
啥是map啥是reduce
mapredue是根据谷歌的三大论文里面的mapreduce paper的出来的一个hadoop计算引擎。
我们现在可以说是ZB时代了,日益所需的大数据时代让我们不得不使用分布式存储,分布式计算,分布式调度。以往的单台计算机已经存储不了我们的数据,也不能很快的计算我们想要实现的过程。
今天,就来讨论讨论分布式计算的mapreduce。
mapreduce分成map端和reduce端。
map端根据数据进行一些列操作,写入自己的磁盘。
然后reduce从map端把数据弄过来,也进行一些列操作。
这样原本的单台节点的工作量,就平均了好几台节点了。
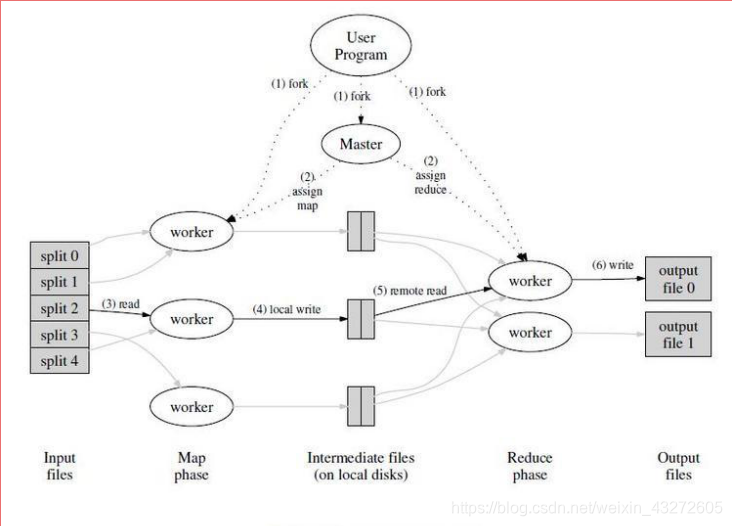
首先,我们来看看这张图。
最左边是一系列的split分片,可以看成一个个数据块,一般默认是64M,可能要看不同版本了,因为数据量现在越来越大,需要看看具体情况了。有时候设置为128M也不为过。
在每个split上我们可以定义自己的map函数,map任务就可以针对对应的split进行自己的逻辑操作。
下面我们就来看看整个图片的具体过程。
Map端
我们在进行分片后,我们需要进行map端的过程。
1:map根据都进来的一条条数据,分别有key和value,
然后执行自己的map函数里面的逻辑块,然后调用context.write将结果一条条输出去。
2:输出去是先写入一个环形的缓冲区,
当数据量达到唤醒缓冲区的80%时,就会开始向本地磁盘溢写。
在溢写过程中,会首先对数据进行Partition分区,即根据reduce的个数进行分区。
分区的方法可以自己实现一个partition然后在main里面设置分区就行,
mapreduce有自己默认的分区方法。
3:分区写数据时,还可以进行排序,也是可以自己定义排序方法。
4:分区写数据时,不仅可以排序,还可以进行combianer,
就是将同一个key的内容可以进行合并,相当于提前对相同key进行一个reduce。
比如,我如果有(a,1),(b,1),(a,1),(a,1)我如果不进行combianer,
那么传到reduce端的数据就是完完全全没有变得数据,3个a和1个b的数据,
但是如果我进行了combiner,那么就变成了(a,3),(b,1),那么传过去的就是1个a,1个b,
因为我把三个a的value进行了合并,这个合并方法可以自己定义的。
这样就减少了传输量,要知道,map端和reduce端不一定在同一个节点,
map端和reduce端是靠网络通信来实现数据传输的,所以你如果有些数据不进行combiner,
那么你的任务性能就可能下降许多。尤其是数据量很大的时候。
5:排序的过程是针对某一个分区进行排序,某一个分区会出现很多小文件,
小文件了会进行sort,combiner然后所有小文件汇总又会进行归并排序来合并文件。形成一个分区。
6:不同分区合在一起,等待reduce端来读取数据。
map端基本就结束了。
reduce过程
1:reduce先以http方式从map端磁盘读取对应属于自己分区的磁盘文件,放入内存缓冲区。
2:将读取过来的分区文件进行归并排序sort,并且进行combiner合并(当然combiner需要自己定义啦)。
3:然后作为reduce的输入文件,进行reduce逻辑操作,最终得出一个分区文件输出出去。注意一个reduce就是要给分区,所以几个reduce就会在hdfs上对应几个输出的分区文件。
滴滴滴滴,休息一下。。。。。。。。。。。。。。。。
根据上面这几点,我们需要注意的是一个mapreduce过程,其实就是两个计算过程,然后其余基本就是排序,合并的过程了。
然而排序,合并又会设计到shuffle
shuffle就是清洗的意思,就是将数据重新清洗。打乱。
shuffle主要有map端,reduce端。。
map端shuffle
map端的shuffle就是在内存缓冲区达到一定量时,将数据根据partition实现方法进行分区,
分区数和reduce个数一样,并且数据会写道对应的分区。
reduce端shuffle
reduce端主要是从map端拉取数据,将不同节点但是是相同分区的数据拉取过来,进行sort和combiner。
下面我们用图形,把mapredcue的过程重新理一理
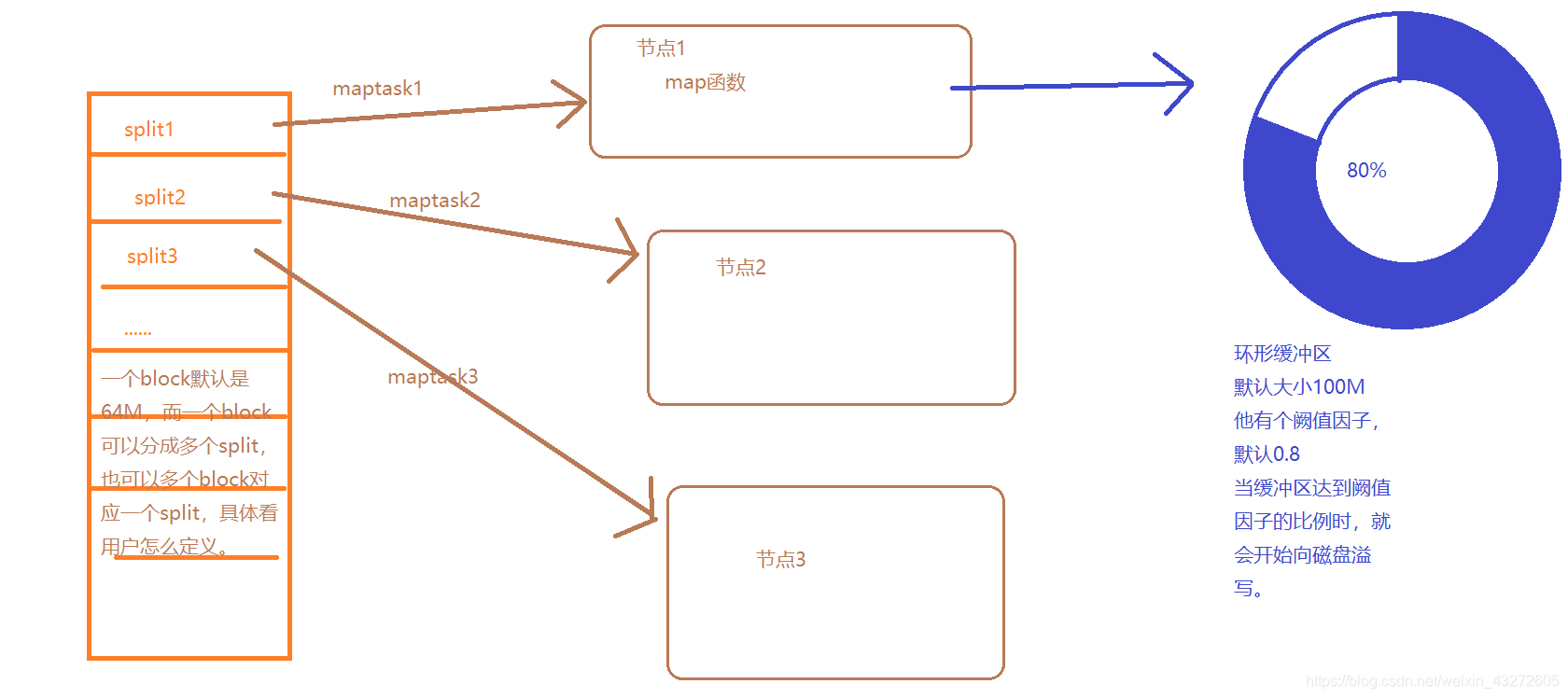
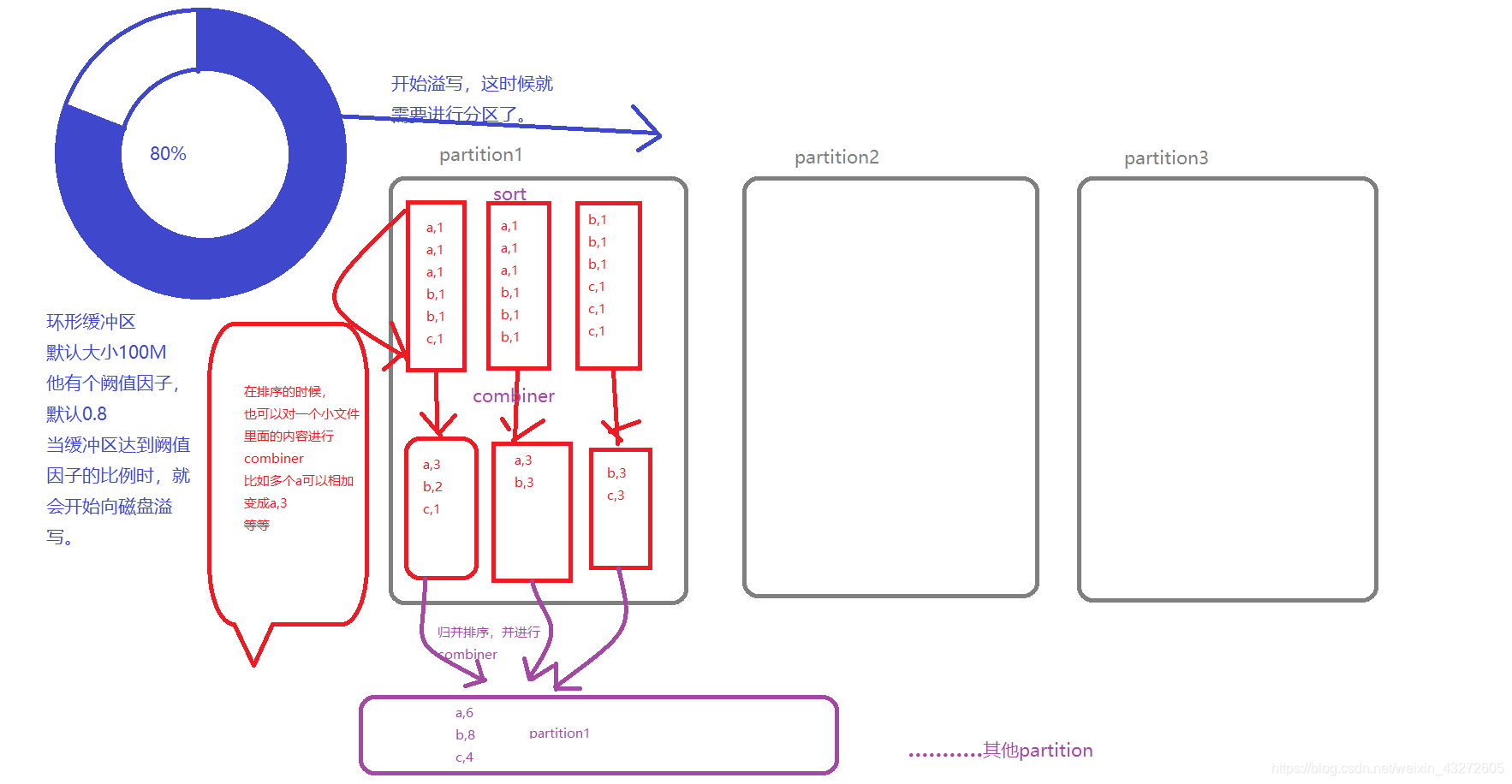
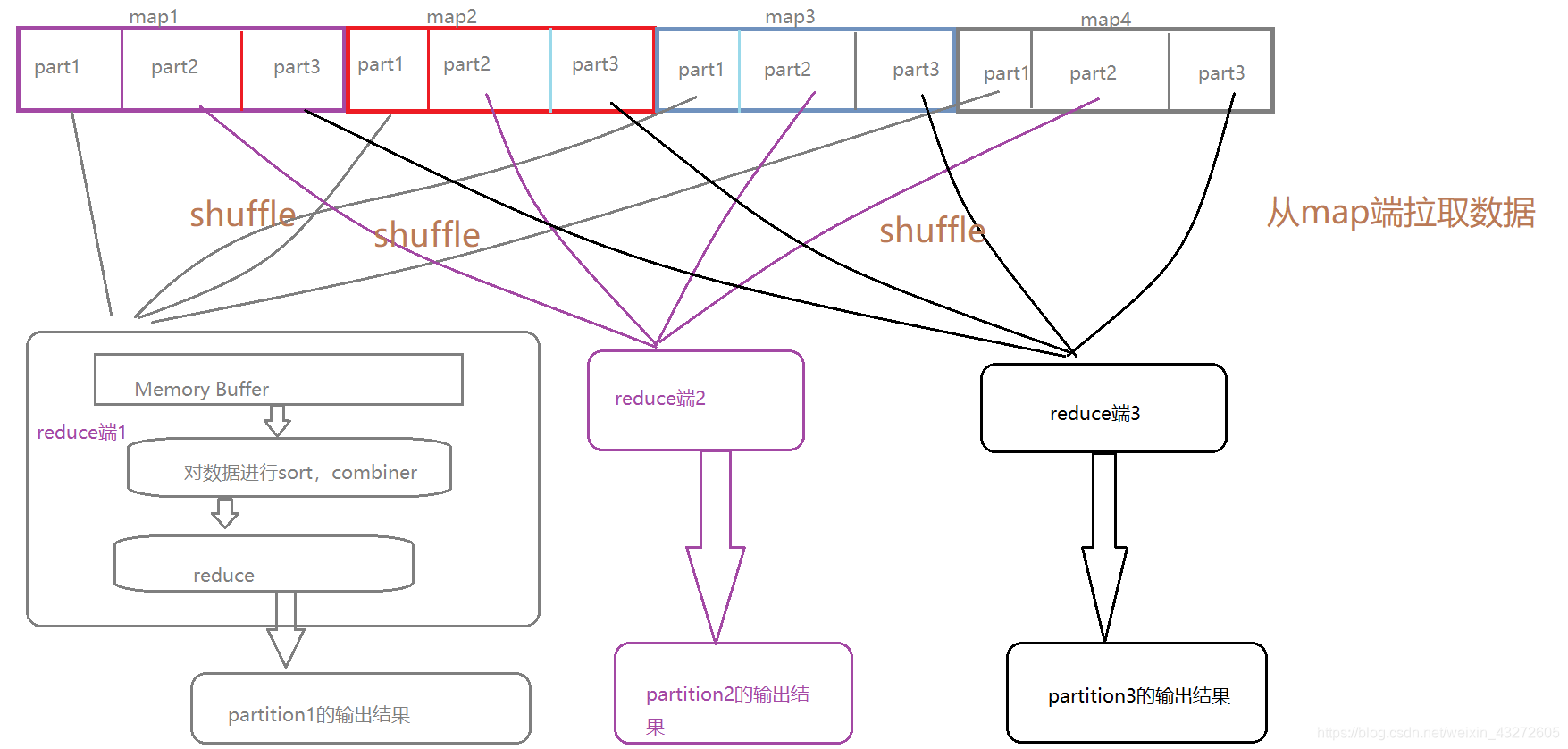
上面就用更详细的图,描述了具体过程,当然每个细节还有各种参数可以设置,也有很多注意点,以后遇到就慢慢探究。
比较重要的就是combiner,partition还有sort。
mapreduce的优化也是从这里进行优化的,拖慢mapreduce速度的就是shuffle的网络通信。我们可以想办法适当减少通信量来加快mapreduce执行速度。
wordcount例子
map程序
package com.hadoop.mapreduce;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class TestMapper extends Mapper<LongWritable, Text,Text,LongWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();//先将Text类型转换为String
String[] words = line.split(" ");//对每一行的数据以空格分割
for(String word:words){
context.write(new Text(word),new LongWritable(1));//将每一个单词以(word,1)的形式写出去。
}
}
}
reduce程序
package com.hadoop.mapreduce;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.util.Iterator;
public class TestRuduce extends Reducer<Text, LongWritable,Text,LongWritable> {
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
long num = 0;
Iterator<LongWritable> iterator = values.iterator();
while(iterator.hasNext()){
num=num+iterator.next().get();//将每个迭代的加起来,就可以得出总的单词个数
}
System.out.println(key+" "+num);
context.write(key,new LongWritable(num));
}
}Runner
package com.hadoop.mapreduce;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class Runner {
//这个类就是程序的入口了
public static void main(String[] args) {
Configuration conf = new Configuration();
conf.set("fs.defaultFS","hdfs://192.168.40.138:9000");
//新建1一个job任务
try {
Job job = Job.getInstance(conf);
//设置jar包
job.setJarByClass(Runner.class);
//指定mapper和reducer
job.setMapperClass(TestMapper.class);
job.setReducerClass(TestRuduce.class);
//设置map端输出类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//设置reduce的输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
//指定mapreduce程序的输入和输出路径
Path inputPath = new Path("/wordcount/input");//这里是hdfs的路径,首先要将input这个文件传到hdfs上去
Path outputPath = new Path("/wordcount/output");//这里也是hdfs路径,我们查看结果也需要在hdfs上查看。
FileInputFormat.setInputPaths(job,inputPath);//设置输入路径,这里的输入路径和输出路径都mport org.apache.hadoop.mapreduce.lib.input下的,一定不要使用mapred下的,那是老包了,不要使用。
FileOutputFormat.setOutputPath(job,outputPath);//设置输出路径
//退后提交任务
boolean waitForCompletion = job.waitForCompletion(true);
System.exit(waitForCompletion?0:1);
} catch (IOException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号