
2.安装Spark与Python练习
一、安装Spark
1.检查基础环境hadoop,jdk
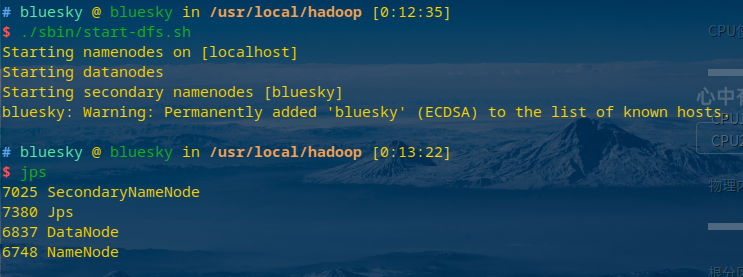
启动hadoop,jps查看启动成功
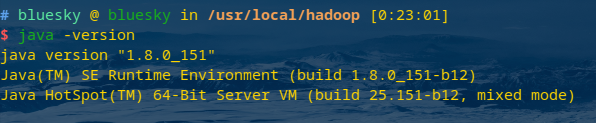
查看jdk环境
下载spark

解压,文件夹重命名、权限
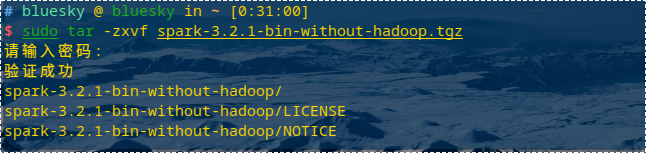
解压spark
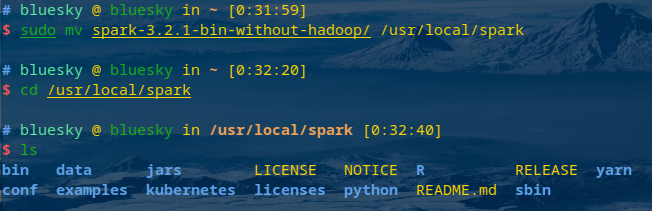
文件夹重命名

授权
配置文件
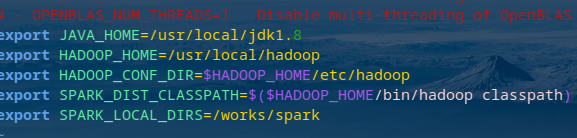
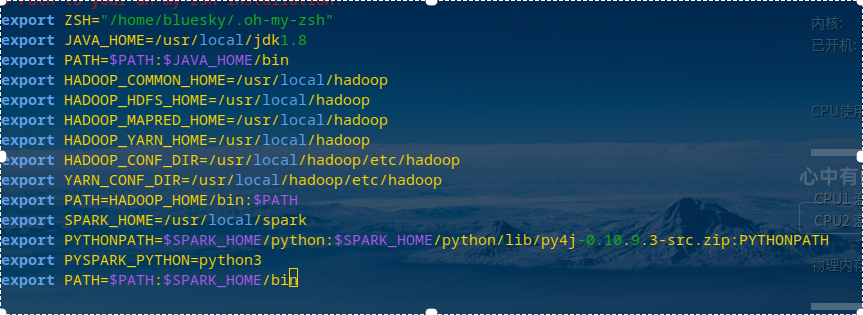
环境变量

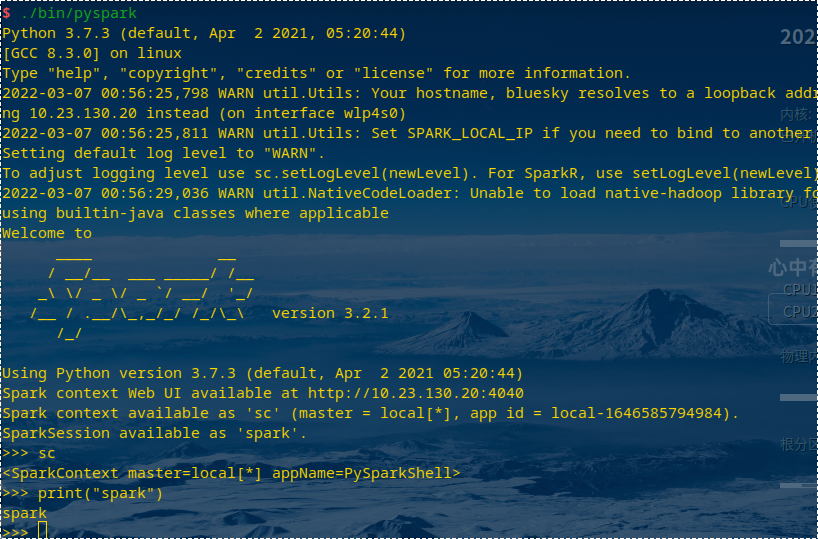
试运行Python代码
二、Python编程练习:英文文本的词频统计
准备文本文件
读文件
file = open("The_Flying_Inn.txt", 'r')
text = file.read()
预处理:大小写,标点符号,停用词,分词
# 以非英文字符为间隔生成list
words = re.split(r'[^a-zA-Z]', text)
# 去除空串
realWords0 = list(filter(None, words))
realWords1 = []
for word in realWords0:
# 均转换为小写
realWords1.append(word.lower())
realWords1.sort()
统计每个单词出现的次数
dct = dict()
for word in realWords1:
if (word in dct):
dct[word] = dct[word] + 1
else:
dct[word] = 1
按词频大小排序
wclist = list(dct.items())
wclist.sort(key=lambda x:x[1],reverse=True)
print(wclist)
结果写文件
text = open("output.txt", "w", encoding='UTF-8')
text.write(str(wclist))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号