
理解一个简单的网页请求过程
我们似乎每天都要做这样一件事情,打开一个浏览器,输入网址,回车,一个空白的页面顿时有了东西,它可能是百度之类的搜索页面,或是一个挤满了文字和图片的门户网站。从我们打开浏览器,到我们看到我们想看的内容,这过程究竟发生了什么?
下面我们就从三个方面理解这个过程,一个是浏览器,二个是服务器,第三个是浏览器和服务器之间通信的协议。在理解这三方面之前我们必须先搞明白将这三方面联系起来的一个词:web。
1,world wide web
我们通常所说的web就是指world wide web。一般来讲,这一种通过浏览器来访问资源的技术。我们经常说的上网,应该大部都是指的是上万维网(web),但是我们经常将万维网和因特网(Internet)搞混。因特网是一种网络互连的技术,它更指的是物理层面上的互连,而万维网应该算是跑在因特网上的一种服务。
我们通常通过浏览器还访问web,我们常见到的网页中包含超文本,图片,视频音频等各项内容。向我们提供这些资源的是一个一个的站点,通过互联网,这些站点相互连接起来。我们通过超链接从一个网页访问到另外一个网页,从一个站点到另外一个站点,所有的这一切组成一个庞大的网,这就是web。
支持web的技术,首先是底层的网络,因为web就是建立在Internet之上,web的基本协议是HTTP协议,它跑在TCP上的协议之上,而TCP协议又需要IP协议的支持,IP协议又要由底层链路来支撑,所以我们可以从高到第看到这样一个协议栈 http->tcp->ip->连路层协议。要理解web到ip就已经足够了。
我们可以想一想web上的资源有哪些? 首先是文本,后来添加了图片,到现在的各种音频视频资源,所有互联网上的资源都要通过一个叫做URI的东西还标记,当然了我们更常见是URL。现在也不必纠结于两者有何不同,URL就是URI的一个子集,URL给了我们资源的地址,所以我们能够找到它。
现在看一个URL:https://www.google.com.hk/images/nav_logo107.png 这是一个图片的url。它是按照这样的语法来定义:scheme://domain:port/path?query_string#fragment_id.scheme就是协议,在浏览器里通常是http,例子中的是https是一种由HTTP和SSL/TLS组合起来的应用,用以提供加密通信和对网络服务器的身份验证(http://zh.wikipedia.org/zh/HTTPS )。然后就是域名,每个站点都至少有一个域名,上面例子上的域名部分是www.google.com.hk,这个域名也是分为三部分的,www是主机名,com.hk算是顶级域名,除了com还有cn,net等。域名后面是端口号默认为80,通常被省略,这是服务器端服务器软件侦听的端口,也是TCP里面一个端口号的值。然后就是path,资源在服务器上的路径。最后问号部分的客户端利用url传给服务器的一些参数值,通常值比较少,不太重要时这么做。
2,协议
(1)HTTP协议
web里最重要的协议就是HTTP协议,对于经典的ISO七层网络模型来说, HTTP处于最高层--应用层。HTTP应用的模型是client/server模型。因此对应着两种HTTP消息类型,request和response。客户端向服务器发出请求,服务器向客户端发回请求。下面看一下两种类型消息的格式:
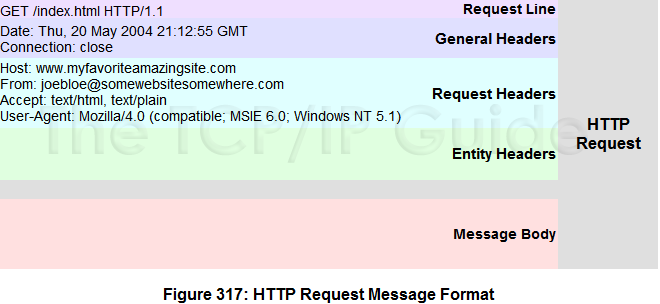

下面分别进行解释。
首先是HTTP Request Message
请求行:请求行以一个方法符号开头,以空格分开,后面跟着请求的URI和协议的版本。请求方法常见的有:GET POST HEAD PUT等。
消息报头:在普通报头中,有少数报头域用于所有的请求和响应消息,但并不用于被传输的实体,只用于传输的消息。 请求报头允许客户端向服务器端传递请求的附加信息以及客户端自身的信息。 请求和响应消息都可以传送一个实体。一个实体由实体报头域和实体正文组成,但并不是说实体报头域和实体正文要在一起发送,可以只发送实体报头域。实体报头定义了关于实体正文(eg:有无实体正文)和请求所标识的资源的元信息。 POST请求的内容放在实体正文中。
HTTP Response Message
状态行:最主要的一个字段是服务器响应代码。比如,200 OK ,400 Bad Request ,401 Unauthorized ,403 Forbidden ,404 Not Found ,500 Internal Server Error ,503 Server Unavailable
消息报头:普通报头和实体报头与 请求报头的类似。有区别的在于响应包头,响应报头允许服务器传递不能放在状态行中的附加响应信息,以及关于服务器的信息和对Request-URI所标识的资源进行下一步访问的信息。
(这部分说的比较粗略,网上的资源比较多,可以参考这一篇:http://blog.csdn.net/gueter/article/details/1524447 和http://book.51cto.com/art/200902/109036.htm )
下面是ethereal抓到的一个get报文,post报文和响应报文,可以大概看一下。
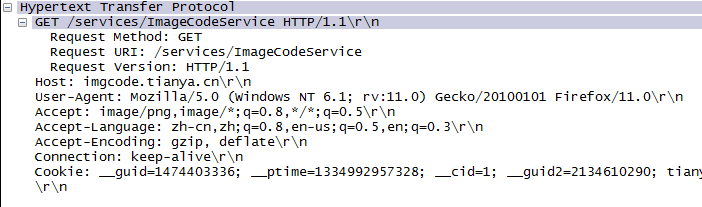
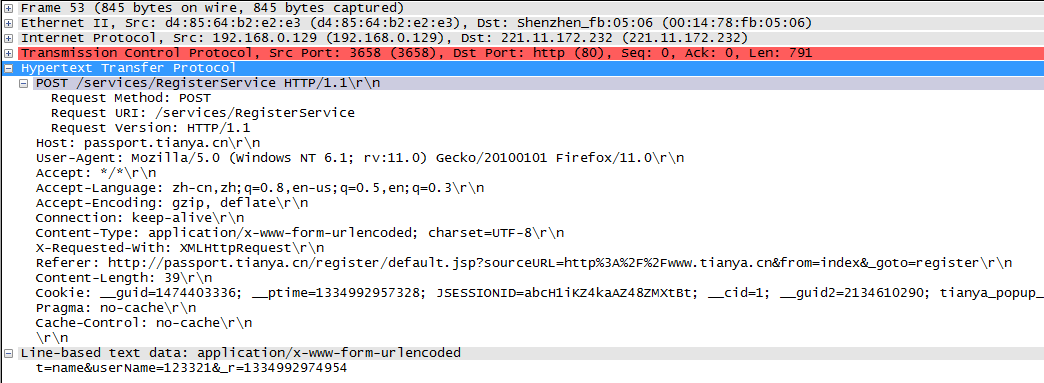
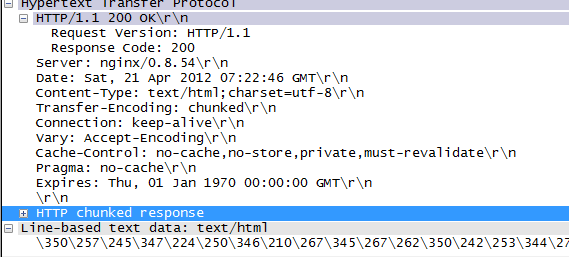
(2)TCP协议
HTTP协议基于TCP协议,也就是HTTP的所有内容将作为TCP的实体被封装到TCP报文里面。TCP协议是面向连接,可靠的传输机制。也就是说客户端在与服务器交互数据的过程中会有一个连接建立和释放的过程,看上面的Http头部字段可以看到相关的字段。TCP有强大的窗口机制能够适应发送方和接收方的发送接收能力,也能根据整个网络状况进行调整。
(3)IP协议
IP协议处于整个TCP/IP协议族的承上启下地位。我们知道因特网上主机是靠一个32位的ip地址来定位的,HTTP用的URL也算是地址,但是比较高级,IP协议是理解不了的,所以需要一个从URL到IP的转换,这个过程通过DNS(域名查询系统)协议完成。我们用的每一台电脑上都配置了DNS服务器的地址,如果没有配置那么你的网关默认充当了,当我们有一个URL想知道对应的IP时就需要向DNS服务器发送查询请求了,它会把查询的结果发回。
2,浏览器
在web的世界里最不能少的角色就是浏览器。前面我们说到HTTP协议,HTTP消息有两种,request和response。浏览器的主要工作就是发送http request报文和接收处理http response报文。没有看过浏览器的开源文档,但是我觉得一个软件只要完成下面几件事,基本上就可以称的上一个浏览器了。
(1)能够根据用户的请求生成合适的HTTP REQUEST报文。比如用户在浏览器地址栏上输入地址进行访问,浏览器要能够生成HTTP GET报文,表单的发送生成POST报文等等。
(2) 能够对各种的RESPONSE进行处理。
(3)渲染Html文档,生成文档树,能够解释css,还要有个javascript引擎。
(4)能够发起dns查询得到ip地址。
浏览器是个非常复杂的软件,当然现在的浏览器对http协议的支持应该不是问题,它们主要纠结于html文档渲染部分,对于用户层出不穷的新需求,w3c层出不穷的新标准,浏览器的路应该才刚刚开始。
3, 服务器
服务器有两个层级的概念,它可以是机器,它上面存着一个站点的所有东西,也可以是软件,安装在一个也叫做服务器的机器上,帮助这个机器分发用户想要的东西。 我对服务器研究不多,只是用过几次apache。所以只是简单的谈谈我的认识。
服务器最基本的功能就是响应客户端的资源请求。服务器首先会侦听80端口,来了http请求,就根据请求进行处理,请求一个图片那就根据路径找到资源发回,请求静态html页面也是如此,如果请求的是像php这样的动态页面应该先调用php编译器(或是解释器吧)生成html代码,然后返回给客户端。当然还要解决的一个问题就是并行问题以应对大访问量。
因为对这方面不太了解,只想到了这么多。
先说到这里, 有了新的认识再写。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号