存。
通过可视化界面分析
直接输入命令:web

提示我们没有安装Graphviz,先去Graphviz官网下载安装,这里可以直接勾选安装环境变量。
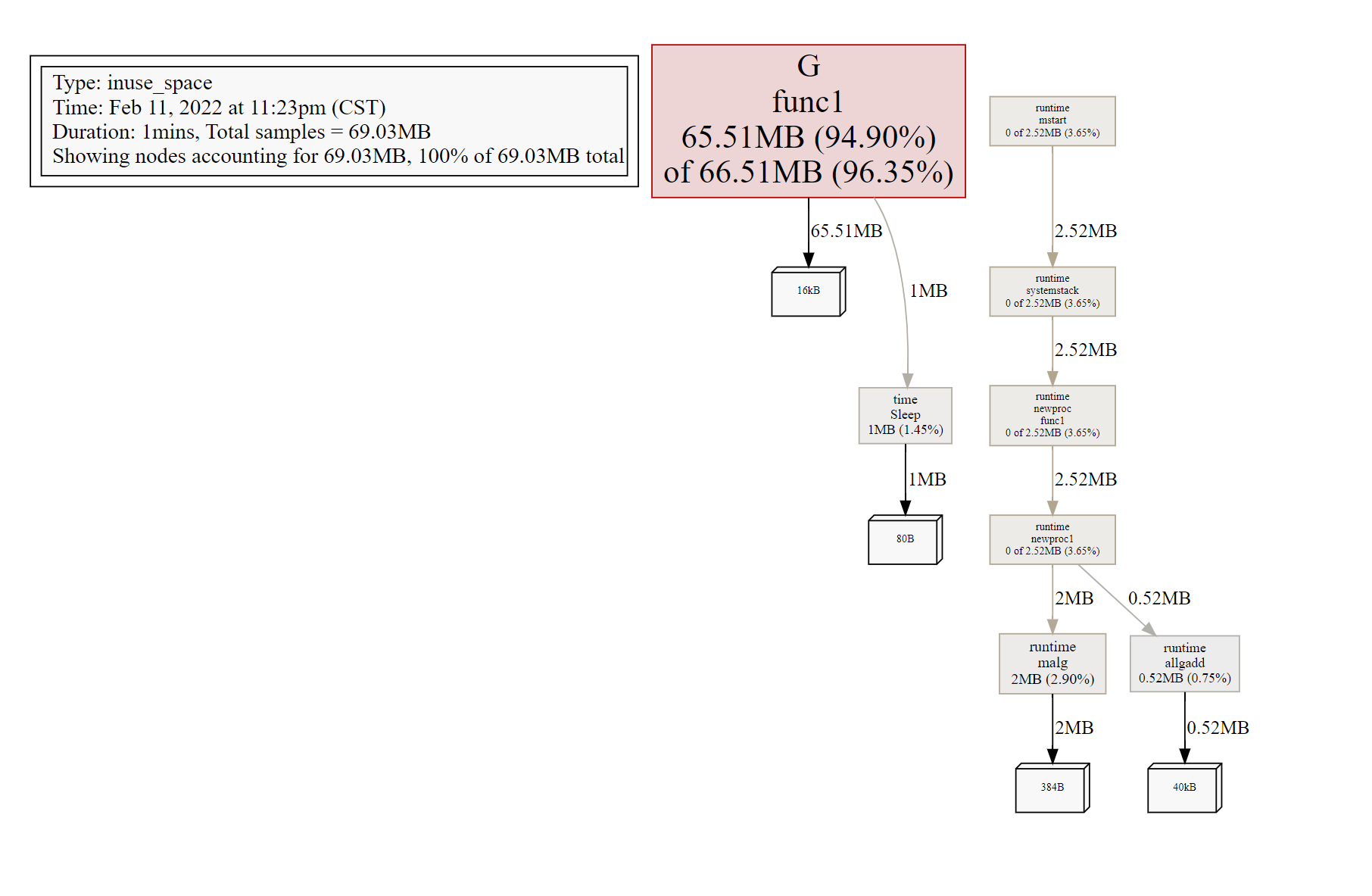
然后再输入web可以看到函数调用的流程图,改图全面整体的展示了函数的调用情况,用线的粗细,颜色表明开销的大小程度,很形象。
如果需要分析goroutine,profile等,和上面的流程一样。pprof对程序的性能优化还是很有利的,它可以快速定位到耗时较多的位置进行优化,而且也支持只打印和某个函数相关的命令,很人性化。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号