openGauss源码解析(171)
openGauss源码解析:AI技术(18)
8.4 智能索引推荐
数据库的索引管理是一项非常普遍且重要的事情,任何数据库的性能优化都需要考虑索引的选择。为此,openGauss支持原生的索引推荐功能,可以通过系统函数等形式进行使用。
8.4.1 使用场景
在大型关系型数据库中,索引的设计和优化对SQL语句的执行效率至关重要。一直以来,数据库管理人员往往基于相关理论知识和经验,进行人工设计和调整索引。这样做的缺点在于,消耗了大量的时间和人力,同时人工设计的方式往往不能确保索引是最优的。
openGauss提供了智能索引推荐功能,该功能将索引设计的流程自动化、标准化,可分别针对单条查询语句和工作负载推荐最优的索引,提升作业效率、减少数据库管理人员的运维操作。
openGauss的智能索引推荐功能可覆盖多种任务级别和使用场景,具体包含以下三个特性。
(1) 单条查询语句的索引推荐。该特性可基于查询语句的语义信息和数据库的统计信息,对用户输入的单条查询语句生成推荐的索引。
(2) 虚拟索引。该特性可模拟真实索引的建立,同时避免真实索引创建所需的时间和空间开销,用户可通过优化器评估虚拟索引对指定查询语句的代价影响。
(3) 基于工作负载的索引推荐。该特性将包含有多条DML语句的工作负载作为任务的输入,最终生成一批可优化整体工作负载执行时间的索引。该功能适用于多种使用场景,例如,当面对一批全新的业务SQL且当前系统中无索引,本功能将针对该工作负载量身定制,推荐出效果最优的一批索引;当系统中已存在索引时,本功能仍可查漏补缺,对当前生产环境中运行的作业,通过获取日志来推荐可提升工作负载执行效率的索引,或者针对极个别的慢SQL进行单条查询语句的索引推荐。
8.4.2 现有技术
索引推荐技术按照任务级别划分,可分为基于单条查询语句的索引推荐和基于工作负载的索引推荐。对于基于单条查询语句的索引推荐,使用者每次向索引设计工具提供一个查询语句,工具会针对该语句生成最佳的索引。目前的主流算法是首先提取该查询语句的语义信息和数据库中的统计信息,然后基于相关的索引设计和优化理论,对各子句中的谓词进行分析和处理,启发式地推荐最优索引。此类任务主要是针对个别查询时间慢的SQL进行索引优化,应用场景较为有限。
一般来说,更广泛使用的任务场景是基于工作负载的索引推荐,即给定一个包含多种类型SQL语句的工作负载,生成使得系统在该工作负载下的运行时间降至最低的索引集合。在索引选择算法中,核心是量化和估计索引对于工作负载的收益,这里的收益是指,当该索引应用于指定工作负载时,工作负载的总代价的减少量。根据代价估计的方式的不同,目前的算法可分为两大类。
(1) 基于优化器的代价估计的方法。采用优化器的代价模型来对索引进行代价估计是较为准确的,因为优化器负责查询计划和索引的选择。同时,一些数据库系统支持虚拟索引的功能,虚拟索引并没有在存储空间中创建物理上的索引,而是通过模拟索引的效果来影响优化器的代价估计。目前的主流数据库产品均采用了该种方法,如SQL Server的AutoAdmin、DB2的DB2 Advisor等。
(2) 基于机器学习的方法。上一种方法由于优化器的局限性,会导致索引收益的估计发生偏差,例如选择度的错误估算或者代价估计模型不准确。在学术界的最新进展中,一些方法采用了机器学习算法来预测和分类哪种查询计划更加有效,或者是采用基于神经网络的代价模型来缓解传统模型带来的问题。但是此类方法往往需要大量的训练数据,并不适用于全部的业务环境。
8.4.3 实现原理
1. 针对单条查询语句的索引推荐
单条查询语句的索引推荐是以数据库的系统函数形式提供的,用户可以通过调用gs_index_advise()命令使用。其原理是利用在SQL引擎、优化器等处获取到的信息,使用启发式算法进行推荐。该功能可以用来对因索引配置不当而导致的慢SQL进行优化。
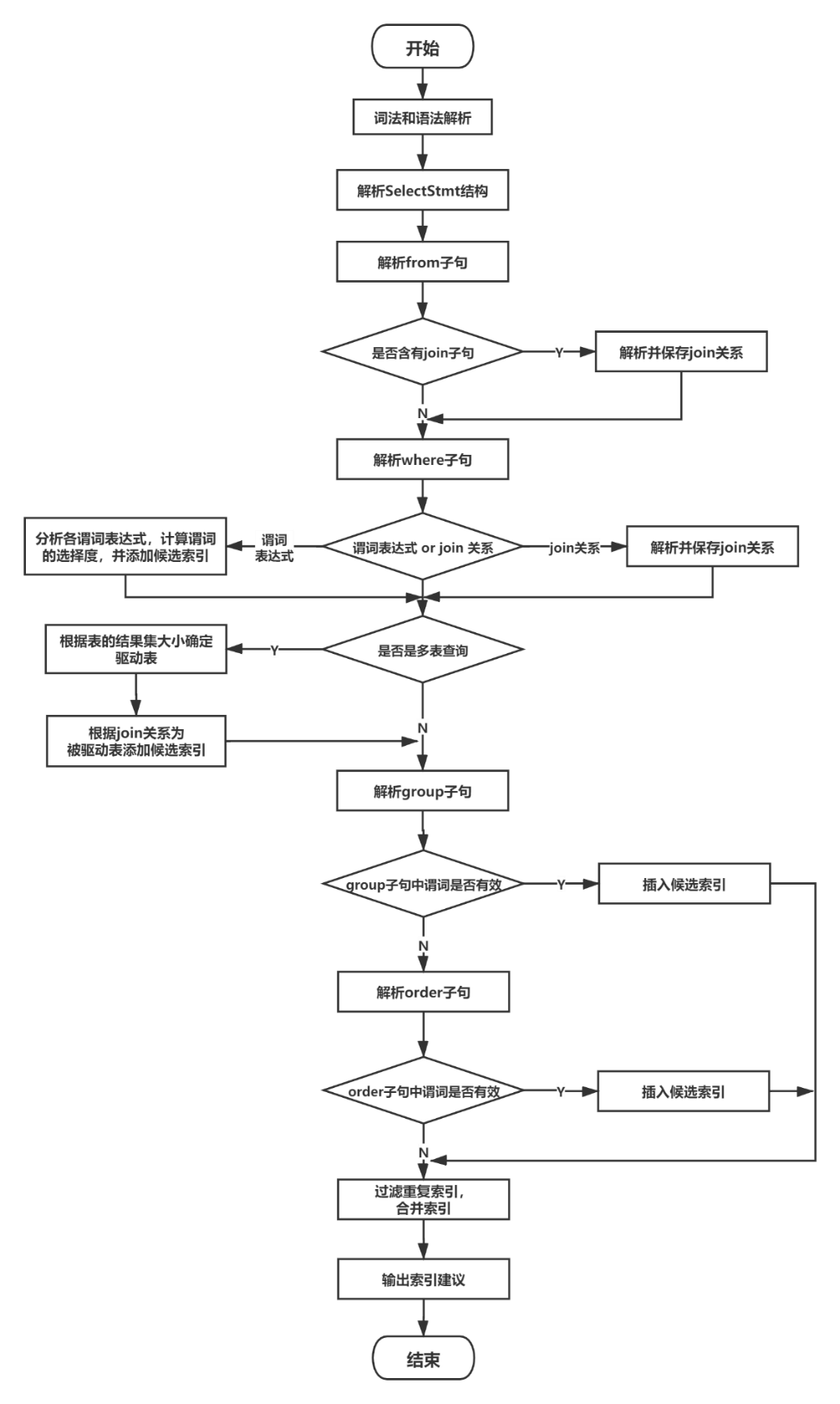
图8-12 单条查询语句的索引推荐流程图
单条查询语句的索引推荐步骤如图8-12所示,该过程如下。
(1) 对给定的查询语句进行词法和语法解析,得到解析树。
(2) 依次对解析树中的单个或多个查询子句的结构进行分析。
(3) 整理查询条件,分析各个子句中的谓词。
(4) 解析From子句,提取其中的表信息,如果其中含有join子句,则解析并保存join关系。
(5) 解析Where子句,如果是谓词表达式,则计算各谓词的选择度,并将各谓词根据选择度的大小进行倒序排列,依据最左匹配原则添加候选索引,如果是Join关系,则解析并保存join关系。
(6) 如果是多表查询,即该语句中含有join关系,则将结果集最小的表作为驱动表,根据前述过程中保存的join关系和连接谓词为其他被驱动表添加候选索引。
(7) 解析Group和Order子句,判断其中的谓词是否有效,如果有效则插入到候选索引的合适位置,Group子句中的谓词优于Order子句,且两者只能同时存在一个;这里,候选索引的排列优先级为:join中的谓词> Where等值表达式中的谓词> Group或Order中的谓词> Where非等值表达式中的谓词。
(8) 检查该索引是否在数据库中已存在,若存在则不再重复推荐。
(9) 输出最终的索引推荐建议。
2. 虚拟索引
通过虚拟索引功能实现对待创建索引的效果和代价进行估计。对于给定的索引表名和列名,可以在数据库内部建立虚拟索引,该虚拟索引只具有待创建索引的元信息,而不会真正创建物理索引文件,因此避免了真实索引的创建开销。这些元信息包括:待创建索引的表名、列名和其他统计信息,虚拟索引仅用于通过explain语句显示优化器的可能执行路径,不能提供真正的索引扫描。
因此,对某条SQL语句执行explain命令,可以查看到创建索引前后优化器规划出的执行计划、检验该待创建索引是否被数据库采用以及是否有性能提升。虚拟索引主要是基于数据库中的hook(钩子机制)实现的,即通过使用全局的函数指针get_relation_info_hook和explain_get_index _name_hook,来干预和改变查询计划的估计过程,让优化器在规划路径时,考虑到可能出现的索引扫描。
3. 基于工作负载的索引推荐
基于工作负载的索引推荐功能的主要模块如图8-13所示。
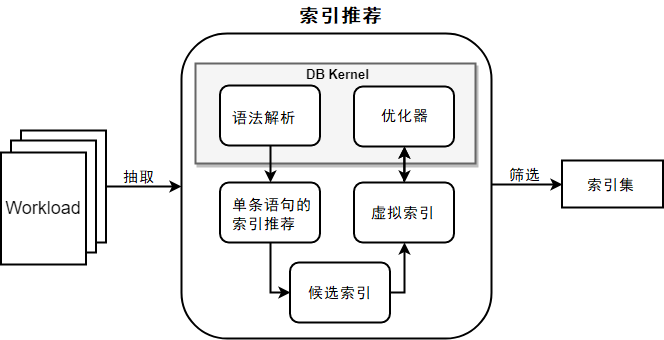
图8-13 基于工作负载索引推荐流程图
主要包括以下步骤。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号