nginx-404日志报警
nginx的日志通过filebeat采集,最终输送到es中。脚本通过essql遍历索引,查出对应的值
- webhook报警类
点击查看代码
#!/bin/env python3
# -- encoding: utf-8 --
import requests
import json
class AlterWeChat():
def __init__(self,msg):
self.data = msg
def alert_msg(self):
headers = {"Content-Type": "application/json"}
robot_url = 'https://qyapi.weixin.qq.com/cgi-bin/webhook/send?key=xxxxxxxxxxxxxxxx'
print(self.data)
result = requests.post(url=robot_url, headers=headers, json=self.data).json()
if result.get('errcode') == 0:
return 'ok'
else:
print('wx:',result.get('errmsg'))
- nginx报警类
点击查看代码
#!/bin/env python3
# -- coding: utf-8 --
import Wechat_alert
import time
import requests
from elasticsearch import Elasticsearch
import json
#############################################
# 解决发送报警提示字符集问题 'ascii' codec can't encode characters in position 0-2: ordinal not in range(128)
import sys
reload(sys)
sys.setdefaultencoding('utf8')
##############################################
class QueryElastsearch():
white_list = ['124.65.169.203','124.65.169.202','219.142.240.66'] # 白名单
dict_404 = {} # 调用函数最终返回的数据
now_time = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()) # 完整时间戳
now_date = time.strftime('%Y.%m.%d') # 只显示到天
es = Elasticsearch(['http://127.0.0.1:9200'], sniff_on_start=True, sniff_on_connection_fail=True,
sniff_timeout=60, timeout=30, http_auth=('elastic', 'aaaaaaa'), ) # 连接es
# 查询出近1分钟状态码是404的 显示字段 项目,状态,客户端访问ip,时间,时间戳
es_query = {
"_source": [
"domain",
"status",
"client",
"url",
"time",
"@timestamp"
],
"query": {
"bool": {
"must": [
{"terms": {
"status":
["404"]
}}
],
"must_not": [
{"wildcard": {
"url": "*.*"
}
},
{"match": {
"url": "/health"
}
},
{"match": {
"url": "/src/"
}
},
{"match": {
"url": "/src"
}
},
{"match": {
"url": "/merchants/health"
}
},
{"match": {
"url": "/api/checkhealth"
}
},
#{ "match": {
# "url": "/api/Subscription/getticket" # baoshui-api 会调用
#}
#},
{"match": {
"url": "/"
}
}
],
"filter": {
"range": {
"@timestamp": {
"gte": "now-1m"
}
}
}
}
}
}
def get_index(self):
# 获取所有索引
indices = self.es.indices.get_alias().keys()
return indices
def get_elastsearch_data(self,index):
# 获取索引中的404数据,输出类型是字典
res = self.es.search(index=index, body=self.es_query)
count = res['hits']['total'] # es返回的total
if count != 0:
for i in res['hits']['hits']:
data_dict = i['_source'] # 获取出es每一条数据 es返回的数据是字典
if data_dict['client'] not in self.white_list: # 判断是否在白名单
self.get_elastsearch_dict(data_dict) # 遍历性的传数据,每次只传一个字典 也就是es的一行
def write_url_log(self,status, domain, url, client, time, timestamp):
# 写入日志
log_path = '/home/ubuntu/gph_alert/logs/alert-nginx-{}.csv'.format(self.now_date)
with open(log_path, 'a+') as f:
f.write('{},{},{},{},{},{}\n'.format(self.now_time, time, domain, client, url, status))
def get_elastsearch_dict(self,data):
# 把从es中获取到的数据存到本地日志,和字典中 把字典返回给别人
status, domain, url, client, time, timestamp = data['status'], data['domain'], data['url'], data['client'], \
data['time'], data['@timestamp']
self.write_url_log(status, domain, url, client, time, timestamp)
if domain not in self.dict_404: # 如果项目不在最大的列表
self.dict_404[domain] = {} # 创建一个 {demain:{}}
if client not in self.dict_404[domain]: # clinet 不在domain中 创建 {domain:{client:[url]}}
self.dict_404[domain][client] = [url]
elif domain in self.dict_404: # domain 在大字典
if client not in self.dict_404[domain]: # 开始判断访问的ip是不是在 domain的字典里
self.dict_404[domain][client] = [url] # 没有的情况下 创建一个 {client:[]}
elif client in self.dict_404[domain]: # 客户端ip如果在domain字典中
self.dict_404[domain][client].append(url) # 把url新增进去
def main(self):
# 读取es当天所有的nginx日志,不含error关键字的索引
for index in self.get_index():
if self.now_date in index and 'nginx' in index and 'error' not in index:
self.get_elastsearch_data(index) # 去每个字典执行 sql并获取结果
return self.dict_404
def getip_isp_old(self,ip):
url = 'https://hcapi01.api.bdymkt.com/ip'
params = {}
params['ip'] = ip
headers = {
'Content-Type': 'application/json;charset=UTF-8',
'X-Bce-Signature': 'AppCode/a74967ee0ce04a56b07d7866d32bf0b0'
}
r = requests.request("GET", url, params=params, headers=headers)
return_msg = eval(r.content.decode('utf-8'))
print(return_msg.get('code'))
if return_msg.get('code') == 200:
isp = return_msg.get('data').get('country') + '-' + return_msg.get('data').get(
'region') + '-' + return_msg.get('data').get('isp')
return isp
else:
return return_msg
def getip_isp(self,ip):
# http://ip.zxinc.org/
# https://ip.zxinc.org/ipquery/
url = 'http://ip.zxinc.org/api.php?type=json&ip=' + ip
try:
res = requests.get(url,timeout=10)
res_dict = json.loads(res.text)
isp = res_dict.get('data').get('location')
return isp
except Exception as msg:
return 'msg: %s' % msg
def send_alert_msg(dict):
now_time = QueryElastsearch.now_time
# 把dict_404的元素读出来,分析并报警
max_error_code = 10 # 404 阈值
for daemin,value in dict.items():
for client,url in value.items():
if len(url) >= max_error_code:
msg = {
"msgtype": "markdown",
"markdown": {
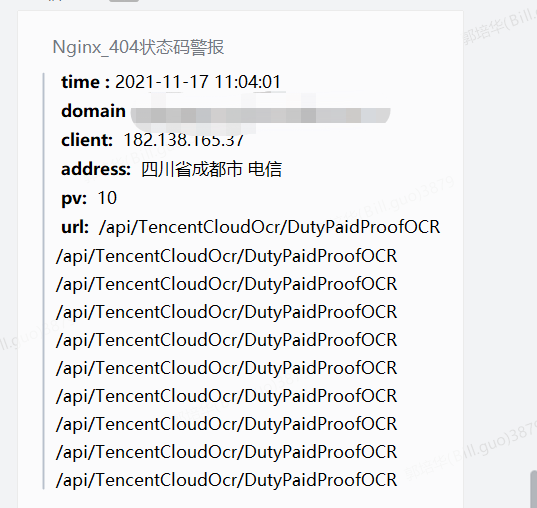
"content": " <font color=\"comment\"> Nginx_404状态码警报 </font> \n > ** time :** {} \n > ** domain :** {} \n > ** client: ** {} \n > ** address: ** {} \n > ** pv: ** {} \n > ** url: ** {} ".format(now_time,daemin,client,QueryElastsearch().getip_isp(client),len(url),'\n'.join(url[0:10]))
}
}
Wechat_alert.AlterWeChat(msg).alert_msg() # 调用微信报警
print(daemin,client,len(url))
if __name__ == '__main__':
start_time = time.time()
dict = QueryElastsearch().main()
if dict:
send_alert_msg(dict)
stop_time = time.time()
print( '耗时%s s!' % round(stop_time - start_time))
- 效果图

 浙公网安备 33010602011771号
浙公网安备 33010602011771号