准备本地文本文件
- 首先本地磁盘创建一个
wordcount.txt文件,并且添加以下内容
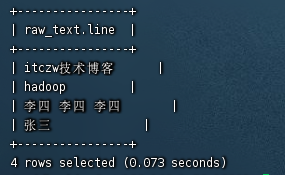
itczw技术博客
hadoop
李四 李四 李四
张三
创建文本表以及载入数据
-- 创建文本表,用于存储需要统计的文本
CREATE TABLE raw_text (line STRING);
-- 将本地的文本文件内容载入hive 文本表,/home/xxxx/wordcount.txt 为 wordcount.txt 所在磁盘路径
LOAD DATA LOCAL INPATH '/home/xxxx/wordcount.txt' INTO TABLE raw_text;
-- 可以通过SQL查看表数据
select * from raw_text;
使用HiveQL实现单词统计
创建结果表
CREATE TABLE word_count (word STRING, count INT);
执行单词统计
INSERT INTO TABLE word_count
SELECT word, COUNT(1) AS count
FROM raw_text
LATERAL VIEW EXPLODE(SPLIT(line, ' ')) lv AS word
GROUP BY word;
查看单词统计结果
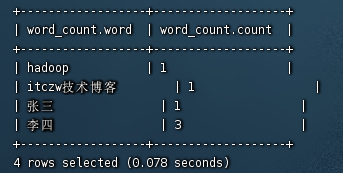
select * from word_count;
通过 INSERT 插入新数据
INSERT INTO TABLE raw_text values('猪刚烈 猪刚烈 美猴王');
重新统计
- 如果还是使用上次的统计SQL,那么
word_count表有保留上次统计的结果,插入新的统计结果,单词统计就会有重复统计,上次统计结果和这次的统计结果
- 如果只想保留最新的统计结果有两种方式,一是清空
word_count表数据再执行统计,二是统计时使用覆盖的方式
方式一
-- 清空word_count表数据
TRUNCATE TABLE word_count;
-- 执行统计
INSERT INTO TABLE word_count
SELECT word, COUNT(1) AS count
FROM raw_text
LATERAL VIEW EXPLODE(SPLIT(line, ' ')) lv AS word
GROUP BY word;
方式二
INSERT OVERWRITE TABLE word_count
SELECT word, COUNT(1) AS count
FROM raw_text
LATERAL VIEW EXPLODE(SPLIT(line, ' ')) lv AS word
GROUP BY word;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号