20180925-3 效能分析
此作业的要求参见:https://edu.cnblogs.com/campus/nenu/2018fall/homework/2145
程序地址:https://git.coding.net/silentteller/wf.git
对上周作业中的功能4 (仅由文件重定向读入,不由控制台读入) 做效能分析,以[https://coding.net/u/younggift/p/word_count_demo/git/blob/master/war_and_peace.txt]为输入数据。
要求0 以 战争与和平 作为输入文件,重读向由文件系统读入。连续三次运行,给出每次消耗时间、CPU参数。 (2分)
进入文件所在目录,打开控制台,输入:
ptime wf -s < war_and_peace.txt
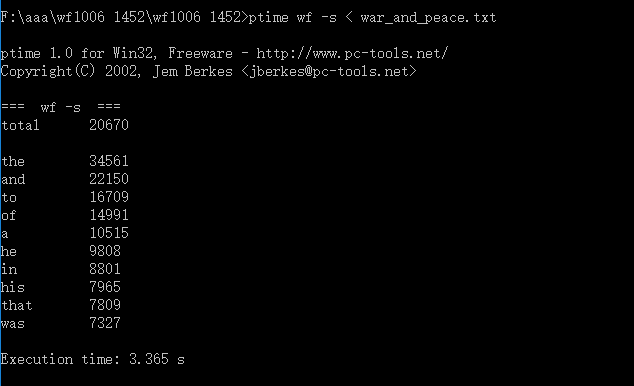
连续三次运行结果如下:
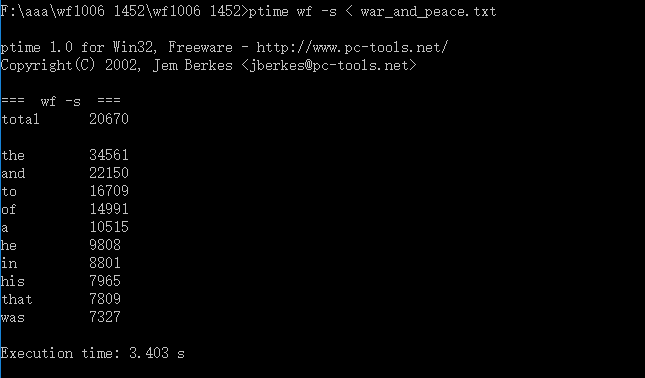

| 运行次数 | 运行时间(s) |
| 第一次 | 3.403 |
| 第二次 | 3.339 |
| 第三次 | 3.365 |
平均时间为:3.369(s)
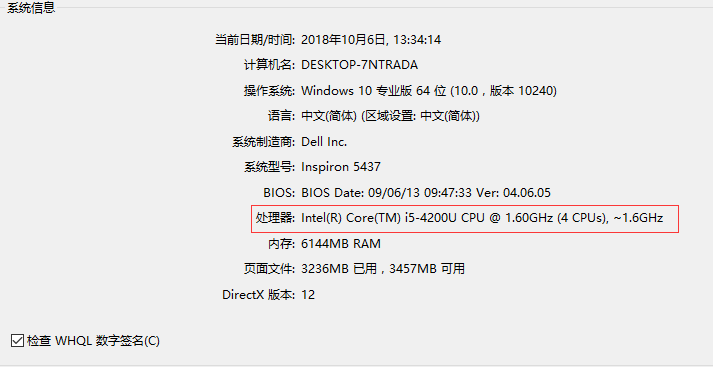
cpu参数:win+r,输入dxdiag即可查看cpu参数。
要求1 给出你猜测程序的瓶颈。你认为优化会有最佳效果,或者在上周在此处做过优化 (或考虑到优化,因此更差的代码没有写出) 。
我认为程序在处理字符串的时候的方法是程序的瓶颈,因为我没有直接使用replace()方法去替换,而是生成列表对于每一个字符的前后来去判断它是否应该被替换成空格,这样的操作面对大量文本数据时是很慢的,虽然我在上周优化了处理字符串的方法,但这种方法却也导致程序运行变慢。仔细来看发现函数中的循环写的并不好,判断字符可以写在一个循环里,修改这里的话,我认为或许会达到优化的目的。
def dispose_words(string): string = string.replace('\n',' ').replace(',',' ') s1 = list(string) num = len(s1) s1.append(' ') for i in range(num): if s1[i] in '."?\')-(;#$%&*!': if str(s1[i-1].isalnum())=='True' and (str(s1[i+1].isalnum())== 'True'): pass else: s1[i]=' ' for i in range(num): if s1[i] in ':': if s1[i+1]=='/': pass else: s1[i]=' ' s = ''.join(s1) #print(s) return s
要求2 通过 profile 找出程序的瓶颈。给出程序运行中最花费时间的3个函数(或代码片断)。要求包括截图。 (5分)
使用了cProfile作为Python的效能分析工具。
具体操作为进入文件目录,打开控制台,输入:
python -m cProfile -s time wf.py -s < war_and_peace.txt
得到结果如下:
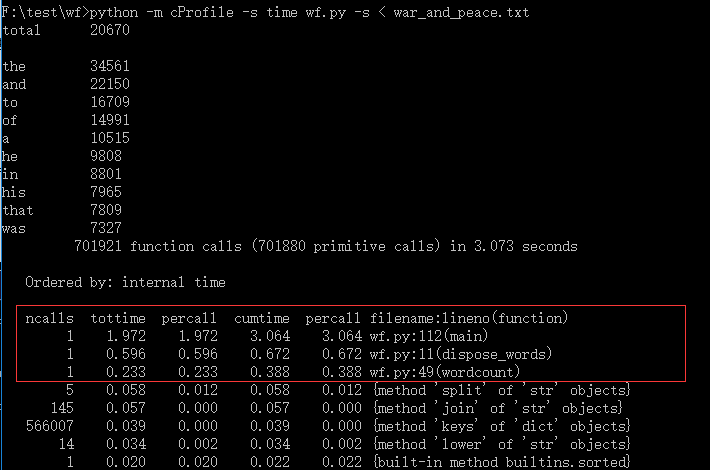
ncalls:表示函数调用的次数;
tottime:表示指定函数的总的运行时间,除掉函数中调用子函数的运行时间;
percall:(第一个percall)等于 tottime/ncalls;
cumtime:表示该函数及其所有子函数的调用运行的时间,即函数开始调用到返回的时间;
percall:(第二个percall)即函数运行一次的平均时间,等于 cumtime/ncalls;
filename:lineno(function):每个函数调用的具体信息;
可以看到时间花费前三的是main(), dispose_words(), wordcount()。dispose_words()运行时间长是在我的意料之中,不过意外的是没想到花费时间最长的main()函数,wordcount是统计单词数量的函数,这部分最开始包含处理字符串的操作,后来将这些都交给了dispose函数,所以wordcount感觉无法再进行优化了。下面分析下main()函数的问题。
elif sys.argv[1]=="-s": if(len(sys.argv)==3): inputfile_1.append(sys.argv[2]) start(inputfile_1) else: s='' for line in sys.stdin: s=s+line start_chong(s)
发现了当时写重定向功能的时候,由于太过着急,没有仔细思考,竟然用for循环读入,这个会花费大量的时间的。
要求3 根据瓶颈,"尽力而为"地优化程序性能。 (5分)
main()花费时间较大的原因上面已经给出了,经查阅资料更换了新的方法,使用sys.stdin.read()直接重定向读文件,代码如下:
elif sys.argv[1]=="-s": if(len(sys.argv)==3): inputfile_1.append(sys.argv[2]) start(inputfile_1) else: s=sys.stdin.read() start_chong(s)
dispose_words在逻辑结构上也进行了优化,在一个for循环中进行对字符的替换。
def dispose_words(string): string = string.replace('\n',' ').replace(',',' ') s1 = list(string) num = len(s1) s1.append(' ') for i in range(num): if s1[i] in '."?\')-(;#$%&*!': if str(s1[i-1].isalnum())=='True' and (str(s1[i+1].isalnum())== 'True'): pass else: s1[i]=' ' if s1[i] in ':': if s1[i+1]=='/': pass else: s1[i]=' ' s = ''.join(s1) #print(s) return s
要求4 再次 profile,给出在 要求1 中的最花费时间的3个函数此时的花费。要求包括截图。(2分)

我们可以看到mian()函数修改后节省了很多时间,dispose_words()也减少了些时间花费,总体达到了优化的目的,下面给出优化后的ptime运行时间。
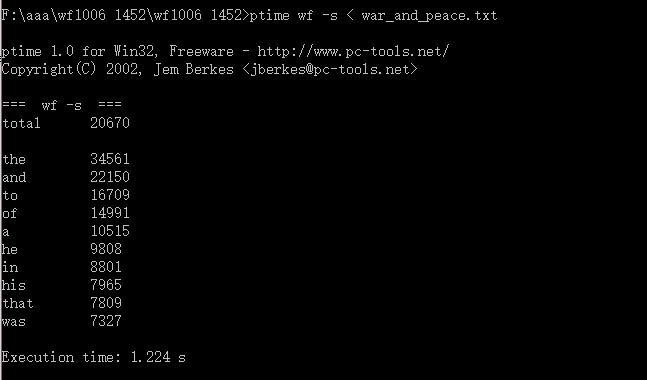
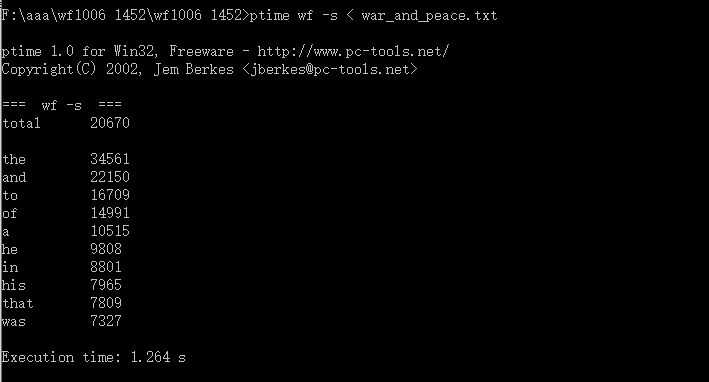
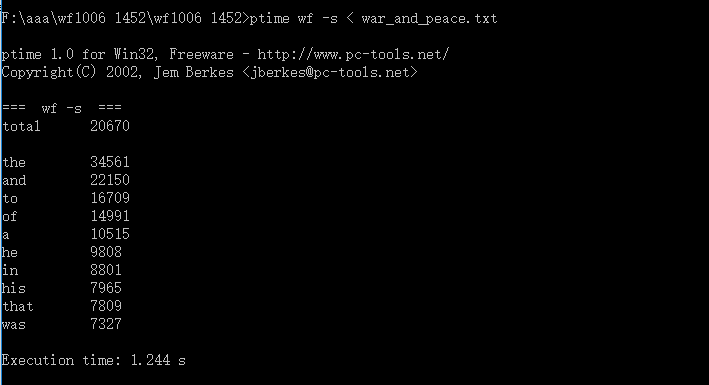
| 运行次数 | 运行时间(s) |
| 第一次 | 1.224 |
| 第二次 | 1.264 |
| 第三次 | 1.244 |
平均时间:1.244(s)
相比之前的3.369(s)节省了2.125(s)
要求5 程序运行时间。根据在教师的机器 (Windows8.1) 上运行的速度排名,分为3档。此题得分,第1档20分, 第2档10分,第3档5分。功能测试不能通过的,0分。(20分)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号