
Python 将多个DataFrame合并到一个Excel工作表的sheet中有几种方法
在Python中,将多个DataFrame合并到一个Excel工作表的sheet中有几种方法。以下是常见的几种实现方式:
方法1:直接合并DataFrame后保存
import pandas as pd
# 示例数据
df1 = pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6]})
df2 = pd.DataFrame({'C': [7, 8, 9], 'D': [10, 11, 12]})
df3 = pd.DataFrame({'E': [13, 14, 15], 'F': [16, 17, 18]})
# 方法1.1:纵向合并(行合并)
result = pd.concat([df1, df2, df3], axis=0) # axis=0 按行合并
result.to_excel('merged_vertical.xlsx', index=False, sheet_name='Merged_Data')
# 方法1.2:横向合并(列合并)
result = pd.concat([df1, df2, df3], axis=1) # axis=1 按列合并
result.to_excel('merged_horizontal.xlsx', index=False, sheet_name='Merged_Data')实践:
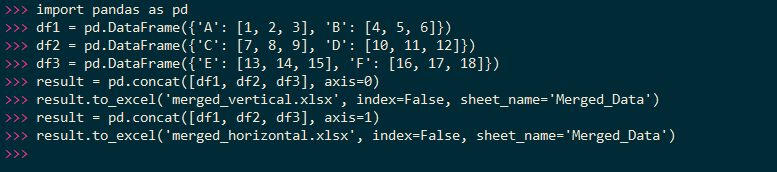
merged_vertical.xlsx 文件:
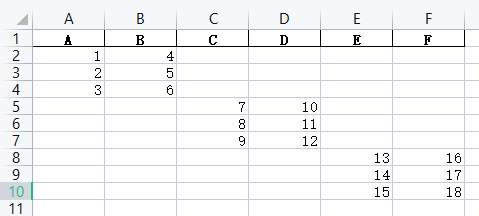
merged_horizontal.xlsx文件:

方法2:使用ExcelWriter进行更灵活的控制
import pandas as pd
from openpyxl import load_workbook
from openpyxl.utils.dataframe import dataframe_to_rows
# 示例数据
df1 = pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6]})
df2 = pd.DataFrame({'C': [7, 8, 9], 'D': [10, 11, 12]})
df3 = pd.DataFrame({'E': [13, 14, 15], 'F': [16, 17, 18]})
# 创建一个新的Excel文件
with pd.ExcelWriter('merged_data.xlsx', engine='openpyxl') as writer:
# 先写入第一个DataFrame
df1.to_excel(writer, sheet_name='Combined', index=False, startrow=0)
# 获取当前工作表
workbook = writer.book
worksheet = writer.sheets['Combined']
# 计算下一个DataFrame的起始位置
start_row = len(df1) + 2 # +2是为了在DataFrame之间留一个空行
# 写入第二个DataFrame
df2.to_excel(writer, sheet_name='Combined', index=False, startrow=start_row)
# 更新起始位置
start_row += len(df2) + 2
# 写入第三个DataFrame
df3.to_excel(writer, sheet_name='Combined', index=False, startrow=start_row)方法3:使用openpyxl直接操作
import pandas as pd
from openpyxl import Workbook
from openpyxl.utils.dataframe import dataframe_to_rows
def merge_dataframes_to_sheet(dataframes, filename, sheet_name='Merged_Data'):
"""
将多个DataFrame合并到一个Excel工作表中
Parameters:
dataframes: list of DataFrames - 要合并的DataFrame列表
filename: str - 输出文件名
sheet_name: str - 工作表名称
"""
# 创建工作簿和工作表
wb = Workbook()
ws = wb.active
ws.title = sheet_name
current_row = 1
for i, df in enumerate(dataframes):
# 添加DataFrame名称作为标题(可选)
if hasattr(df, 'name') and df.name:
ws.cell(row=current_row, column=1, value=f"DataFrame: {df.name}")
current_row += 1
# 写入DataFrame数据
for r in dataframe_to_rows(df, index=False, header=True):
for c, value in enumerate(r, 1):
ws.cell(row=current_row, column=c, value=value)
current_row += 1
# 在DataFrame之间添加空行(除了最后一个)
if i < len(dataframes) - 1:
current_row += 1
# 保存文件
wb.save(filename)
# 使用示例
df1 = pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6]})
df2 = pd.DataFrame({'C': [7, 8, 9], 'D': [10, 11, 12]})
df3 = pd.DataFrame({'E': [13, 14, 15], 'F': [16, 17, 18]})
merge_dataframes_to_sheet([df1, df2, df3], 'merged_dataframes.xlsx')方法4:更高级的合并函数
import pandas as pd
from openpyxl import Workbook
from openpyxl.styles import Font, Alignment
from openpyxl.utils.dataframe import dataframe_to_rows
def advanced_merge_to_sheet(dataframes, filename, sheet_name='Merged_Data',
add_titles=True, spacing=1):
"""
高级合并函数,支持更多自定义选项
Parameters:
dataframes: list of DataFrames - 要合并的DataFrame列表
filename: str - 输出文件名
sheet_name: str - 工作表名称
add_titles: bool - 是否添加DataFrame标题
spacing: int - DataFrame之间的空行数
"""
wb = Workbook()
ws = wb.active
ws.title = sheet_name
current_row = 1
for i, df in enumerate(dataframes):
# 添加标题
if add_titles:
title_cell = ws.cell(row=current_row, column=1,
value=f"DataFrame {i+1}")
title_cell.font = Font(bold=True, size=12)
title_cell.alignment = Alignment(horizontal='left')
current_row += 1
# 写入表头
header_row = list(df.columns)
for col_idx, header in enumerate(header_row, 1):
cell = ws.cell(row=current_row, column=col_idx, value=header)
cell.font = Font(bold=True)
current_row += 1
# 写入数据
for _, row in df.iterrows():
for col_idx, value in enumerate(row, 1):
ws.cell(row=current_row, column=col_idx, value=value)
current_row += 1
# 添加间距
if i < len(dataframes) - 1:
current_row += spacing
# 自动调整列宽
for column in ws.columns:
max_length = 0
column_letter = column[0].column_letter
for cell in column:
try:
if len(str(cell.value)) > max_length:
max_length = len(str(cell.value))
except:
pass
adjusted_width = (max_length + 2)
ws.column_dimensions[column_letter].width = adjusted_width
wb.save(filename)
# 使用示例
df1 = pd.DataFrame({'姓名': ['张三', '李四', '王五'], '年龄': [25, 30, 35]})
df2 = pd.DataFrame({'城市': ['北京', '上海', '广州'], '工资': [10000, 12000, 9000]})
df3 = pd.DataFrame({'部门': ['技术部', '销售部', '人事部'], '工龄': [3, 5, 2]})
advanced_merge_to_sheet([df1, df2, df3], 'advanced_merged.xlsx',
add_titles=True, spacing=2)方法5:使用xlsxwriter引擎
import pandas as pd
def merge_with_xlsxwriter(dataframes, filename, sheet_name='Merged_Data'):
"""
使用xlsxwriter引擎合并DataFrame
"""
with pd.ExcelWriter(filename, engine='xlsxwriter') as writer:
workbook = writer.book
worksheet = workbook.add_worksheet(sheet_name)
start_row = 0
for i, df in enumerate(dataframes):
# 写入DataFrame
df.to_excel(writer, sheet_name=sheet_name,
startrow=start_row, index=False)
# 更新起始行位置
start_row += len(df) + 2 # +2 用于表头和空行
# 使用示例
df1 = pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6]})
df2 = pd.DataFrame({'C': [7, 8, 9], 'D': [10, 11, 12]})
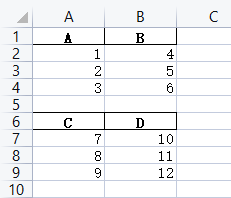
merge_with_xlsxwriter([df1, df2], 'xlsxwriter_merged.xlsx')水平合并,xlsxwriter_merged.xlsx 文件结果:
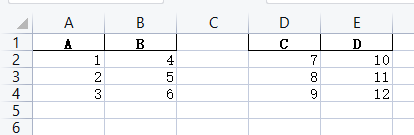
纵向合并:
def merge_with_xlsxwriter(dataframes, filename, sheet_name='Merged_Data'):
"""
使用xlsxwriter引擎合并DataFrame
"""
with pd.ExcelWriter(filename, engine='xlsxwriter') as writer:
workbook = writer.book
worksheet = workbook.add_worksheet(sheet_name)
start_col = 0
for i, df in enumerate(dataframes):
# 写入DataFrame
df.to_excel(writer, sheet_name=sheet_name, startcol=start_col, index=False)
start_col += len(df.columns) + 1 # 获取列数,中间空1列,更新起始列位置
# 使用示例
df1 = pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6]})
df2 = pd.DataFrame({'C': [7, 8, 9], 'D': [10, 11, 12]})
merge_with_xlsxwriter([df1, df2], 'xlsxwriter_merged.xlsx')运行结果:
选择哪种方法取决于你的具体需求:
-
方法1:适合简单的行或列合并
-
方法2:适合需要精确控制位置的情况
-
方法3:提供最大的灵活性
-
方法4:适合需要格式化的专业输出
-
方法5:适合使用xlsxwriter的高级功能
根据你的具体需求选择最合适的方法即可。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号