

openGauss源码解析(6)
openGauss源码解析:openGauss简介(6)
1.5 价值特性
openGauss相比其他开源数据库主要有高性能、高扩展、可维护性和高可用等特点。
1.5.1 高性能
1. CBO优化器
openGauss优化器是典型的基于代价的优化(cost-based optimization,简称CBO)。在这种优化器模型下,数据库根据表的元组数、字段宽度、NULL记录比率、唯一值(distinct value)、最常见值(most common value, 简称MCV)等表的特征值以及一定的代价计算模型,计算出每一个执行步骤的不同执行方式的输出元组数和执行代价(cost),进而选出整体执行代价最小/首元组返回代价最小的执行方式进行执行。
CBO优化器能够在众多计划中依据代价选出最高效的执行计划,最大限度地满足客户业务要求。
2. 行列混合存储
openGauss支持行存储和列存储两种存储模型,用户可以根据应用场景,建表的时候选择行存储还是列存储表。
一般情况下,如果表的字段比较多(大宽表),查询中涉及的列不很多的情况下,适合列存储。如果表的字段个数比较少,查询大部分字段,那么选择行存储比较好。
在大宽表、数据量比较大的场景中,查询经常关注某些列,行存储引擎查询性能比较差。例如气象局的场景,单表有200~800个列,查询经常访问10个列,在类似的场景下,向量化执行技术和列存储引擎可以极大地提升性能和减少存储空间。行存储表和列存储表各有优劣,建议根据实际情况选择。
(1) 行存储表。默认创建表的类型。数据按行进行存储,即一行数据紧挨着存储。行存储表支持完整的增、删、改、查。适用于对数据需要经常更新的场景。
(2) 列存储表。数据按列进行存储,即一列所有数据紧挨着存储。单列查询I/O小,比行存储表占用更少的存储空间,适合数据批量插入、更新较少和以查询为主统计分析类的场景。列存储表不适合点查询,INSERT操作插入单条记录性能差。
行存储表和列存储表的选择原则如下。
(1) 更新频繁程度。数据如果频繁更新,选择行存储表。
(2) 插入频繁程度。如果是频繁少量的插入数据,选择行存储表。一次插入大批量数据,选择列存储表。
(3) 表的列数。如果表的列数很多,选择列存储表。
(4) 查询的列数。如果每次查询时,只涉及了表的少数几个列(<50%总列数),选择列存储表。
(5) 压缩率。列存储表比行存储表压缩率高。但高压缩率会消耗更多的CPU资源。
3. 自适应压缩
当前主流数据库通常都会采用数据压缩技术。数据类型不同,适用于它的压缩算法不同。对于相同类型的数据,其数据特征不同,采用不同的压缩算法达到的效果也不相同。自适应压缩正是从数据类型和数据特征出发,采用相应的压缩算法,实现了良好的压缩比、快速的入库性能以及良好的查询性能。
数据入库和频繁的海量数据查询是用户的主要应用场景。在数据入库场景中,自适应压缩可以大幅度地减少数据量,成倍提高I/O操作效率,将数据簇集存储,从而获得快速的入库性能。当用户进行数据查询时,少量的I/O操作和快速的数据解压可以加快数据获取的速率,从而在更短的时间内得到查询结果。例如支持手机号字符串的大整数压缩、支持numeric类型的大整数压缩、支持对压缩算法进行不同压缩水平的调整。
4. 分区
在openGauss系统中,数据分区是将实例内部的数据集按照用户指定的策略做进一步拆分的水平分表,将表按照指定范围划分为多个数据互不重叠的部分。
对于大多数用户使用场景,分区表和普通表相比具有以下优点:
(1) 改善查询性能:对分区对象的查询可以仅搜索自己关心的分区,提高检索效率。
(2) 增强可用性:如果分区表的某个分区出现故障,表在其他分区的数据仍然可用。
(3) 方便维护:如果分区表的某个分区出现故障,需要修复数据,只修复该分区即可。
(4) 均衡I/O:可以把不同的分区映射到不同的磁盘以平衡I/O,改善整个系统性能。
目前openGauss数据库支持的分区表为范围分区表、列表分区表、哈希分区表。
(1) 范围分区表:将数据基于范围映射到每一个分区,这个范围是由创建分区表时指定的分区键决定的。这种分区方式是最为常用的。范围分区功能,即根据表的一列或者多列,将要插入表的记录分为若干个范围(这些范围在不同的分区里没有重叠),然后为每个范围创建一个分区,用来存储相应的数据。
(2) 列表分区表:将数据基于各个分区内包含的键值映射到每一个分区,分区包含的键值在创建分区时指定。列表分区功能,即根据表的一列,将要插入表的记录中出现的键值分为若干个列表(这些列表在不同的分区里没有重叠),然后为每个列表创建一个分区,用来存储相应的数据。
(3) 哈希分区表:将数据通过哈希映射到每一个分区,每一个分区中存储了具有相同哈希值的记录。哈希分区功能,即根据表的一列,通过内部哈希算法将要插入表的记录划分到对应的分区中。
用户在下发CREATE TABLE命令时增加PARTITION参数,即表示针对此表应用数据分区功能。
用户可以在实际使用中根据需要调整建表时的分区键,使每次查询结果尽可能存储在相同或者最少的分区内(称为“分区剪枝”),通过获取连续I/O大幅度提升查询性能。
实际业务中,时间经常被作为查询对象的过滤条件。因此,用户可考虑选择时间列为分区键,键值范围可根据总数据量、一次查询数据量调整。
5. SQL by pass
在典型的OLTP场景中,简单查询占了很大一部分比例,这种查询的特征是只涉及单表和简单表达式的查询。为了加速这类查询,提出了SQL by pass框架:在parse层对这类查询做简单的模式判别后,进入特殊的执行路径里,跳过经典的执行器执行框架,包括算子的初始化与执行、表达式与投影等经典框架,直接重写一套简洁的执行路径,并且直接调用存储接口。这样可以大大加速简单查询的执行速度。
6. 鲲鹏NUMA架构优化
鲲鹏NUMA架构优化图如图1-9所示。
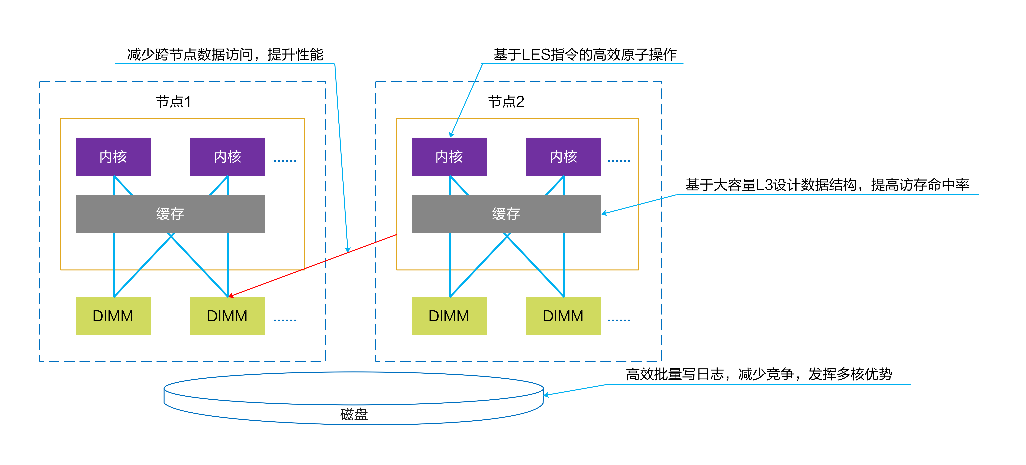
图1-9 鲲鹏NUMA架构优化图
openGauss架构优化要点如下。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号