论文阅读笔记(四十)【CVPR2017】:Human Semantic Parsing for Person Re-identification
Introduction
作者提出了两个问题:
①行人重识别性能的提高需要结合很多复杂的模型吗(如关键点提取等)?
②使用局部检测框是提取局部特征的最好方法吗?
针对第一个问题,作者采用了Inception-V3作为骨干网络,采用交叉熵损失,简单的方法也取得了最佳的效果。针对第二个问题,作者采用了语义分割,能更准确的定位部件的位置。
Methodology
(1)Inception-V3架构:
Inception-V3是一个包含48个卷积层的网络架构,相比ResNet152的计算量更小且效果更好。输出的结果为2048维的特征向量。
SPReID(Human Semantic Parsing for Person Re-identification)整体网络架构为:
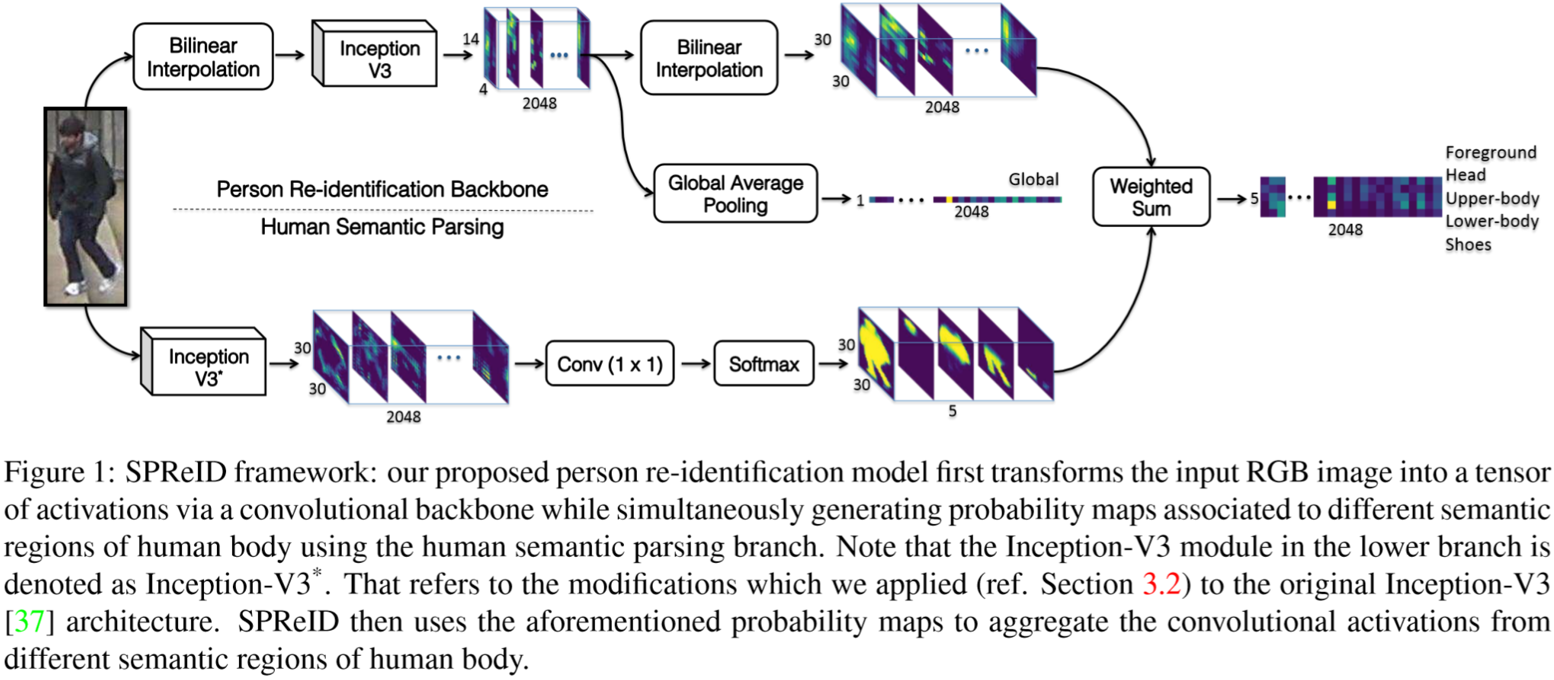
(2)Human Semantic Parsing Model:
采用了Inception-V3作为语义提取的框架,但做了两个改进:
①为了输出的特征映射分辨率足够,将Inception-V3的最后一层stride由2改为1,并改为空洞卷积
②去除全局平均池化,引入一个1*1卷积层作为语义分类器。
最终得到各个部位的概率映射图,部位分成了五个部分:前景、头、上半身、下半身、鞋子。
(3)Person Re-identification Model:
上分支用于提取到行人的特征,将特征映射同语义映射加权后累加,即可得到整体的行人特征。由于语义分割模型通常需要较高分辨率的图片,送入上分支之前,图片先要通过双线性插值缩小,提取得到特征映射后再用双线性插值放大,使得与语义映射大小匹配。
Experiment
(1)实验设置:
①数据集设置:测试数据集:Market-1501、CUHK03、DukeMTMC-reID;除此之外,训练数据集扩充了如下集合:3DPeS、CUHK01、CUHK02、PRID、PSDB、Shinpuhkan、VIPeR。
②网络的训练:
[1]Baseline网络的训练:采用3DPeS、CUHK01、CUHK02、PRID、PSDB、Shinpuhkan、VIPeR组合数据集进行训练,迭代次数为200K次,图像尺寸为492*164;用Market1501、CUHK03、DukeMTMC-reID训练微调,每个迭代次数为50K次,图像尺寸为748*246;
[2]SPReID网络的训练:用上述10个数据集对进行训练,图像分辨率为512*170;
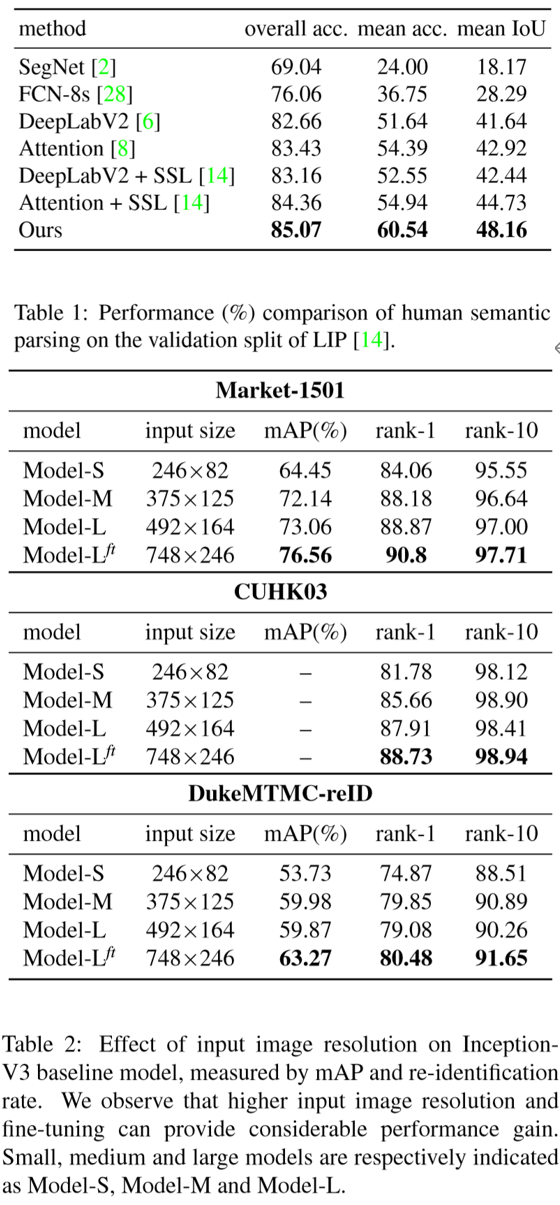
[3]语义分割网络的训练:采用Look into Person(LIP)数据集进行训练,效果如下图:

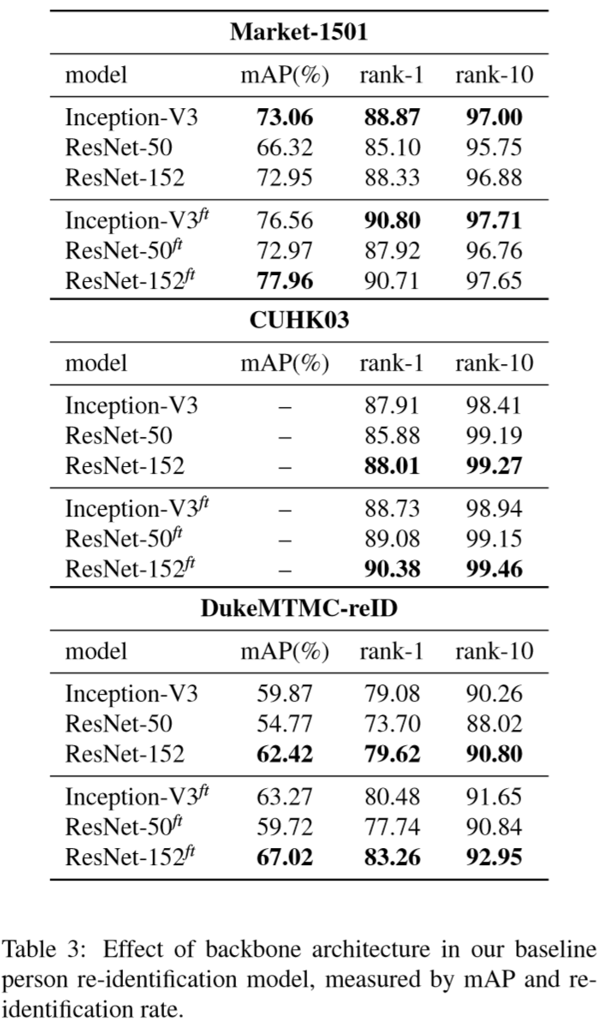
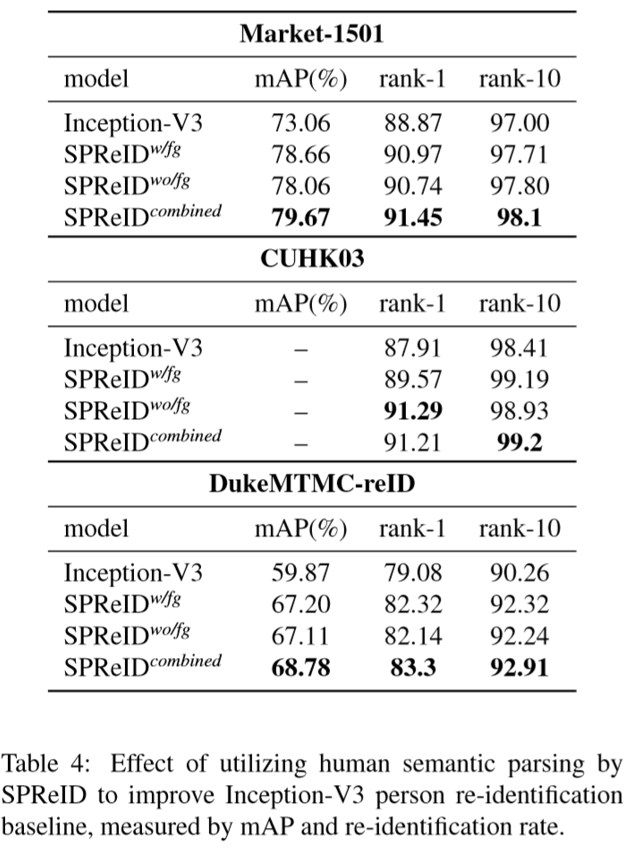
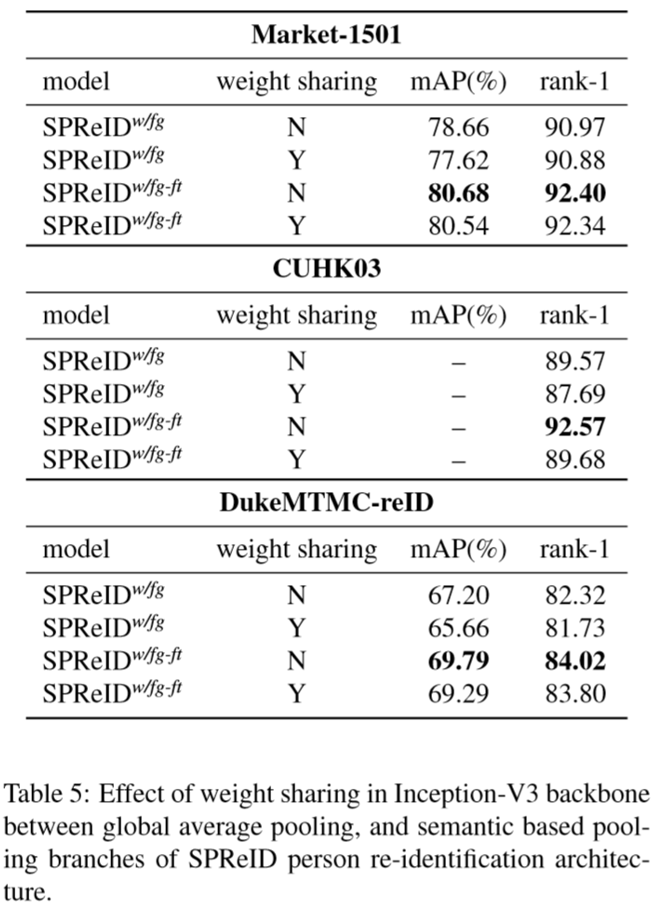
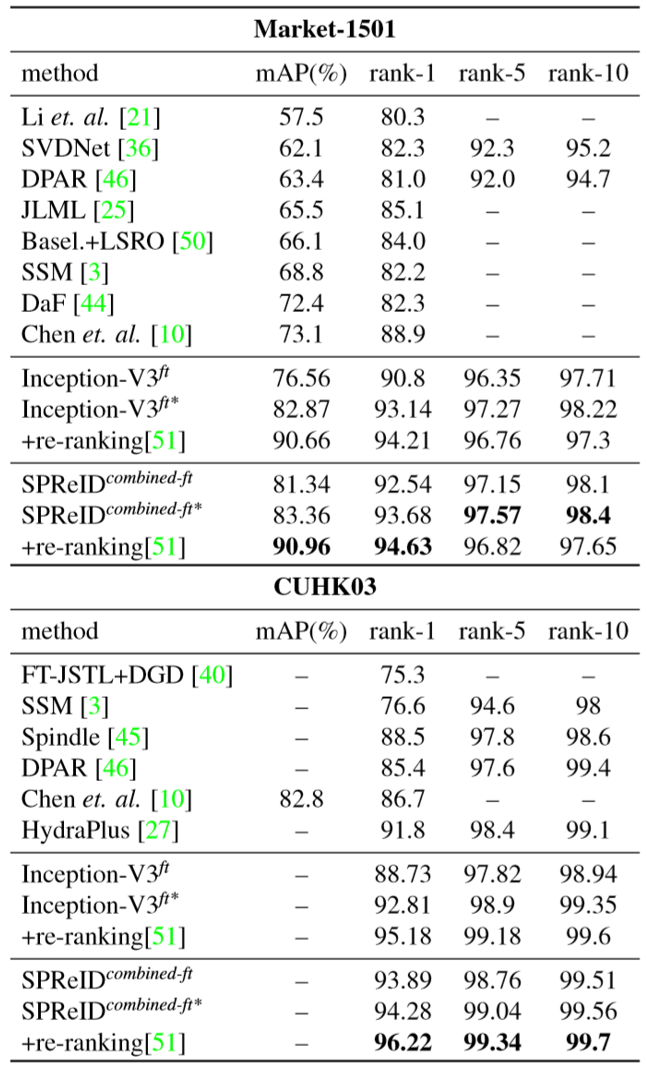
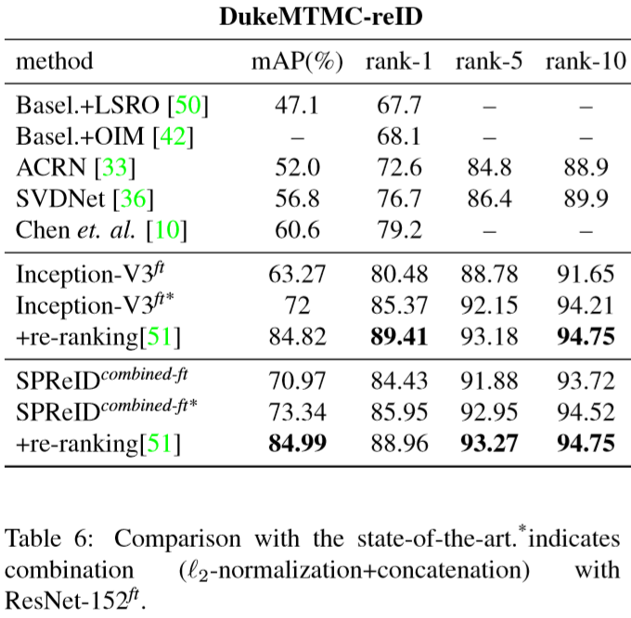
(2)实验结果:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号