Unix C:进程
进程:程序执行时的一个实例
- 程序是被存储在磁盘上,包含机器指令和数据的文件
- 当这些指令和数据被装载到内存并被CPU所执行,即形成了进程
- 一个程序可以被同时运行为多个进程
- 在LINUX源码中通常将进程称为任务(task)
- 从内核观点看,进程的目的就是担当分配系统资源(CPU时间、内存等)的实体
进程相关概念
查看进程相关命令
-
pstree以树状结构显示当前所有进程关系 -
ps以简略方式显示当前用户拥有控制终端的进程信息,也可以配合以下选项a- 显示所有用户拥有控制终端的进程信息x- 也包括没有控制终端的进程r- 只显示正在运行的进程u- 以详尽方式显示w- 以更大列宽显示-e- 显示所有进程-f- 全格式-l- 长格式
ps aux # 查看全部进程,以用户为主的格式显示进程情况 ps ef # 显示出linux机器所有详细的进程信息 ps aux | grep bash
进程信息列表
- user :进程的用户ID
- PID :进程ID
- %CPU :CPU使用率
- %MEM :内存使用率
- VSZ :占用虚拟内存大小(KB)
- RSS :占用物理内存大小(KB)
- TTY :终端次设备号
- STAT :进程状态
- R - 运行,即正在被处理器执行
- S - 可唤醒睡眠,系统中断、获得资源、收到信号都可唤醒
- D - 不可唤醒睡眠,只能被wake_up系统调用唤醒
- T - 收到SIGSTOP(19)信号进入暂停,收到SIGCONT(18)信号后继续运行
- Z - 僵尸进程,已终止但其终止状态未被回收
- < - 高优先级
- N - 低优先级
- L - 存在被锁定的内存分页
- s - 会话首进程
- l - 多线程化进程
- + - 在前台进程组中
- START :进程开始时间
- TIME :进程运行时间
- COMMAND :进程启动命令
父子进程
-
Unix系统中的进程存在父子关系。
- 一个父进程可以创建一到多个子进程,但每个子进程有且仅有一个父进程。
- 整个系统中只有一个根进程,即PID为0的调度进程
-
父进程创建子进程以后,子进程在操作系统的调度下与其父进程同时运行.
- 如果父进程先于子进程终止,子进程即成为孤儿进程
- 孤儿进程会被某个特定的进程收养,即成为该特定进程的子进程,因此该特定进程又被称为孤儿院进程
-
父进程创建子进程以后,子进程在操作系统的调度下与其父进程同时运行。
- 如果子进程先终止,但父进程由于某种原因没有回收子进程的终止状态,则子进程成为僵尸进程
- 僵尸进程虽然不再活动,但其所携带的进程终止状态会消耗内存资源。
进程标识
- 每个进程都有一个非负整数形式的唯一编号,即
PID(Process Identification)PID在任何时刻都是唯一的,当进程终止并被回收后,其PID就可以为其他新进程所用- 进程的
PID由系统内核根据延迟重用算法生成,确保新进程的PID不同于最近终止进程的PID
- 专用PID:
- 0号进程,调度进程,亦称交换进程(swapper),系统内核的一部分,所有进程的根进程,磁盘上没有它的可执行程序文件
- 1号进程,
init进程,在系统自举过程结束时由调度进程创建,读写与系统有关的初始化文件,引导系统至一个特定状态,以超级用户特权运行的普通进程,永不终止 - 除调度进程外,系统中每个进程都有唯一的父进程,子进程的
PPID``就是父进程的PID`
进程ID相关函数
#include<unistd.h>
pid_t getpid(void); //返回调用进程的PID
pid_t getppid(void); //返回调用进程的父进程PID
uid_t getuid(void); //返回调用进程的实际用户ID
gid_t getgid(void); //返回调用进程的实际组ID
uid_t geteuid(void); //返回调用进程的有效用户ID
gid_t getegid(void); //返回调用进程的有效组ID
进程的创建
fork函数
#include<unistd.h>
pid_t fork(void);
- 功能:创建调用进程的子进程(child process)
- 返回值::fork函数被调用一次,但返回两次。子进程的返回值是
0,父进程的返回值则是新建子进程的进程PID。如果失败则返回-1,并设置errno。和setjmp类似,fork语句后常常跟上分支语句进行判断。 - 系统中的总线程数达到了上限,或者用户总进程数达到了上限时,fork函数会返回失败。
- 线程上限:/proc/sys/kernel/threads-max
- 进程上限:ulimit -u
- 子进程不继承父进程的未决信号和文件锁
为父子进程设计不同的执行过程
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/types.h>
int main(void){
printf("[%d]:Begin!\n", getpid());
pid_t pid = fork();
// ---------------------------
// 父进程调用fork后,父子进程都从这里开始执行
if(pid == -1){
perror("fork"); //创建失败,返回错误信息
return -1;
}
if(pid == 0){
//子进程的执行代码
printf("[%d]:Child is working!\n", getpid());
}
else{
//父进程的执行代码
printf("[%d]:Parent is working!\n", getpid());
}
printf("[%d]:End!\n", getpid());//父子进程都可执行的代码
return 0;
}
cwork$ ./fork1
[36795]:Begin!
[36795]:Parent is working!
[36795]:End!
[36796]:Child is working!
[36796]:End!
fork产生的子进程是其父进程的不完全副本,子进程在内存中的映像除了代码区与父进程共享同一块物理内存,其他各区映射到独立的物理内存,但其内容从父进程拷贝
fork函数返回后,系统内核会将父进程维护的文件描述符表也复制到子进程的进程表项中,但并不复制文件表项
//子进程是父进程的副本
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
int global = 10;//数据区
int main(void){
int local = 20;//栈区
int* heap = malloc(sizeof(int));//堆区
*heap = 30;
printf("%d进程:%p:%d %p:%d %p:%d\n",getpid(),
&global,global,&local,local,heap,*heap);
//创建子进程
pid_t pid = fork();
if(pid == -1){
perror("fork");
return -1;
}
//子进程代码
if(pid == 0){
printf("%d进程:%p:%d %p:%d %p:%d\n",getpid(),
&global,++global,&local,++local,heap,++*heap);
return 0;
}
//父进程代码
sleep(1);//延时
printf("%d进程:%p:%d %p:%d %p:%d\n",getpid(),
&global,global,&local,local,heap,*heap);
return 0;
}
子进程会复制父进程的文件描述符表
//子进程会复制父进程的文件描述符表
#include<stdio.h>
#include<string.h>
#include<unistd.h>
#include<fcntl.h>
int main(void){
//父进程打开文件,得到文件描述符
int fd=open("./ftab.txt",O_WRONLY|O_CREAT|O_TRUNC,0664);
if(fd == -1){
perror("open");
return -1;
}
//父进程向文件中写入数据 hello world!
char* buf = "hello world!";
if(write(fd,buf,strlen(buf)) == -1){
perror("write");
return -1;
}
//父进程创建子进程
pid_t pid = fork();
if(pid == -1){
perror("fork");
return -1;
}
//子进程代码,修改文件读写位置
if(pid == 0){
if(lseek(fd,-6,SEEK_END) == -1){
perror("lseek");
return -1;
}
close(fd);
return 0;
}
//父进程代码,再次写入数据 linux!
sleep(1);
buf = "linux!";
if(write(fd,buf,strlen(buf)) == -1){
perror("write");
return -1;
}
close(fd);
return 0;
}
一般来说,在fork之后是父进程先执行还是子进程先执行是不确定的,这取决于内核所使用的调度算法。
如果在main函数return返回前添加一行:
getchar();
使得父子进程都暂停,再使用命令:
ps axf
可以看到两个进程与bash的关系如下:

程序实例2——
fflush的重要性
对于上述程序的结果,注意到Begin只打印了一次:
[root@HongyiZeng proc]# ./fork1
[16023]:Begin!
[16023]:Parent is working!
[16023]:End!
[16024]:Child is working!
[16024]:End!
如果将该打印信息重定向至某个文件:
./fork1 > /tmp/out
再查看该文件的内容:
cwork$ cat /tmp/out
[18060]:Begin!
[18060]:Parent is working!
[18060]:End!
[18060]:Begin!
[18061]:Child is working!
[18061]:End!
注意到Begin打印了两次。
原因:对于重定向至文件,采用的是全缓冲(除标准输出和标准错误输出),只有进程结束或者缓冲满的时候才刷新缓冲区(遇到换行符不刷新),将缓冲区的内容写入到文件。因此,父进程fork时,尚未刷新缓冲区,因此缓冲区的内容[18060]:Begin!(注意进程号已经固定了!)被复制到子进程的缓冲区中,当父子进程执行结束时,强制刷新,输出两次[18060]:Begin!。
为防止缓冲区内容被复制,父进程在fork之前需要强制刷新所有已经打开的流:
int main(void) {
pid_t pid;
printf("[%d]:Begin!\n", getpid());
// 强制刷新所有打开的流!!!
fflush(NULL);
// 再调用fork
pid = fork();
// ---------------------------
// 父进程调用fork后,父子进程都从这里开始执行
// ...
}
此时,只打印了一句Begin:
[root@HongyiZeng proc]# ./fork1 > /tmp/out
[root@HongyiZeng proc]# cat /tmp/out
[19853]:Begin!
[19853]:Parent is working!
[19853]:End!
[19854]:Child is working!
[19854]:End!
程序实例3——找质数
需求:找出30000000~30000200的所有质数。
- 单进程版:
#include <stdio.h>
#include <stdlib.h>
#define LEFT 30000000
#define RIGHT 30000200
int main(void) {
int i, j, mark;
for(i = LEFT; i <= RIGHT; i++) {
mark = 1;
for(j = 2; j < i/2; j++) {
if(i % j == 0) {
mark = 0;
break;
}
}
if(mark)
printf("%d is a primer.\n", i);
}
exit(0);
}
打印结果:
[root@HongyiZeng proc]# time ./primer0
30000001 is a primer.
30000023 is a primer.
30000037 is a primer.
30000041 is a primer.
30000049 is a primer.
30000059 is a primer.
30000071 is a primer.
30000079 is a primer.
30000083 is a primer.
30000109 is a primer.
30000133 is a primer.
30000137 is a primer.
30000149 is a primer.
30000163 is a primer.
30000167 is a primer.
30000169 is a primer.
30000193 is a primer.
30000199 is a primer.
real 0m0.967s
user 0m0.950s
sys 0m0.001s
- 多进程协同:
#include <stdio.h>
#include <stdlib.h>
#define LEFT 30000000
#define RIGHT 30000200
int main(void) {
int i, j, mark;
pid_t pid;
for(i = LEFT; i <= RIGHT; i++) {
pid = fork();
if(pid < 0) {
perror("fork()");
exit(1);
}
if(pid == 0) { // child
mark = 1;
for(j = 2; j < i/2; j++) {
if(i % j == 0) {
mark = 0;
break;
}
}
if(mark)
printf("%d is a primer.\n", i);
// 子进程退出
return 0;
//此处若不退出,则子进程执行完`pid==0`的分支后,又会执行`for`循环的部分,此时会再次`fork`,导致进程数量指数式的增长,超出可用内存
}
}
return 0;
}
执行结果:
[root@HongyiZeng proc]# time ./primer1
30000037 is a primer.
30000071 is a primer.
30000059 is a primer.
30000079 is a primer.
30000083 is a primer.
30000049 is a primer.
30000023 is a primer.
30000137 is a primer.
30000149 is a primer.
30000041 is a primer.
30000167 is a primer.
30000193 is a primer.
30000109 is a primer.
30000001 is a primer.
30000199 is a primer.
30000169 is a primer.
30000163 is a primer.
30000133 is a primer.
real 0m0.048s
user 0m0.001s
sys 0m0.008s
资源的获取和控制
获取或设置资源使用限制:linux下每种资源都有相关的软硬限制,软限制是内核强加给相应资源的限制值,硬限制是软限制的最大值。
非授权调用的进程只能将其软限制指定为0~硬限制范围中的某个值,同时能不可逆转地降低其硬限制。
授权进程(root用户)可以任意改变其软硬限制。
函数原型:
#include <sys/time.h>
#include <sys/resource.h>
int getrlimit(int resource, struct rlimit *rlim);
int setrlimit(int resource, const struct rlimit *rlim);
rlimit结构体定义如下:
struct rlimit {
rlim_t rlim_cur; // 软限制
rlim_t rlim_max; // 硬限制
};
resource的选择有:
RLIMIT_AS //进程的最大虚内存空间,字节为单位。
RLIMIT_CORE //内核转存文件的最大长度。
RLIMIT_CPU //最大允许的CPU使用时间,秒为单位。当进程达到软限制,内核将给其发送SIGXCPU信号,这一信号的默认行为是终止进程的执行。然而,可以捕捉信号,处理句柄可将控制返回给主程序。如果进程继续耗费CPU时间,核心会以每秒一次的频率给其发送SIGXCPU信号,直到达到硬限制,那时将给进程发送 SIGKILL信号终止其执行。
RLIMIT_DATA //进程数据段的最大值。
RLIMIT_FSIZE //进程可建立的文件的最大长度。如果进程试图超出这一限制时,核心会给其发送SIGXFSZ信号,默认情况下将终止进程的执行。
RLIMIT_LOCKS //进程可建立的锁和租赁的最大值。
RLIMIT_MEMLOCK //进程可锁定在内存中的最大数据量,字节为单位。
RLIMIT_MSGQUEUE //进程可为POSIX消息队列分配的最大字节数。
RLIMIT_NICE //进程可通过setpriority() 或 nice()调用设置的最大完美值。
RLIMIT_NOFILE //指定比进程可打开的最大文件描述词大一的值,超出此值,将会产生EMFILE错误。
RLIMIT_NPROC //用户可拥有的最大进程数。
RLIMIT_RTPRIO //进程可通过sched_setscheduler 和 sched_setparam设置的最大实时优先级。
RLIMIT_SIGPENDING //用户可拥有的最大挂起信号数。
RLIMIT_STACK //最大的进程堆栈,以字节为单位。
返回值:
- 成功执行时,返回0。失败返回-1,errno被设为以下的某个值
EFAULT:rlim指针指向的空间不可访问EINVAL:参数无效EPERM:增加资源限制值时,权能不允许
孤儿进程
在子进程在退出前,先sleep(1000),这样父进程会先执行完毕而退出。
// 孤儿进程演示
#include<stdio.h>
#include<unistd.h>
int main(void){
//父进程创建子进程
pid_t pid = fork();
if(pid == -1){
perror("fork");
return -1;
}
//子进程代码
if(pid == 0){
printf("我的父进程是%d\n",getppid());
sleep(2);
printf("我的父进程是%d\n",getppid());
return 0;
}
//父进程代码
sleep(1);
return 0;
}
再使用命令ps axf查看:

此时201个子进程的状态为S(可中断的睡眠状态),且父进程为init进程(每个进程以顶格形式出现)。这里的子进程在init进程接管之前就是孤儿进程。
孤儿进程:一个父进程退出,而它的一个或多个子进程还在运行,那么这些子进程将成为孤儿进程。孤儿进程将被 init 进程所收养,并由 init 进程对它们完成状态收集工作,孤儿进程并不会有什么危害。
孤儿院进程
当一个子进程的父进程先于子进程结束时,子进程就会成为孤儿进程。这些孤儿进程通常由init进程(在Linux系统中为1号进程)收养,成为init进程的子进程。init进程就像一个孤儿院,专门负责处理孤儿进程的善后工作。每当出现一个孤儿进程时,内核将孤儿进程的父进程设置为init,而init进程会循环地wait()它的已经退出的子进程。这样,当一个孤儿进程凄凉地结束了其生命周期的时候,init进程就会代表党和政府出面处理它的一切善后工作。孤儿进程并不会有什么危害。
使用ps -eo pid,ppid,cmd |grep ./a.out命令查询孤儿进程的父进程ppid,然后根据ppid可以查看到此LINUX版本中孤儿进程被/sbin/upstart进程接管了
~$ ps -eo pid,ppid,cmd |grep ./a.out
36953 1669 ./a.out
36954 1669 ./a.out
36955 1669 ./a.out
~$ ps aux |grep 1669
tarena 1669 0.0 0.1 53720 4808 ? Ss 12月17 0:00 /sbin/upstart --user
tarena 37198 0.0 0.0 15984 924 pts/2 S+ 15:31 0:00 grep --color=auto 1669

僵尸进程
在父进程退出之前,先休眠1000s,再查看进程状态。
int main(void) {
int i, j, mark;
pid_t pid;
for(i = LEFT; i <= RIGHT; i++) {
pid = fork();
if(pid < 0) {
perror("fork()");
exit(1);
}
if(pid == 0) {
mark = 1;
for(j = 2; j < i/2; j++) {
if(i % j == 0) {
mark = 0;
break;
}
}
if(mark)
printf("%d is a primer.\n", i);
exit(0);
}
}
// 父进程睡眠1000s再退出
sleep(1000);
exit(0);
}
执行结果:
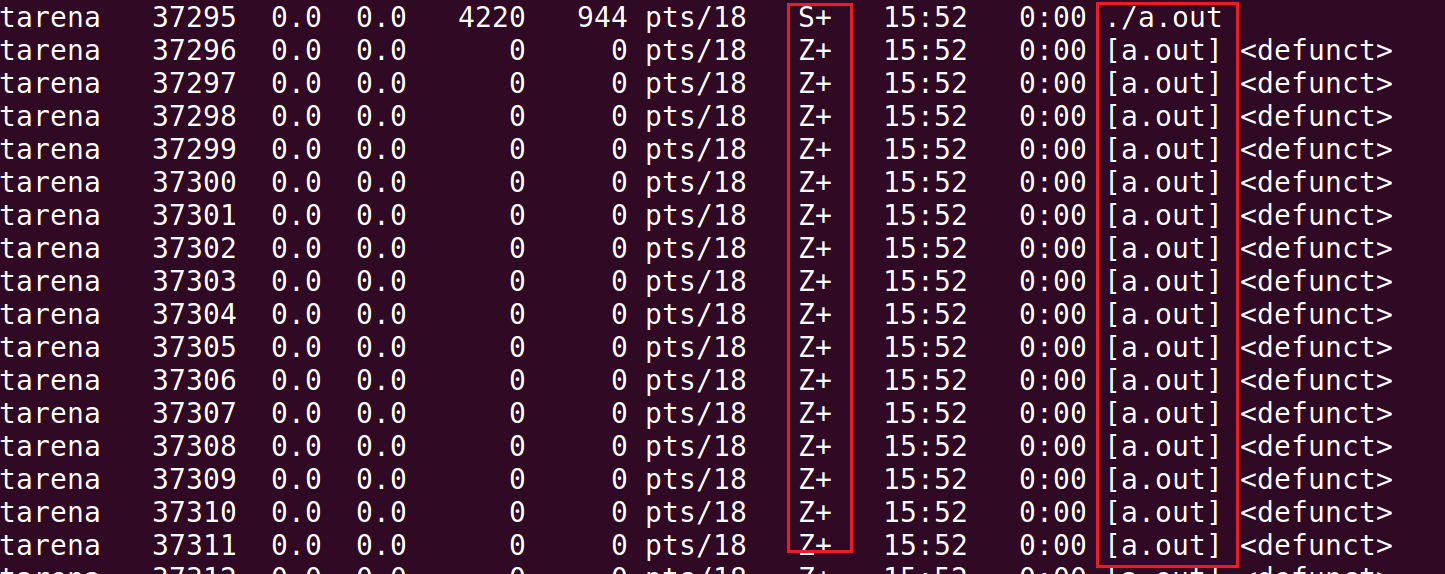
- 可以看到子进程状态:
Z,即为僵尸状态;+表示进程在前台运行;<defunct>: 这表示进程是“僵尸”状态,即它已经终止,但其父进程还未对其进行清理(通常是调用wait()或waitpid()函数)。
僵尸进程:一个进程使用 fork 创建子进程,如果子进程退出,而父进程并没有调用 wait 或 waitpid 获取子进程的状态信息(收尸),那么子进程的进程描述符仍然保存在系统中,这种进程称之为僵尸进程。
僵尸进程虽然不占有任何内存空间,但如果父进程不调用 wait() / waitpid() 的话,那么保留的信息就不会释放,其进程号就会一直被占用,而系统所能使用的进程号是有限的,如果大量的产生僵死进程,将因为没有可用的进程号而导致系统不能产生新的进程,此即为僵尸进程的危害。
避免产生僵尸进程的方式
-
僵尸进程的危害:当一个进程已经结束,但是系统没有把它的进程的数据结构完全释放
- 此时
PS查看其状态为defunct。 - 僵尸进程占据进程表的空间,而且不能被kill掉,因为它已经终止了,只是资源未被回收
- 所以在开发多进程尤其是守护进程时注意要避免产生僵尸进程。
- 此时
-
产生原因:子进程先于父进程退出,且父进程没有给子进程收尸。
-
和孤儿进程的区别:就是爸爸(父进程)和儿子(子进程)谁先死的问题
- 父进程结束后,子进程还未终止则成为孤儿进程,孤儿进程终止后由
init进程或其他孤儿院进程来回收。 - 父进程还在运行,但子进程终止但未被父进程回收,则子进程就会变成僵尸进程。
- 父进程结束后,子进程还未终止则成为孤儿进程,孤儿进程终止后由
-
SIGCHLD信号:当子进程退出时发送给父进程,默认动作是忽略。
方式1:
父进程调用wait/waitpid等函数等待子进程结束,如果尚无子进程退出wait会导致父进程阻塞。waitpid可以通过传递WNOHANG使父进程不阻塞立即返回。
方式2:
通过两次调用fork。父进程首先调用fork创建一个子进程然后waitpid等待子进程退出,子进程再fork一个孙进程后退出。这样子进程退出后会被父进程等待回收,而对于孙子进程其父进程已经退出所以孙进程成为一个孤儿进程,孤儿进程由init进程接管,孙进程结束后,由init等待回收。
int main(void) {
pid_t pid;
pid = fork();
if(pid < 0) {
perror("fork");
exit(1);
}
if(pid == 0) { // 子进程
pid_t newpid;
newpid = fork();
// 检错...
if(newpid == 0) { // 孙子进程
// 做自己的事情
}
exit(0); // 子进程退出
} else { // 父进程
waitpid(pid, NULL, 0); // 阻塞等待子进程退出
}
exit(0);
}
方式3
通过signal通知内核表明父进程对子进程的结束不关心,由内核回收。如果不想让父进程挂起,可以在父进程中加入一条语句:signal(SIGCHLD,SIG_IGN);表示父进程忽略SIGCHLD信号,该信号是子进程退出的时候向父进程发送的。该方式不会阻塞父进程。
int main(void) {
int i;
pid_t pid;
signal(SIGCHLD, SIG_IGN); // 显式的忽略SIGCHLD信号
for(i = 0; i < 10; i++)
{
if ((pid = fork()) == 0)
_exit(0);
}
sleep(10);
exit(0);
}
方式4
对子进程进行wait,释放它们的资源,但是父进程一般没工夫在那里守着,等着子进程的退出,所以,一般使用信号的方式来处理,在收到SIGCHLD信号的时候,在信号处理函数中调用wait操作来释放他们的资源。
void avoid_zombies_handler(int signo) {
pid_t pid;
int exit_status;
int saved_errno = errno;
while ((pid = waitpid(-1, &exit_status, WNOHANG)) > 0) {
/* do nothing */
}
errno = saved_errno;
}
int main(void) {
pid_t pid;
struct sigaction child_act;
memset(&child_act, 0, sizeof(struct sigaction));
child_act.sa_handler = avoid_zombies_handler; // 信号注册函数
child_act.sa_flags = SA_RESTART | SA_NOCLDSTOP;
sigemptyset(&child_act.sa_mask);
if(sigaction(SIGCHLD, &child_act, NULL) == -1) { // 注册失败
perror("sigaction error");
_exit(EXIT_FAILURE);
}
while(1) {
if ((pid = fork()) == 0) {/* child process */
_exit(0);
}else if (pid > 0); /* parent process */
}
_exit(EXIT_SUCCESS);
}
方式5
使用sigaction对SIGCHLD注册信号处理函数,并设置sa_flags标志位为SA_NOCLDWAIT,这样,当子进程终止时,子进程不会被设置为僵尸进程。
SA_NOCLDWAIT在man手册中的描述:
If signum is SIGCHLD, do not transform children into zombies when they terminate. See also waitpid(2). This flag is meaningful only when establishing a handler for SIGCHLD, or when setting that signal's disposition to SIG_DFL.
如果信号是SIGCHLD,不会在子进程终止时将他们变成僵尸。另请参见waitpid(2)。该标志仅在为SIGCHLD建立处理程序或将信号的处理设置为SIG_DFL时才有意义。
// 父进程
int main(void) {
struct sigaction sa, osa;
sigset_t set, oset;
// 避免子进程成为僵尸进程
sa.sa_handler = SIG_DFL; // 或者自己定义的处理程序
sigemptyset(&sa.sa_mask);
sa.sa_flags = SA_NOCLDWAIT;
sigaction(SIGCHLD, &sa, &osa);
// ...
}
父子进程之间的文件共享
fork的一个特性是父进程的所有打开文件描述符都被复制到子进程中。我们说“复制”是因为对每个文件描述符来说,就好像执行了dup函数。父进程和子进程每个相同的打开描述符共享一个文件表项。
考虑下述情况,一个进程具有3个不同的打开文件,它们是标准输入、标准输出和标准错误。在从fork返回时:
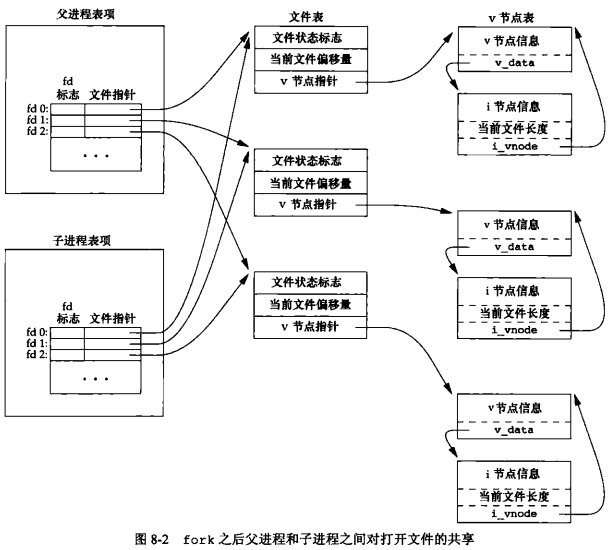
重要的一点是,父进程和子进程共享同一个文件偏移量。
-
考虑下述情况:
- 一个进程
fork了一个子进程,然后等待子进程终止。 - 假定,作为普通处理的一部分,父进程和子进程都向标准输出进行写操作。
- 如果父进程的标准输出已重定向(很可能是由 shell 实现的),那么子进程写到该标准输出时,它将更新与父进程共享的该文件的偏移量。
- 一个进程
-
在这个例子中,当父进程等待子进程时,子进程写到标准输出:而在子进程终止后,父进程也写到标准输出上,并且知道其输出会追加在子进程所写数据之后。如果父进程和子进程不共享同一文件偏移量,要实现这种形式的交互就要困难得多,可能需要父进程显式地动作。
-
如果父进程和子进程写同一描述符指向的文件,但又没有任何形式的同步(如使父进程等待子进程),那么它们的输出就会相互混合(假定所用的描述符是在fork之前打开的)。
-
在fork之后处理文件描述符有以下两种常见的情况:
- 父进程等待子进程完成。在这种情况下,父进程无需对其描述符做任何处理。当子进程终止后,它曾进行过读、写操作的任一共享描述符的文件偏移量已做了相应更新。
- 父进程和子进程各自执行不同的程序段。在这种情况下,在fork之后,父进程和子进程各自关闭它们不需使用的文件描述符,这样就不会干扰对方使用的文件描述符。这种方法是网络服务进程经常使用的。
vfork
考虑这样一个场景,父进程使用了一个占用内存很大的数据,此时它fork了一个子进程,而子进程仅仅打印一个字符串就退出了,此时这块很大的数据复制到子进程的内存空间中,造成了很大的内存浪费。
为了解决这个问题,在fork实现中,增加了读时共享,写时复制(Copy-On-Write,COW)的机制。写时复制可以避免拷贝大量根本就不会使用的数据(地址空间包含的数据多达数十兆)。因此可以看出写时复制极大提升了Linux系统下fork函数运行的性能。
写时复制指的是子进程的页表项指向与父进程相同的物理页,这也只需要拷贝父进程的页表项就可以了,不会复制整个内存地址空间,同时把这些页表项标记为只读。
- 读时共享:如果父子进程都不对页面进行操作或只读,那么便一直共享同一份物理页面。
- 写时复制:只要父子进程有一个尝试进行修改某一个页面(写时),那么就会发生缺页异常。那么内核便会为该页面创建一个新的物理页面,并将内容复制到新的物理页面中,让父子进程真正地各自拥有自己的物理内存页面,并将页表中相应地页表项标记为可写。
写时复制父子进程修改某一个页面前后变化如下图所示:
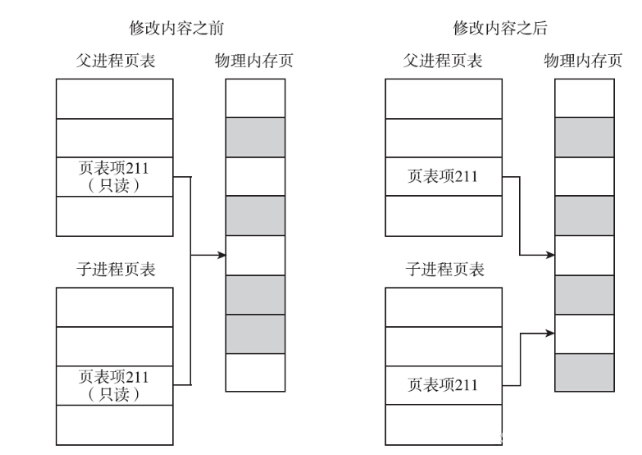
在fork还没实现copy on write之前。Unix设计者很关心fork之后立刻执行exec所造成的地址空间浪费,所以引入了vfork系统调用。而现在vfork已经不常用了。
vfork和fork的区别/联系:vfork函数和fork函数一样都是在已有的进程中创建一个新的进程,但它们创建的子进程是有区别的。- 父子进程的执行顺序
fork: 父子进程的执行次序不确定。vfork:保证子进程先运行,在它调用exec/exit之后,父进程才执行
- 是否拷贝父进程的地址空间
fork: 子进程写时拷贝父进程的地址空间,子进程是父进程的一个复制vfork:子进程共享父进程的地址空间
- 调用
vfork函数,是为了执行exec函数;如果子进程没有调用exec/exit,程序会出错
代码示例
int main(int argc, char *argv[]){
pid_t pid;
pid = vfork(); // 创建进程
if(pid < 0){
perror("vfork");
}
if(0 == pid){
sleep(3); // 延时 3 秒
printf("i am son\n");
_exit(0); // 退出子进程,必须
}
else if(pid > 0){ // 父进程
printf("i am father\n");
}
}
执行结果:已经让子进程延时 3 s,结果还是子进程运行结束后,父进程才执行
static int a = 10;
int main(void){
pid_t pid;
int b = 20;
pid = vfork();
if(pid < 0){
perror("vfork()");
exit(1);
}
if(0 == pid){
a = 100, b = 200;
printf("son: a = %d, b = %d\n", a, b);
_exit(0);
}
else if(pid > 0){
printf("father: a = %d, b = %d\n", a, b);
}
exit(0);
}
执行结果:子进程先执行,修改完a,b的值后,由于父子进程共享内存空间,因此会影响父进程
son: a = 100, b = 200
father: a = 100, b = 200
如果采用fork的话,会有写时复制,此时父子进程的变量无关:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
static int a = 10;
int main(void) {
pid_t pid;
int b = 20;
fflush(NULL);
pid = fork();
if(pid < 0) {
perror("fork()");
exit(1);
}
if(pid == 0) {
a = 100;
b = 200;
printf("son: a = %d, b = %d.\n", a, b);
_exit(0);
} else {
printf("father: a = %d, b = %d.\n", a, b);
}
exit(0);
}
执行结果:
[root@HongyiZeng proc]# ./vfork
father: a = 10, b = 20.
son: a = 100, b = 200.
exec函数族
fork函数是用于创建一个子进程,该子进程几乎是父进程的副本,而有时我们希望子进程去执行另外的程序,exec函数族就提供了一个在进程中启动另一个程序执行的方法。它可以根据指定的文件名或目录名找到可执行文件,并用它来取代原调用进程的数据段、代码段和堆栈段,在执行完之后,原调用进程的内容除了进程号外,其他全部被新程序的内容替换了。这里的可执行文件既可以是二进制文件,也可以是Linux下任何可执行脚本文件。
当进程调用一种exec函数时,该进程执行的程序完全替换为新程序,而新程序则从其main函数开始执行。因为调用exec并不创建新进程,所以前后的进程ID并未改变。exec只是用磁盘上的一个新程序替换了当前进程的正文段、数据段、堆段和栈段。
为什么需要
exec函数
fork子进程是为了执行新程序(fork创建了子进程后,子进程和父进程同时被OS调度执行,因此子进程可以单独的执行一个程序,这个程序宏观上将会和父进程程序同时进行);- 可以直接在子进程的
if中写入新程序的代码。这样可以,但是不够灵活,而且源代码太长了也不好控制。- 譬如说我们希望子进程来执行
ls -la命令就不行了(没有源代码,只有编译好的可执行程序/usr/bin/ls);
- 譬如说我们希望子进程来执行
- 使用
exec族运行新的可执行程序(exec族函数可以直接把一个编译好的可执行程序直接加载运行); - 我们有了
exec族函数后,典型的父子进程程序是这样的:- 子进程需要运行的程序被单独编写、单独编译连接成一个可执行程序(叫
hello),(项目是一个多进程项目)主程序为父进程 - 主程序
fork创建了子进程后在子进程中exec来执行hello,达到父子进程分别做不同程序同时(宏观上)运行的效果;
- 子进程需要运行的程序被单独编写、单独编译连接成一个可执行程序(叫
exec函数族的族使用
有多种不同的exec函数可供使用,它们常常被统称为exec函数。
#include <unistd.h>
extern char **environ;
// 直达
int execl(const char *path, const char *arg, ...);
// 从$PATH里找
int execlp(const char *file, const char *arg, ...);
// 直达
int execle(const char *path, const char *arg, ..., char * const envp[]);
// 直达
int execv(const char *path, char *const argv[]);
// 从$PATH里找
int execvp(const char *file, char *const argv[]);
// 从$PATH里找
int execvpe(const char *file, char *const argv[], char *const envp[]);
- 以上函数成功执行时不返回,失败时返回
-1并设值errno - 后缀含义
l:以list形式传入参数v:以vector形式传入参数p:在$PATH中查找可执行程序e:在envp[]中查找可执行程序
execl和execv:这两个函数是最基本的exec,都可以用来执行一个程序,区别是传参的格式不同:- execl是把参数列表(本质上是多个字符串,必须以
NULL结尾)依次排列而成 - execv是把参数列表事先放入一个字符串数组中(必须以
NULL结尾),再把这个字符串数组传给execv函数,类似于char **argv path:完整的文件目录路径
- execl是把参数列表(本质上是多个字符串,必须以
execlp和execvp:这两个函数在上面2个基础上加了pfile:文件名,系统就会自动从环境变量$PATH所指出的路径中进行查找该文件。如果包含/,则视为路径名path。
execle和execvpe:这两个函数较基本exec来说加了eenvp:自己指定的环境变量。在envp[]中指定当前进程所使用的环境变量替换掉该进程继承的环境变量$PATH。

代码示例——环境变量
myexec.c
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main(void) {
pid_t pid;
pid = fork();
if(pid < 0) {
perror("fork()");
exit(1);
} else if(pid == 0) { // 子进程
// 参数
char * const param[] = {"myHello", "-a", "-l", NULL};
// 自己设置的环境变量
char * const envp[] = {"AA=aaa", "BB=bbb", NULL};
// 执行同目录下的hello
execvpe("./hello", param, envp);
perror("execvpe()");
exit(1);
} else { // 父进程
wait(NULL);
}
exit(0);
}
hello.c
#include <stdio.h>
#include <stdlib.h>
int main(int argc, char **argv, char **env) {
printf("argc = %d\n", argc);
int i;
for(i = 0; argv[i] != NULL; i++) {
printf("argv[%d]: %s\n", i, argv[i]);
}
for(i = 0; env[i] != NULL; i++) {
printf("env[%d]: %s\n", i, env[i]);
}
exit(0);
}
编译链接为hello
执行结果:
[root@HongyiZeng proc]# ./myexec
argc = 3
argv[0]: myHello
argv[1]: -a
argv[2]: -l
env[0]: AA=aaa
env[1]: BB=bbb
代码示例——程序名称
补充:argv第一个参数为程序名称,后面的参数为命令行参数。程序名称可以任意设置,一般来说,如果一个源码文件的名称为XXX.c,则编译生成的可执行程序为XXX,此时运行,程序名称(argv[0])就是XXX
使用gcc默认编译链接得到的可执行文件名称为a.out,此时程序名称(argv[0])就是a.out。
使用exec族函数实现date +%s命令打印时间戳的功能。
[root@HongyiZeng proc]# date +%s
1670902531
这里的参数依次是程序名,+%s,NULL,注意第一个参数代表的是程序的名称,可以任意设置,类似于argv[0],之后的参数才是重要的命令行参数。
代码实现:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main(void) {
puts("Begin!");
// 注意这里的程序名称给了一个myDate
execl("/bin/date", "myDate", "+%s", NULL);
perror("execl()");
exit(1);
puts("End!");
exit(0);
}
或者使用execv:
int main(void) {
puts("Begin!");
char * const param[] = {"myDate", "+%s", NULL};
execv("/bin/date", param);
perror("execl()");
exit(1);
puts("End!");
exit(0);
}
执行结果:
[root@HongyiZeng proc]# ./ex
Begin!
1670902607
为什么不打印End!:执行exec后,原进程映像被替换成新的进程映像(即/bin/date程序),从main函数开始执行/bin/date的代码了。
我不再是我,我已成新的我。
让子进程睡眠1000s:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main(void) {
pid_t pid;
printf("[%d]Begin!\n", getpid());
fflush(NULL);
pid = fork();
if(pid < 0) {
perror("fork()");
exit(1);
}
if(pid == 0) {
// 注意这里的程序名称给了一个httpd
execl("/bin/sleep", "httpd", "1000", NULL);
perror("execl()");
exit(1);
}
wait(NULL);
printf("[%d]End!\n", getpid());
exit(0);
}
执行后查看:
ps axf
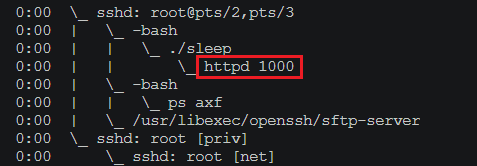
这里子进程运行时执行的是sleep程序,但是程序名称却被设置成了httpd,这实际上是一种低级的木马程序隐藏的办法。
代码示例——刷新缓冲区的重要性
在讲fork的时候提到过,在fork之前,最好将强制刷新所有已经打开的流,这里的exec也不例外,例如使用上面的程序,将结果重定向到/tmp/out中:
[root@HongyiZeng proc]# ./ex > /tmp/out
[root@HongyiZeng proc]# cat /tmp/out
1670902720
发现Begin!不见了,原因就在于重定向是全缓冲,当执行完puts("Begin!")后,该进程的缓冲区内容为Begin!\n,并不刷新到文件中,此时执行exec后,进程映像被替换成新的进程映像(即/bin/date程序),除了原进程的进程号外,其他全部(包括缓冲区)被新程序的内容替换了,之后新程序的缓冲区内容为时间戳,程序结束后,强制刷新到文件。
因此需要在执行exec之前强制刷新所有打开的流:
int main(void) {
puts("Begin!");
fflush(NULL);
execl("/bin/date", "date", "+%s", NULL);
perror("execl()");
exit(1);
puts("End!");
exit(0);
}
再次执行:
[root@HongyiZeng proc]# ./ex > /tmp/out
[root@HongyiZeng proc]# cat /tmp/out
Begin!
1670903209
代码示例——fork,exec和wait结合使用
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main(void) {
pid_t pid;
printf("[%d]Begin!\n", getpid());
fflush(NULL);
pid = fork();
if(pid < 0) {
perror("fork()");
exit(1);
}
if(pid == 0) { // 子进程
execl("/bin/date", "date", "+%s", NULL);
perror("execl()");
exit(1);
}
// 等待子进程结束,收尸
wait(NULL);
printf("[%d]End!\n", getpid());
exit(0);
}
执行结果:
[17301]Begin! // 父进程打印
1670903917 // 子进程打印,子进程和父进程完全是不同的程序了
[17301]End! // 父进程打印
至此,UNIX系统进程控制原语更加完善。用fork可以创建新进程,用exec可以初始执行新的程序。exit函数和wait函数处理终止和等待终止。这些是我们需要的基本的进程控制原语。
进程的终止
进程是内存中的代码和数据,而线程则是执行代码的过程。每个进出可以包含一个或多个线程,但至少需要一个主线程。每个线程都可以被看作是在一个独立的执行过程中调用了一个特殊的函数,谓之线程过程函数。线程开始时线程过程函数被调用,线程过程函数一旦返回,线程即终止。因此main函数也可以被看作是进程的主线程的线程过程函数。main函数一旦返回,主线程即终止,进程即终止。进程一旦终止,进程中的所有线程全部终止,这就是main函数的返回与其他函数返回在本质上的区别
main函数的返回值即进程的退出码,父进程可以在回收子进程的同时活动该退出码,以了解导致其终止的具体原因
共有8种方式让进程终止。其中5种为正常退出:
- 从main返回
- 调用
exit(C库函数) - 调用
_exit或_Exit(系统调用) - 最后一个线程从其启动例程返回
- 从最后一个线程调用
pthread_exit
异常终止有3种方式:
- 调用
abort - 接到一个信号
- 最后一个线程对取消请求做出响应
正常终止
exit函数
#include<stdio.h>
void exit(int status);
- 功能:令进程终止
- 参数:
status:进程的退出码,相当于main函数的返回值- 虽然
exit函数的参数和main函数的返回值都是int类型,但只有其中最低数位的字节可被父进程回收,高三字节会被忽略,因此退出码最好不要超过1字节的值域范围
- 虽然
- 通过
return语句终止进程只能在main函数中实现,但是调用exit函数终止进程可以在包含main函数在内的任何函数中使用
exit函数在终止调用进程之前还会做几件收尾工作- 调用实现通过
atexit或on_exit函数注册的退出处理函数 - 冲刷并关闭所有仍处于打开状态的标准I/O流
- 删除所有通过
tmpfile函数创建的临时文件 _exit(status);
- 调用实现通过
- 习惯上,还经常使用
EXIT_SUCCESS和EXIT_FAILUR两个宏作为调用exit函数的参数,分别表示成功和失败。它们的值在多数系统中被定义为0和1,但一般建议使用宏,这样做兼容性更好
atexit / on_exit函数
按照ISO C的规定,一个进程可以登记多至32个函数,这些函数将由exit自动调用。我们称这些函数为终止处理程序(exit handler),并调用 atexit 函数来登记这些函数。
#include<stdlib.h>
int atexit(void(*function)(void));
- 参数:
function:函数指针,指向退出处理函数
- 返回值:函数成功注册返回0,否则返回非0 值
- 注意
atexit函数本身并不调用退出处理函数,而只是将function参数所表示的退出处理函数地址,保存(注册)在系统内核的某个地方(进程表项),待到exit函数被调用或在main函数里执行return语句时,再由系统内核根据这些退出处理函数的地址来调用它们。此过程亦称回调
程序实例
#include <stdio.h>
#include <stdlib.h>
// 终止处理程序
static void f1() {
puts("f1() is working!");
}
// 终止处理程序
static void f2() {
puts("f2() is working!");
}
// 终止处理程序
static void f3() {
puts("f3() is working!");
}
int main() {
puts("Begin");
// 先注册的后被调用
// 钩子函数的书写顺序并不是实际执行顺序,atexit会在程序终止时被调用
// atexit参数用指针来接收,因此需要传入地址,而函数名就是函数的地址
atexit(f1);
atexit(f2);
atexit(f3);
puts("End");
exit(0);
}
执行结果:
PLAINTEXT
Begin
End
f3() is working!
f2() is working!
f1() is working!
on_exit是 atexit 库函数的原型。这个函数的作用是在程序正常终止时调用一个函数。
#include<stdlib.h>
int on_exit(void(*function)(int,void*),void* arg);
- 参数:
function:函数指针,指向退出处理函数。其中第一个参数来自传递给exit函数的status参数或在main函数里执行return语句的返回值,而第二个参数则来自传递给on_exit函数的arg参数arg:泛型指针,作为第二个参数传递给function所指向的退出处理函数
- 返回值:成功返回0,失败返回-1
#include <stdio.h>
#include <stdlib.h>
#include <signal.h>
#include<unistd.h>
void clearup(int status,void* ext_arg){
printf("cleaning up...%d\n",*(int*)ext_arg);
}
int main(){
static int ext = 10; //只有静态或全局变量才能在main函数返回之后不被释放
on_exit(clearup,&ext);
printf("MainFunction\n");
return 0;
}
_exit / _Exit函数
exit是库函数,而_exit是系统调用,前者使用了后者。
除此之外,_exit()执行后会立即返回给内核,而exit()要先执行一些清除和终止操作,然后将控制权交给内核。
#include<unistd.h>
void _exit(int status);
#include<stdlib.h>
void _Exit(int status);
/*两个函数都无返回*/
-
参数:
status:进程退出码,相当于main函数的返回值
-
_eixt在终止调用进程之前也会做几件收尾工作,但与exit函数所做的不同。事实上,exit函数在做完它那三件收尾工作之后紧接着就会调用__exit函数- 关闭所有仍处于打开状态的文件描述符
- 将调用进程的所有子进程托付给
init进程收养 - 向调用进程的父进程发送
SIGCHLD(17)信号 - 令调用进程终止运行,将
status的低八位作为退出码保存在终止状态中
-
exit函数在终止调用进程之前做的收尾工作- 调用实现通过
atexit或on_exit函数注册的退出处理函数 - 冲刷并关闭所有仍处于打开状态的标准I/O流
- 删除所有通过
tmpfile函数创建的临时文件 _exit(status);
如果函数退出时直接调用的
_exit就不会执行前三步 - 调用实现通过
#include <stdio.h>
#include <stdlib.h>
#include <signal.h>
#include<unistd.h>
void clearup(int status,void* ext_arg){
printf("cleaning up...%d\n",*(int*)ext_arg);
}
int main(){
static int ext = 10; //只有静态或全局变量才能在main函数返回之后不被释放
on_exit(clearup,&ext);
printf("MainFunction\n");
printf("the Buferr flushed")
//stdout的缓冲区如果没有遇到换行符(\n)或者没有调用 fflush(stdout);,输出的内容可能不会立即显示
_exit(0);
}
输出结果
cwork$ ./exit
MainFunction
异常终止
当进程执行了某些在系统看来具有危险性的操作,或系统本身发生了某种故障或意外,内核会向相关进程发送特定的信号。如果进程无意针对收到的信号采取补救措施,那么内核将按照默认方式将进程杀死,并视情形生成核心转出文件(core)以备事后分析,俗称吐核
SIGILL(4):进程试图执行非法指令
SIGBUS(7):硬件或对齐错误
SIGFPE(8):浮点异常
SIGEGV(11):无效内存访问
SIGPWR(30):系统供电不足
人为触发信号
SIGINT(2):ctrl + C
SIGQUIT(3):ctrl + \
SIGKILL(9):不能被捕获或忽略的进程终止信号
SIGTERM(15):可以被捕获或忽略的进程终止信号
程序异常
程序运行遇到异常,自行调用abort函数发送信号终止自己
#include<stdlib.h>
void abort(void);
/*
功能:向调用进程发送SIGABRT(6)信号,该信号默认情况下可使进程结束
无参数,无返回
*/
wait/waitpid
wait系统调用:- 获取子进程的终止状态:了解子进程是如何终止的,比如是否正常结束,或者因错误而终止。
- 释放资源:回收子进程的进程控制块(PCB),释放系统资源。
- 清理进程表:移除子进程的条目,避免产生大量僵尸进程。
进程一旦调用了wait,就立即阻塞自己,由wait自动分析是否有子进程已经退出。如果找到了一个已经变成僵尸的子进程,wait就会收集这个子进程的信息,并把它彻底销毁后返回;如果没有找到这样一个子进程,wait就会一直阻塞在这里,直到有一个出现为止。
为何回收子进程
- 清除僵尸进程,避免消耗系统资源
- 父进程需要等待子进程的终止,以继续后续工作
- 父进程需要知道子进程终止的原因
- 如果正常终止,那么退出码是多少
- 如果异常终止,那么进程是被什么信号所终止
wait函数原型如下:
#include <sys/types.h>
#include <sys/wait.h>
pid_t wait(int *status);
-
status用来保存子进程退出时的一些状态。- 如果不在意子进程的退出状态,可以设定
status为NULL。 - 如果参数
status的值不是NULL,wait就会把子进程退出时的状态取出,并存入其中。 - 可以使用下列的宏函数来处理
status:WIFEXITED(status):用来指出子进程是否为正常退出,如果是,则会返回一个非零值。WEXITSTATUS(status):当WIFEXITED返回非零值时,可以用这个宏来提取子进程的返回值。
- 如果不在意子进程的退出状态,可以设定
-
如果执行成功,
wait会返回子进程的PID;如果没有子进程,则wait返回-1。
代码示例1
#include <sys/types.h>
#include <sys/wait.h>
#include <unistd.h>
#include <stdlib.h>
#include <stdio.h>
int main (void) {
pid_t pc, pr;
pc = fork();
if(pc < 0) {
printf ("error ocurred!\n");
}else if (pc == 0) { /* 如果是子进程 */
printf("This is child process with pid of %d\n", getpid());
sleep (10); /* 睡眠10秒钟 */
}else { /* 如果是父进程 */
pr = wait(NULL); /* 在这里阻塞,收尸 */
printf ("I catched a child process with pid of %d\n", pr);
}
exit(0);
}
打印结果:
This is child process with pid of 298
等待10秒
I catched a child process with pid of 298
程序实例2
#include <sys/types.h>
#include <sys/wait.h>
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
int main(void) {
int status;
pid_t pc, pr;
pc = fork();
if(pc < 0) {
printf( "error ocurred!\n" );
}
if(pc == 0) { /* 子进程 */
printf("This is child process with pid of %d\n", getpid());
exit(3); /* 子进程返回3 */
if(pc > 0) { /* 父进程 */
pr = wait(&status);
if(WIFEXITED(status)) { /* 如果WIFEXITED返回非零值 */
printf("the child process %d exit normally\n", pr);
printf("the return code is %d\n", WEXITSTATUS(status ));
} else { /* 如果WIFEXITED返回零 */
printf("the child process %d exit abnormally\n", pr);
}
}
exit(0);
}
打印结果:
This is child process with pid of 308
the child process 308 exit normally
the return code is 3
waitpid函数原型如下:
#include <sys/types.h>
#include <sys/wait.h>
pid_t waitpid(pid_t pid, int *status, int options);
// 下面两者等价:
wait(&status);
waitpid(-1, &status, 0);
从本质上讲,waitpid和wait的作用是完全相同的,但waitpid多出了两个可以由用户控制的参数pid和options:
pid:当pid取不同的值时,在这里有不同的意义:
| 取值 | 意义 |
|---|---|
> 0 |
只等待进程ID等于pid的子进程 |
-1 |
等待任何一个子进程退出,此时waitpid和wait的作用一模一样 |
0 |
等待同一个进程组process group id中的任何子进程 |
<-1 |
等待一个指定进程组中的任何子进程,这个进程组的ID等于pid的绝对值 |
-
options:是一个位图,可以通过按位或来设置,如果不设置则置为0即可。最常用的选项是WNOHANG,作用是即使没有子进程退出,它也会立即返回,此时waitpid不同于wait,它变成了非阻塞的函数。-
0阻塞模式,阻塞直到子进程终止 -
WNOHANG非阻塞模式,子进程在运行则返回0
-
-
waitpid的返回值有如下几种情况:- 当正常返回时,
waitpid返回子进程的PID。 - 如果设置了
WNOHANG,而waitpid没有发现已经退出的子进程,则返回0。 - 如果
waitpid出错,则返回-1。例如参数pid指示的子进程不存在,或此进程存在,但不是调用进程的子进程。
- 当正常返回时,
代码示例1
#include <stdio.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <unistd.h>
#define LEFT 30000000
#define RIGHT 30000200
int main(void) {
int i, j, mark;
pid_t pid;
pid_t pid_child;
for(i = LEFT; i <= RIGHT; i++) {
pid = fork();
if(pid < 0) {
perror("fork()");
exit(1);
}
if(pid == 0) {
mark = 1;
for(j = 2; j < i/2; j++) {
if(i % j == 0) {
mark = 0;
break;
}
}
if(mark)
printf("[%d]:%d is a primer.\n", getpid(), i);
exit(0);
}
}
// 循环201次,给201个子进程收尸
for(i = LEFT; i <= RIGHT; i++) {
pid_child = wait(NULL);
printf("Child process with pid: %d.\n", pid_child);
}
exit(0);
}
执行结果:省略了没有打印质数的输出
[32444]:30000023 is a primer.
Child process with pid: 32444.
[32462]:30000041 is a primer.
Child process with pid: 32462.
[32458]:30000037 is a primer.
Child process with pid: 32458.
[32422]:30000001 is a primer.
Child process with pid: 32422.
[32470]:30000049 is a primer.
Child process with pid: 32470.
[32480]:30000059 is a primer.
Child process with pid: 32480.
[32530]:30000109 is a primer.
Child process with pid: 32530.
[32504]:30000083 is a primer.
Child process with pid: 32504.
[32614]:30000193 is a primer.
Child process with pid: 32614.
[32590]:30000169 is a primer.
Child process with pid: 32590.
[32492]:30000071 is a primer.
Child process with pid: 32492.
[32620]:30000199 is a primer.
Child process with pid: 32620.
[32500]:30000079 is a primer.
Child process with pid: 32500.
[32588]:30000167 is a primer.
Child process with pid: 32588.
[32554]:30000133 is a primer.
Child process with pid: 32554.
[32558]:30000137 is a primer.
Child process with pid: 32558.
[32584]:30000163 is a primer.
Child process with pid: 32584.
[32570]:30000149 is a primer.
Child process with pid: 32570.
shell外部命令实现
内部命令和外部命令
- 内部命令指的是集成在Shell里面的命令,属于Shell的一部分。这些命令由shell程序识别并在shell程序内部完成运行,通常在linux系统加载运行时shell就被加载并驻留在系统内存中,比如
cd命令等,这些命令在磁盘上看不见。 - 外部命令是linux系统中的实用程序部分,因为实用程序的功能通常都比较强大,所以其包含的程序量也会很大,在系统加载时并不随系统一起被加载到内存中,而是在需要时才将其调用内存。通常外部命令的实体并不包含在shell中,但是其命令执行过程是由shell程序控制的。shell程序管理外部命令执行的路径查找(PATH环境变量中)、加载存放,并控制命令的执行。这些命令的二进制可执行文件在磁盘上可见。
外部命令执行流程:
- shell建立(
fork)一个新的子进程,此进程即为Shell的一个副本 - 在子进程里,在PATH变量内所列出的目录中,寻找特定的命令。
/bin:/usr/bin:/usr/X11R6/bin:/usr/local/bin为PATH变量典型的默认值。 当命令名称包含有斜杠(/)符号时,将略过路径查找步骤。
- 在子进程里,以所找到的新程序取代(
exec)子程序并执行。 - 父进程shell等待(
wait)程序完成后(子进程exit),父进程Shell会接着从终端读取下一条命令或执行脚本里的下一条命令
相关命令:
type # 判断是外部命令还是内部命令
which # 查看命令所在的文件路径
示例:
[root@HongyiZeng ~]# type cd
cd is a shell builtin
[root@HongyiZeng ~]# type mkdir
mkdir is /usr/bin/mkdir
[root@HongyiZeng ~]# which ls
alias ls='ls --color=auto'
/usr/bin/ls
之前在终端上执行primer1.c时,出现下列情况:
[root@HongyiZeng proc]# ./primer1
[root@HongyiZeng proc]# 30000037 is a primer.
30000001 is a primer.
30000041 is a primer.
30000023 is a primer.
30000079 is a primer.
30000133 is a primer.
30000137 is a primer.
30000049 is a primer.
30000109 is a primer.
30000083 is a primer.
30000071 is a primer.
30000059 is a primer.
30000193 is a primer.
30000169 is a primer.
30000167 is a primer.
30000199 is a primer.
30000163 is a primer.
30000149 is a primer.
发现终端先于子程序打印。
原因:在终端上执行primer1时,父进程(终端,即shell)fork了一个子进程,然后exec了primer1程序,并且wait到primer1退出,所以当primer1退出时,就立刻出现了终端,此时primer1 fork的子进程还在运行打印结果,所以出现了终端先于子进程的结果出现。
重要!!!(外部命令执行流程):一般的,当shell执行某个程序时,首先fork一个子进程,然后该子进程exec那个执行程序,shell此时wait该程序退出exit。
shell伪代码示例
int main(void) {
// 死循环,shell不断接收用户命令
while(1) {
// 终端提示符
prompt();
// 获取命令
getline();
// 解析命令
parse();
if(内部命令) {
// ...
} else { // 外部命令
fork();
if(pid < 0) {
// 异常处理...
}
if(pid == 0) { // 子进程
exec(); // 将子进程替换为待执行程序
// 异常处理...
}
if(pid > 0) { // shell父进程
wait(NULL); // 等待子进程结束
}
}
}
exit(0);
}
代码实现
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <glob.h>
// 分隔符:空 制表符 换行符
#define DELIMS " \t\n"
struct cmd_st {
glob_t globres;
};
static void prompt(void) {
printf("mysh-0.1$ ");
}
static void parse(char *line, struct cmd_st *res) {
char *tok;
int i = 0;
while(1) {
tok = strsep(&line, DELIMS);
// strsep实现字符串的分割
if(tok == NULL)
break;
if(tok[0] == '\0')
continue;
// 选项解释
// NOCHECK:不对pattern进行解析,直接返回pattern(这里是tok),相当于存储了命令行参数tok在glob_t中
// APPEND:以追加形式将tok存放在glob_t中,第一次时不追加,因为globres尚未初始化,需要系统来自己分配内存,因此乘上i(乘法优先于按位或)
glob(tok, GLOB_NOCHECK|GLOB_APPEND*i, NULL, &res->globres);
// 置为1,使得追加永远成立
i = 1;
}
}
int main(void) {
// getline的参数要初始化
char *linebuf = NULL;
size_t linebuf_size = 0;
struct cmd_st cmd;
pid_t pid;
while(1) {
prompt();
// getline函数参见2.10节
if(getline(&linebuf, &linebuf_size, stdin) < 0) {
break;
}
// 解析命令
parse(linebuf, &cmd);
if(0) { // 内部命令,暂不做实现
} else { // 外部命令
pid = fork();
if(pid < 0) {
perror("fork()");
exit(1);
}
if(pid == 0) {
execvp(cmd.globres.gl_pathv[0], cmd.globres.gl_pathv);
perror("execvp()");
exit(1);
} else {
wait(NULL);
}
}
}
exit(0);
}
程序分析:
strsep函数原型:
#include <string.h>
char * strsep(char **stringp, const char *delim);
strsep实现字符串的分割,把stringp里面出现的delim替换成'\0',后将 stringp 更新指向到'\0'符号的下一个字符地址,函数的返回值指向原来的 stringp 位置。直到分割完毕返回NULL。
代码执行流程分析:
例如:
[root@HongyiZeng proc]# ./mysh
mysh-0.1$ ls -l
total 144
-rwxr-xr-x 1 root root 8600 Dec 13 11:46 ex
-rw-r--r-- 1 root root 213 Dec 13 11:46 ex.c
-rwxr-xr-x 1 root root 8552 Dec 13 12:52 exv
-rw-r--r-- 1 root root 232 Dec 13 12:52 exv.c
-rwxr-xr-x 1 root root 8752 Dec 13 11:58 few
-rw-r--r-- 1 root root 361 Dec 13 11:58 few.c
-rwxr-xr-x 1 root root 8656 Dec 12 10:19 fork1
-rw-r--r-- 1 root root 402 Dec 12 10:19 fork1.c
-rwxr-xr-x 1 root root 8912 Dec 14 12:06 mysh
-rw-r--r-- 1 root root 953 Dec 14 12:06 mysh.c
-rwxr-xr-x 1 root root 8448 Dec 12 10:28 primer0
-rw-r--r-- 1 root root 313 Dec 12 10:28 primer0.c
-rwxr-xr-x 1 root root 8552 Dec 14 11:05 primer1
-rw-r--r-- 1 root root 437 Dec 14 11:04 primer1.c
-rwxr-xr-x 1 root root 8656 Dec 13 10:02 primer2
-rw-r--r-- 1 root root 652 Dec 13 10:02 primer2.c
-rwxr-xr-x 1 root root 8672 Dec 12 11:56 vfork
-rw-r--r-- 1 root root 372 Dec 12 11:56 vfork.c
-
getline得到字符串ls -l -
parse解析该字符串,将分割结果存在globres中,其中:globres.gl_pathv[0] = "ls"; globres.gl_pathv[1] = "-l"; globres.gl_pathv[2] = NULL; -
子进程
execvp(cmd.globres.gl_pathv[0], cmd.globres.gl_pathv);- 第一个参数为要执行的可执行程序的名字,为
ls,从环境变量PATH中找到/usr/bin/路径下的ls程序 - 第二个参数为指针数组,为
ls和-l,第一个为程序名,任意,第二个和后面的为命令的参数,重要,这里的参数为-l
- 第一个参数为要执行的可执行程序的名字,为
特殊权限
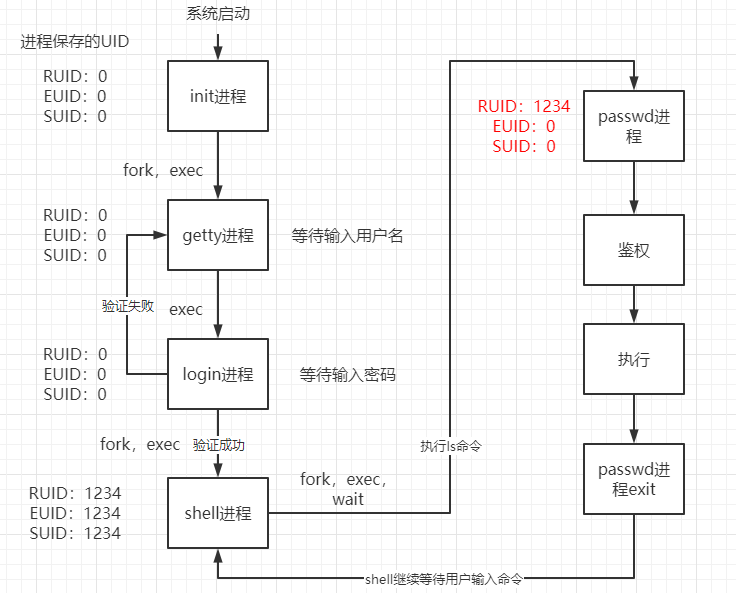
文件和目录权限除了普通权限rwx外,还有三个特殊权限:
SUID:在属主的x位以s标识,全称SetUIDSGID:在属组的x位以s标识,全称SetGIDSTIKCY:粘滞位
[root@HongyiZeng proc]# ll /usr/bin/passwd
-rwsr-xr-x 1 root root 27856 Apr 1 2020 /usr/bin/passwd
上面第4位的s就是特殊权限SUID,属主为root,其uid为0。当普通用户执行该命令时,会以root的身份去执行该命令。
下面将由五个问题来说明什么是SUID:
# 1.普通用户可不可以修改密码?
可以,修改自己的密码
# 2./etc/shadow文件的作用?
存储用户密码的文件
# 3./etc/shadow文件的权限?
[root@localhost ~]# ll /etc/shadow
----------1 root root 16404 Apr 8 11:41 /etc/shadow
# 4.普通用户,是否可以修改/etc/shadow文件?
不可以,/etc/shadow文件,对于普通用户没有任何权限,所以不能读取,也不能写入内容。
普通用户的信息保存在 /etc/passwd文件中,与用户的密码在 /etc/shadow 文件中,也就是说,普通用户在更改自己密码时,修改了 /etc/shadow 文件中的加密密码,但是文件权限显示,普通用户对这两个文件都没有写权限。
# 5.那么普通用户,为什么可以修改密码?
1)因为使用了passwd这个命令
2)passwd命令在属主权限位上,原本是x权限,变成了s权限
3)s权限在属主权限位,又叫做SetUID权限,SUID
4)作用:普通用户在使用有SUID权限的文件或命令时,会以该文件的属主身份去执行该命令,换句话说,普通用户在执行passwd命令时,切换成了passwd属主即root的身份去执行passwd命令。
从进程控制的角度来说,当非root用户执行passwd这个可执行文件的时候,产生的进程的EUID,就是root用户的UID。换言之,这种情况下,产生的进程,实际以root用户的ID来运行二进制文件。
相关命令
chmod u+s 文件名/目录名 # 对文件给予用户s权限,则此用户暂时获得这个文件的属主权限
chmod g+s 文件名/目录名 # 对文件给予用户组s权限,则此用户暂时获得这个文件的属组权限
从进程控制的角度看命令的执行
-
UNIX系统产生的第一个进程是
init进程,其三个uid为root的uid,即res为0 0 0,以init(0 0 0)表示; -
init进程fork和exec产生getty(0 0 0)进程,此进程等待用户输入用户名; -
用户回车输入了用户名后,
getty进程存储用户名,exec产生login(0 0 0)进程,等待用户输入密码并验证口令(查找用户名和密码/etc/passwd);- 如果验证成功,
login进程则fork并exec产生shell(r e s)进程,即终端,此时的res就是登录用户的UID,即固定了用户产生的进程的身份; - 如果验证失败,则返回继续验证;
- 如果验证成功,
-
当用户执行某个命令时,
shell进程fork并exec该命令对应的程序,例如ls(r e s),并wait该程序,ls进程退出时,又返回到shell(r e s)终端(因为shell是一个死循环,参见6.5节); -
可以看出,整个UNIX的世界就是由fork,exec,wait和exit的进程控制原语搭建起来的
整个过程的图示如下:
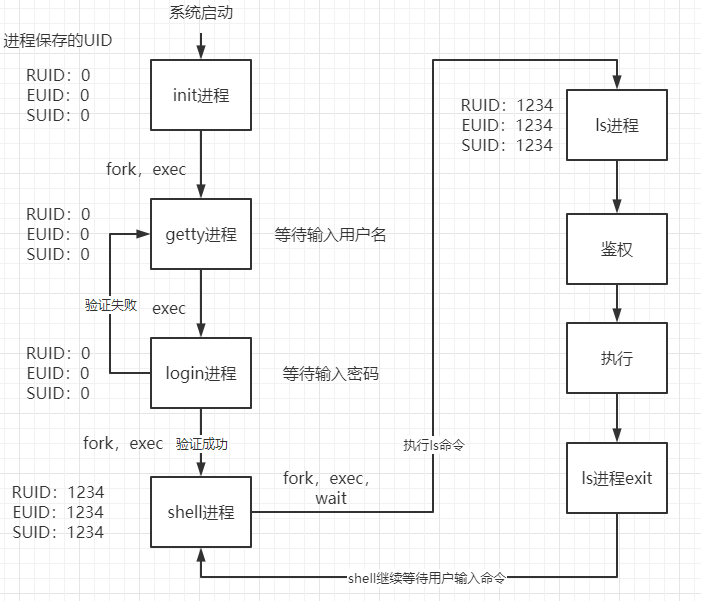
又如执行passwd命令时图如下,变化的只有EUID和SUID:
相关系统调用
下面的系统调用是特殊权限实现所需的函数。
- 获取:
#include <unistd.h>
#include <sys/types.h>
// 返回当前进程的ruid
uid_t getuid(void);
// 返回当前进程的euid
uid_t geteuid(void);
gid_t getgid(void);
gid_t getegid(void);
- 设置:
#include <sys/types.h>
#include <unistd.h>
// 设置当前进程的euid
int setuid(uid_t uid);
// 设置当前进程的egid
int setgid(gid_t gid);
- 交换:
#include <sys/types.h>
#include <unistd.h>
// 交换当前进程的ruid和euid
int setreuid(uid_t ruid, uid_t euid);
int setregid(gid_t rgid, gid_t egid);
代码示例
实现任意用户用0号用户(即root)的身份查看/etc/shadow文件的功能:
./mysu 0 cat /etc/shadow
exec参数:
cat -> main的argv[2]:所需要执行的程序;
cat /etc/shadow -> main的argv[2]之后:程序名cat 命令行参数/etc/shadow
代码实现:(以普通用户lighthouse编译链接)
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main(int argc, char **argv) {
pid_t pid;
if(argc < 3) {
fprintf(stderr, "Usage...\n");
exit(1);
}
pid = fork();
if(pid < 0) {
perror("fork()");
exit(1);
}
if(pid == 0) {
setuid(atoi(argv[1])); // 将字符串转成int
execvp(argv[2], argv + 2);
perror("execvp()");
exit(1);
}
wait(NULL);
exit(0);
}
查看该文件的属性:
[lighthouse@HongyiZeng proc]$ ll mysu
-rwxr-xr-x 1 lighthouse lighthouse 8800 Dec 16 12:32 mysu
直接运行,权限不够:
[lighthouse@HongyiZeng proc]$ ./mysu 0 cat /etc/shadow
cat: /etc/shadow: Permission denied
切换到root用户,将mysu属主更改为root,并给予该文件s权限:
[root@HongyiZeng proc]# chown root mysu
[root@HongyiZeng proc]# chmod u+s mysu
[root@HongyiZeng proc]# ll mysu
-rwsr-xr-x 1 root lighthouse 8800 Dec 16 12:32 mysu
然后切换到lighthouse,再执行即可:
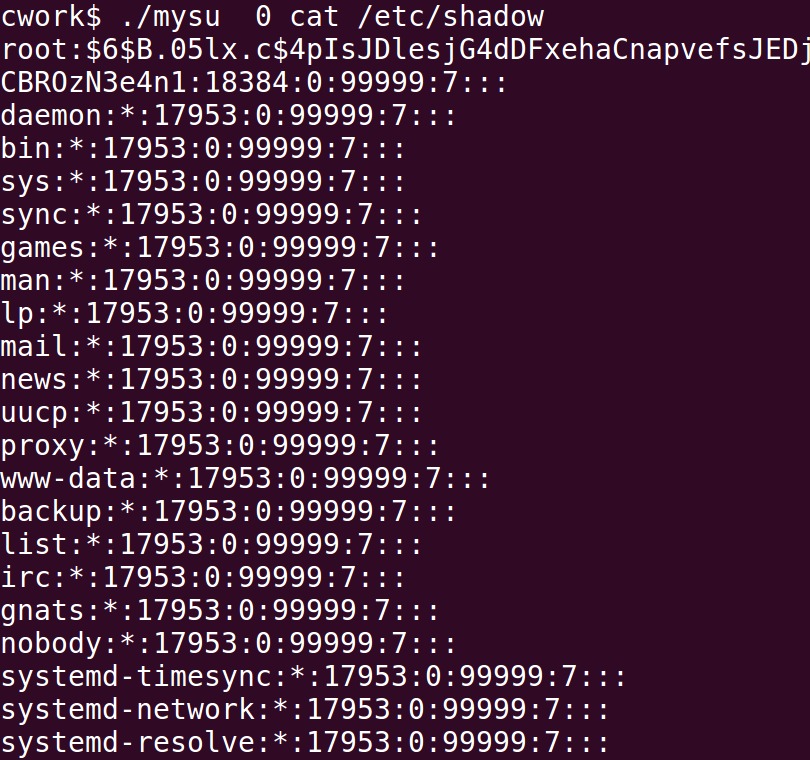
解释器文件
解释器文件也叫脚本文件。脚本文件包括:shell脚本,python脚本等;
脚本文件的后缀可自定义,一般来说shell脚本的后缀名为.sh,python脚本的后缀名为.py。
解释器文件的执行过程:当在linux系统的shell命令行上执行一个可执行文件时,系统会fork一个子进程,在子进程中内核会首先将该文件当做是二进制机器文件来执行,但是内核发现该文件不是机器文件(看到第一行为#!)后就会返回一个错误信息,收到错误信息后进程会将该文件看做是一个解释器文件,然后扫描该文件的第一行,获取解释器程序(本质上就是可执行文件)的名字,然后执行exec该解释器,并将该解释器文件当做解释器的一个参数,然后开始由解释器程序从头扫描整个解释器文件,执行每条语句(如果指定解释器为shell,会跳过第一条语句,因为#是注释)。如果其中某条命令执行失败了也不会影响后续命令的执行。
解释器文件的格式:
#!pathname [optional-argument]
内容...
pathname:一般是绝对路径(它不会使用$PATH做路径搜索),对这个文件识别是由内核做为exec系统调用处理的。optional-argument:相当于提供给exec的参数
内核exec执行的并不是解释器文件,而是第一行pathname指定的文件。一定要将解释器文件(本质是一个文本文件,以 #!开头)和解释器(由pathname指定)区分开。
代码示例1
以普通用户创建脚本test.sh:
#!/bin/bash
ls
whoami
cat /etc/shadow
ps
这个文件没有执行权限,需要添加:
[lighthouse@HongyiZeng proc]$ ll test.sh
-rw-r--r-- 1 lighthouse lighthouse 46 Dec 16 15:09 test.sh
[lighthouse@HongyiZeng proc]$ chmod u+x test.sh
[lighthouse@HongyiZeng proc]$ ./test.sh
ex exv.c fork1 hello.c mysh mysu.c primer1 primer2.c test.sh
ex.c few fork1.c myexec mysh.c primer0 primer1.c sleep vfork
exv few.c hello myexec.c mysu primer0.c primer2 sleep.c vfork.c
lighthouse
cat: /etc/shadow: Permission denied
PID TTY TIME CMD
14857 pts/3 00:00:00 bash
19087 pts/3 00:00:00 test.sh
19091 pts/3 00:00:00 ps
shell执行./test.sh时,fork了一个子进程,该进程看到该文件为解释器文件,于是读取第一行,得到解释器程序的PATH,并exec该解释器程序(/bin/bash),然后重新执行这个解释器文件。
可以看出bash跳过了第一句,因为#在bash程序中被看成了注释,cat命令没有权限,但后面的ps命令仍然继续执行。
代码示例2
#!/bin/cat
ls
whoami
cat /etc/shadow
ps
执行该脚本:
[root@HongyiZeng proc]# ./test.sh
#!/bin/cat
ls
whoami
cat /etc/shadow
ps
发现这次是打印了该脚本文件的所有内容。过程同上,只是这次子进程exec的程序为/bin/cat程序。
代码示例3——自定义解释器程序
解释器程序(或解释器)本质上就是一个可执行文件。解释器文件是一个文本文件。
echoarg.c
#include <stdio.h>
#include <stdlib.h>
int main(int argc, char* argv[]) {
int i;
for(i = 0; i < argc; i++) {
printf("argv[%d]: %s \n", i, argv[i]);
}
exit(0);
}
编译为echoarg,并存放在/usr/local/linux_c/proc/下。
echoarg.sh
#!/usr/local/linux_c/proc/echoarg foo1 foo2 foo3
执行结果:
[root@HongyiZeng proc]# ./echoarg.sh
argv[0]: /usr/local/linux_c/proc/echoarg
argv[1]: foo1 foo2 foo3
argv[2]: ./echoarg.sh
system
函数原型:
#include<stdlib.h>
int system(const char* command);
-
功能:该函数实际上调用的是
/bin/sh -c command,实质上是对fork+exec+wait的封装 -
参数:
command shell命令行字符串 -
返回值:成功返回
command进程的终止状态,失败返回-1 -
system函数执行返回command参数所表示的命令行,并返回命令进程的终止状态 -
若
command参数取NULL,返回非0表示shell可用,返回0表示shell不可用 -
在
system函数里调用了vfork、exec和waitpid等函数- 如果调用
vfork或waitpid函数出错,则返回-1 - 如果调用
exec函数出错,则在子进程中执行exit(127) - 如果都成功,则返回
command进程的终止状态(由waitpid的status参数获得)
- 如果调用
-
使用
system函数而不用vfork+exec的好处是,system函数针对各种错误和信号都做了必要处理,而system是标准库函数,可跨平台使用
程序实例
#include <stdio.h>
#include <stdlib.h>
int main(void) {
system("date +%s > /tmp/out");
exit(0);
}
该程序实质上执行的命令为:
/bin/sh -c date +%s > /tmp/out
在执行该命令的时候,system函数代码类似于:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main(void) {
pid_t pid;
pid = fork();
if(pid < 0) {
perror("fork()");
exit(1);
}
if(pid == 0) {
// 实际上在 exec /bin/sh程序
execl("/bin/sh", "sh", "-c", "date +%s > /tmp/out", NULL);
perror("execl()");
exit(1);
}
wait(NULL);
exit(0);
}
system函数演示
//system函数演示
#include<stdio.h>
#include<stdlib.h>// system
#include<sys/wait.h>
int main(void){
int s = system("./new hello 123");
if(s == -1){
perror("system");
return -1;
}
if(WIFEXITED(s)){
printf("正常终止:%d\n",WEXITSTATUS(s));
}else{
printf("异常终止:%d\n",WTERMSIG(s));
}
s = system("ls -l -i --color=auto");
if(s == -1){
perror("system");
return -1;
}
if(WIFEXITED(s)){
printf("正常终止:%d\n",WEXITSTATUS(s));
}else{
printf("异常终止:%d\n",WTERMSIG(s));
}
return 0;
}
//new.c
#include<stdio.h>
#include<unistd.h>
int main(int argc,char* argv[],char* envp[]){
printf("PID : %d\n",getpid());
printf("命令行参数:\n");
for(char** pp = argv;*pp;pp++){
printf("%s\n",*pp);
}
printf("环境变量:\n");
for(char** pp = envp;*pp;pp++){
printf("%s\n",*pp);
}
printf("------------------------\n");
return 0;
}
守护进程
守护进程也叫做精灵进程(Daemon),是运行在后台的一种特殊进程,它独立于控制终端并且可以周期性的执行某种任务或者等待处理某些发生的事件。
守护进程常常在系统引导装入时启动,在系统关闭时终止。
守护进程是非常有用的进程,在Linux当中大多数服务器用的就是守护进程。比如Web服务器httpd等,同时守护进程完成很多系统的任务。当Linux系统启动的时候,会启动很多系统服务,这些进程服务是没有终端的,也就是说把终端关闭了,这些系统服务是不会停止的。
特点
- 生存周期长[不是必须]:一般是操作系统启动的时候他启动,操作系统关闭的时候他才关闭
- 守护进程和终端没有关联,也就是说他们没有控制终端,所以控制终端退出也不会导致守护进程退出
- 守护进程是在后台运行不会占着终端,终端可以执行其它命令
进程组与会话
- 进程组:进程除了
PID之外还有一个进程组id,进程组是由一个进程或者多个进程组成。- 通常进程组与同一作业相关联,可以收到同一终端的信号:这个信号可以使同一个进程组中的所有进程终止,停止或者继续运行
- 进程
组id就是组长进程的pid,只要在某个进程组中还有一个进程存在,则该进程组就存在
- 会话:会话是有一个或者多个进程组组成的集合
- 每打开一个控制中断,或者在用户登录时,系统就会创建新会话
- 在该会话中允许的第一个进程称作会话首进程,通常这个首进程就是shell
- 通常,一个会话开始于用户登录,终止于用户退出,在此期间该用户运行的所有进程都属于这个会话
字段含义
PPID:父进程pidPID:当前进程pidPGID:进程组idSID TTY:当前进程的会话idTPGID:进程组和终端的关系,-1表示没有关系STAT:进程状态UID:启动(exec)该进程的用户的idTIME:进程执行到目前为止经历的时间COMMAND:启动该进程时的命令
创建守护进程
相关系统调用:
#include <unistd.h>
// creates a session and sets the process group ID 错误返回-1
pid_t setsid(void);
作用:创建一个新的会话,并让执行的进程称为该会话组的组长
创建流程:
- 创建自己并被
init进程接管:在父进程中执行fork并exit退出,让子进程被init进程接管,从而脱离终端进程shell的控制; - 创建新进程组和新会话:在子进程中调用
setsid函数创建新的会话和进程组; - 修改子进程的工作目录:在子进程中调用
chdir函数,让根目录/成为子进程的工作目录; - 修改子进程
umask:在子进程中调用umask函数,设置进程的umask为0; - 在子进程中关闭任何不需要的文件描述符
- 由于守护进程和终端没有关系,所以需要将子进程的标准输入和标准输出重定向到
dev/null(空设备当中去)
代码示例
#include <iostream>
#include <unistd.h>
#include <signal.h>
#include <sys/stat.h>
#include <cstdlib>
#include <fcntl.h>
void main(void) {
int fd;
pid_t pid;
pid = fork();
if(pid < 0) { // 出错
perror("fork()");
exit(1);
} else if(pid == 0) { // 子进程
//只有子进程才会走到这里
if(setsid() == -1) {
perror("setsid()");
exit(1);
}
umask(0); //设置权限掩码
fd = open("/dev/null",O_RDWR); //打开黑洞设备以读写方式打开
if(fd == -1) {
perror("open");
exit(1);
}
if(fd > 3) { // 关闭继承的文件描述符
if(close(fd) == -1) {
perror("close()");
exit(1);
}
}
// 重定向...
for(;;) {
// 守护进程要完成的任务...
}
} else if(pid > 0) {
exit(0); // 父进程退出
}
// nerver reach...
exit(0);
}
执行结果:

注意:进程守护化以后,只能使用kill命令杀掉该进程
后台进程和守护化
使用& ,可以将程序执行在后台:
./test >> out.txt 2>&1 &
在命令的末尾加个&符号后,程序可以在后台运行,但是一旦当前终端关闭,该程序就会停止运行,这就是后台进程。
后台进程和守护进程的区别
- 守护进程与终端无关,是被init进程收养的孤儿进程;而后台进程的父进程是终端,仍然可以在终端打印
- 守护进程在关闭终端时依然存在;而后台进程会随用户退出而停止
- 守护进程改变了会话、进程组、工作目录和文件描述符,后台进程直接继承父进程(shell)的
将进程守护化
可以使用nohup(no hang up)命令结合&将进程守护化:
nohup [进程名] [参数] 可执行文件 [重定向] &
例如:
# 将./test守护化,并将缓冲区的内容重定向至`out.txt`
nohup ./test >> out.txt &
# 执行python程序,`-u`为python的参数,意为不启用缓冲,将内存中的内容直接写入到磁盘文件中。
nohup python -u test.py > nohup.out 2>&1 &
# 执行java程序。
nohup java -jar demo.jar

 浙公网安备 33010602011771号
浙公网安备 33010602011771号