
OFtutorial05_basicParallelComputing解析
相较第四章增加了并行运算,多了
createFields.H和system/decomposeParDict两个文件
createFields.H用于定义场操作相关的内容,包括读取场数据
decomposeParDict用于定义并行计算的网格和计算域分割相关的参数
OFtutorial5.C
源码
OpenFOAM的并行计算
将计算域分成数个小计算区域,每个小计算区域都在单独的处理器中进行计算(包括网格、U和p等计算)
头文件
#include "fvCFD.H"
主函数
int main(int argc, char *argv[])
{
头文件
#include "setRootCase.H"
#include "createTime.H"
#include "createMesh.H"
输出当前工作的服务器及网格尺寸
Pstream::myProcNo()是一个在OpenFOAM中用于获取当前处理器编号(即当前处理器在MPI任务中的序号)的函数。
// For a case being run in parallel, the domain is decomposed into several
// processor meshes. Each of them is run in a separate process and holds
// instances of objects like mesh, U or p just as in a single-threaded (serial)
// computation. These will have different sizes, of course, as they hold
// fewer elements than the whole, undecomposed, mesh.
// Pout is a stream to which each processor can write, unlike Info which only
// gets used by the head process (processor0)
Pout << "Hello from processor " << Pstream::myProcNo() << "! I am working on "
<< mesh.C().size() << " cells" << endl;
定义一个标量参数meshVolume
在所有子线程所处理的网格内运行以下代码并输出各自线程上处理的网格的总体积
// To exchange information between processes, special OpenMPI routines need
// to be called.
// This goes over each cell in the subdomain and integrates their volume.
scalar meshVolume(0.);
forAll(mesh.V(),cellI)
meshVolume += mesh.V()[cellI];
// Add the values from all processes together
Pout << "Mesh volume on this processor: " << meshVolume << endl;
对meshVolume进行归约(reduction)操作,输出处理器上总网格体积及网格数量
reduce-归约操作是一种并行计算中的常见操作,用于将多个处理器上的数据合并成一个单一的结果。在这里,sumOp<scalar>()是一个求和操作,指定了要将meshVolume在所有处理器上的值相加。
reduce(meshVolume, sumOp<scalar>());
Info << "Total mesh volume on all processors: " << meshVolume
// Note how the reudction operation may be done in place without defning
// a temporary variable, where appropriate.
<< " over " << returnReduce(mesh.C().size(), sumOp<label>()) << " cells" << endl;
输出网格总体积
Pstream::scatter用于让一个数值在所有线程中传播
// During the reduction stage, different operations may be carried out, summation,
// described by the sumOp template, being one of them.
// Other very useful operations are minOp and maxOp.
// Note how the type
// of the variable must be added to make an instance of the template, here
// this is done by adding <scalar> in front of the brackets.
// Custom reduction operations are easy to implement but need fluency in
// object-oriented programming in OpenFOAM, so we'll skip this for now.
// Spreading a value across all processors is done using a scatter operation.
Pstream::scatter(meshVolume);
Pout << "Mesh volume on this processor is now " << meshVolume << endl;
初始化列表并存储每个处理器的内部面和边界数量
Pstream::nProcs()用以获取处理器的总数,并据此初始化两个List<label>类型的列表nInternalFaces和nBoundaries。通过mesh.Cf().size()获取当前处理器上内部面的数量,并将其存储在nInternalFaces列表中对应当前处理器编号Pstream::myProcNo()的位置;通过mesh.boundary().size()获取当前处理器上边界的数量,并将其存储在nBoundaries列表中对应当前处理器编号的位置。
// It is often useful to check the distribution of something across all
// processors. This may be done using a list, with each element of it
// being written to by only one processor.
List<label> nInternalFaces (Pstream::nProcs()), nBoundaries (Pstream::nProcs());
nInternalFaces[Pstream::myProcNo()] = mesh.Cf().size();
nBoundaries[Pstream::myProcNo()] = mesh.boundary().size();
收集、分发列表的
使用Pstream::gatherList()函数将nInternalFaces和nBoundaries列表从所有处理器收集到主节点上;使用Pstream::scatterList()函数将收集后的列表再次散列到所有处理器上。
// The list may then be gathered on the head node as
Pstream::gatherList(nInternalFaces);
Pstream::gatherList(nBoundaries);
// Scattering a list is also possbile
Pstream::scatterList(nInternalFaces);
Pstream::scatterList(nBoundaries);
输出每个处理器的内部面数量和边界数量
通过if (Pstream::master())检查当前是否在主节点上。如果是,则遍历nInternalFaces和nBoundaries列表并输出每个处理器的内部面数量和边界数量。
// It can also be useful to do things on the head node only
// (in this case this is meaningless since we are using Info, which already
// checks this and executes on the head node).
// Note how the gathered lists hold information for all processors now.
if (Pstream::master())
{
forAll(nInternalFaces,i)
Info << "Processor " << i << " has " << nInternalFaces[i]
<< " internal faces and " << nBoundaries[i] << " boundary patches" << endl;
}
输出每个边界的索引和名称
// As the mesh is decomposed, interfaces between processors are turned
// into patches, meaning each subdomain sees a processor boundary as a
// boundary condition.
forAll(mesh.boundary(),patchI)
Pout << "Patch " << patchI << " named " << mesh.boundary()[patchI].name() << endl;
输出处理器边界的索引和名称
// When looking for processor patches, it is useful to check their type,
// similarly to how one can check if a patch is of empty type
forAll(mesh.boundary(),patchI)
{
const polyPatch& pp = mesh.boundaryMesh()[patchI];
if (isA<processorPolyPatch>(pp))
Pout << "Patch " << patchI << " named " << mesh.boundary()[patchI].name()
<< " is definitely a processor boundary!" << endl;
}
将读取场相关信息的操作写在createFields.H文件中,然后以头文件的方式包含到求解器中
// ---
// this is an example implementation of the code from tutoral 2 which
// has been adjusted to run in parallel. Each difference is highlighted
// as a NOTE.
// It is conventional in OpenFOAM to move large parts of code to separate
// .H files to make the code of the solver itself more readable. This is not
// a standard C++ practice, as header files are normally associated with
// declarations rather than definitions.
// A very common include, apart from the setRootCase, createTime, and createMesh,
// which are generic, is createFields, which is often unique for each solver.
// Here we've moved all of the parts of the code dealing with setting up the fields
// and transport constants into this include file.
#include "createFields.H"
定义参数
// pre-calculate geometric information using field expressions rather than
// cell-by-cell assignment.
const dimensionedVector originVector("x0", dimLength, vector(0.05,0.05,0.005));
volScalarField r (mag(mesh.C()-originVector));
// NOTE: we need to get a global value; convert from dimensionedScalar to scalar
const scalar rFarCell = returnReduce(max(r).value(), maxOp<scalar>());
scalar f (1.);
计算压力场和速度场
压力场
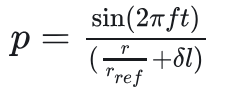
速度场
![]()
Info<< "\nStarting time loop\n" << endl;
while (runTime.loop())
{
Info<< "Time = " << runTime.timeName() << nl << endl;
// assign values to the field;
// sin function expects a dimensionless argument, hence need to convert
// current time using .value().
// r has dimensions of length, hence the small value being added to it
// needs to match that.
// Finally, the result has to match dimensions of pressure, which are
// m^2 / s^-2/
p = Foam::sin(2.*constant::mathematical::pi*f*runTime.time().value())
/ (r/rFarCell + dimensionedScalar("small", dimLength, 1e-12))
* dimensionedScalar("tmp", dimensionSet(0, 3, -2, 0, 0), 1.);
// NOTE: this is needed to update the values on the processor boundaries.
// If this is not done, the gradient operator will get confused around the
// processor patches.
p.correctBoundaryConditions();
// calculate velocity from gradient of pressure
U = fvc::grad(p)*dimensionedScalar("tmp", dimTime, 1.);
runTime.write();
}
Info<< "End\n" << endl;
return 0;
}
小结
相较第四章,该章增加了并行运算
createFields.H
第四章中,运输特性、p、U等参数直接于主文件中定义,该章中将其置于createFields.H头文件中并进行引用
system/decomposeParDict
numberOfSubdomains 4;//将整个模拟区域划分为的子域(或子网格)数量为4
method hierarchical;//指定使用的空间分解或网格划分方法为“层次化”(hierarchical)
hierarchicalCoeffs
{
n (4 1 1);//定义了层次化网格在三个维度(通常是x, y, z)上的分割系数
delta 0.0001;//网格单元的最小尺寸或相邻网格点之间的最小距离
order xyz;//指定了网格划分的顺序或方向
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号