

C:数据类型、控制结构
基本语法
概述
- C语言程序里大括号可以用来代表函数(函数可以看作一组语句)
- C语言里每个函数都必须有名字,不同函数的名字不能相同
- C语言程序必须包含一个叫做main的函数,这个函数叫做主函数(入口函数)
- 程序从主函数的第一条语句开始执行,当主函数里最后一条语句结束后整个程序结束
- 函数结束的适合可以用一个数字来表示他的执行结果,这个数字叫做函数的返回值
- 主函数应该有一个函数值,如果返回值是0表示程序希望计算机认为它正常结束了,否则表示程序希望计算机认为它执行出问题了
关键字
- C语言里预先保留了几十个英文单词,他们属于关键字。每个关键字都有特定用途,不能随便使用。
return就是一个关键字,用途:- 主要用途为结束函数的执行,函数中遇到
return后就会执行结束 - 辅助用途用来执行返回的数值,如
return 0;当前函数返回值为0
![关键字]()
- 主要用途为结束函数的执行,函数中遇到

变量与常亮
- 能读能写的内存对象,称为变量;若初始化后不能修改的则称为常量
- 存储区有对应的地址,第一个字节的地址称为存储区首地址、存储区基地址
- C语言程序中使用变量来表示存储区
- 需要先定义变量才可以使用变量来表示存储区
- 格式:
数据类型 变量名 = 初始数据; - 例如:
int a = 100;
- 变量名称:连续内存空间的别名
printf("%d\n",&变量名);int a = 10; printf("%d\n",a);//使用变量名访问内存空间,读取存储的数字 printf("%d\n",&a);//使用&可以获取该内存空间首地址:
左值和右值
- 左值(lvalue):指向内存位置的表达式被称为左值(lvalue)表达式。左值可以出现在赋值号的左边或右边。
- 右值(rvalue):指的是存储在内存中某些地址的数值。右值是不能对其进行赋值的表达式,也就是说,右值可以出现在赋值号的右边,但不能出现在赋值号的左边。
变量是左值,因此可以出现在赋值号的左边。数值型的字面值是右值,因此不能被赋值,不能出现在赋值号的左边。下面是一个有效的语句:
int g = 20;
但是下面这个就不是一个有效的语句,会生成编译时错误:
10 = 20;
变量命名规则
- 不能以数字开头,只能是字母或者下划线
int 2var; //错误
int _2var; //正确
int var2; //正确
- 关键字不可以作为变量名称
int return = 1; //return是关键字,所以编译器会报错
- 大小写敏感
int a;
int A;
/*a和A是两个不同变量*/
- 命名规范
/*驼峰命名(Windows)*/
int studentAge = 10;
/*下划线命名(Linux)*/
int student_age = 10;
常量
- 常量是固定值,在程序执行期间不会改变。这些固定的值,又叫做字面量。
- 常量可以是任何的基本数据类型,比如整数常量、浮点常量、字符常量,或字符串字面值,也有枚举常量。
- 常量就像是常规的变量,只不过常量的值在定义后不能进行修改。
常量实例:
/*整形常量实例*/
85 /* 十进制 */
0213 /* 八进制 078非法:8 不是八进制的数字 */
0x4b /* 十六进制 */
30 /* 整数 */
30u /* 无符号整数 032UU非法:不能重复后缀u */
30l /* 长整数 */
30ul /* 无符号长整数 */
/*浮点数常量实例*/
3.14159 /* 合法的 */
314159E-5L /* 合法的 510E非法:E后面没有指数 */
210f /* 非法的:没有小数或指数 */
.e55 /* 非法的:缺少整数或分数 */
定义常量
在C中,有两种简单方式定义常量
-
使用
#define预处理#define MAX 100; #define FILENAME "cPlus.txt" -
使用
const关键字const int MAX = 100; const char FILENAME[] = "myBook.pdf"
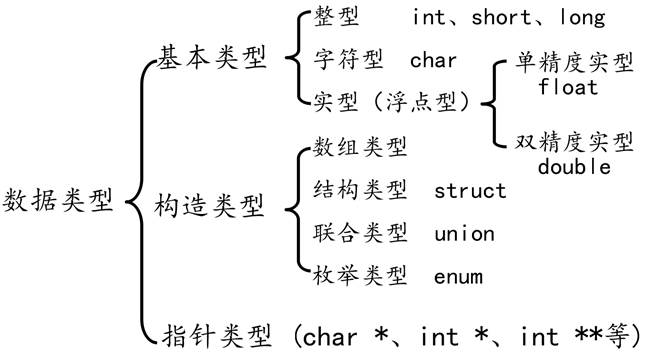
基本数据类型
- 类型是对数据的抽象
- 类型相同的数据具有相同的表示形式、存储格式以及相关操作
- 程序中所有数据都必定属于某种数据类型
- 数据类型可以理解为创建变量的模具:固定大小内存的别名
| 数据类型 | 含义 | 内存占用 | 数据范围 |
|---|---|---|---|
| char | 字符型 | 1字节 | -128~127 |
| short | 短整型 | 2字节 | -32768~32767 |
| int | 整型 | 4字节 | -2³¹~2³¹-1 |
| long | 长整形 | 4字节 | -2³¹~2³¹-1 |
| long long | 长长整形 | 8字节 | -2⁶³~2⁶³-1 |
| float | 浮点型(单精度) | 4字节 | -2¹²⁸~2¹²⁸ |
| double | 浮点型(双精度) | 8字节 | -2¹⁰²⁴~2¹⁰²⁴ |
| bool | 布尔型 | 1字节 | 0和非0 |
| unsigned char | 无符号字符型 | 1字节 | 0~255 |
| unsigned short | 无符号短整型 | 2字节 | 0~65535 |
| unsigned int | 无符号整型 | 4字节 | 0~2³²-1 |
| unsigned long | 无符号长短整型 | 4字节 | 0~2³²-1 |
| 32位系统 | 64位系统 | |
|---|---|---|
| long | 4字节 | 8字节 |
| unsigned long | 4字节 | 8字节 |
字符类型(char)
字符:单引号引起来的字母、数字、标点符号
'a','b','c'
'1','2','3'
'A','B','C'
'!','?','\'
- 字符类型包含256个不同的整数,每个整数对应一个字符,字符和整数之间时可以互相转换的
- 终端输入man ascii可以看到ASCII码表,ASCII码表记录字符和整数之间的对应关系
- 存储一个字符的本质是将字符对应的数字存储到内存中,例如字符'a'是存储的97
- 输入输出占位符:
- %c:将内存中数字以字符方式输出
- %hhd:将内存中数字以数字方式输出
- 例如字符'0'以%c输出显示0,以%hhd输出显示48
ACSII码表
| ASCII码 | 字符 |
|---|---|
| 32 | 空格 |
| 33~47 | !"#$%&'()*+,-. |
| 48~57 | 0123456789 |
| 58~64 | :;<=>?@ |
| 65~90 | ABCDEFGHIJKLMNOPQRSTUVWXYZ |
| 91~96 | [\]^_` |
| 97~122 | abcdefghijklmnopqrstuvwxyz |
| 123~126 | {|}~ |
转义字符
| 字符 | 含义 | 字符 | 含义 |
|---|---|---|---|
| \b | 退格 | \' | ` |
| \r | 到当前行首 | \" | " |
| \n | 换行符 | \\ | \ |
| \t | 制表符 | %% | % |
整数类型
short、int、long等类型都叫做有符号整数型
unsigned修饰的无符号整数型,只能存储非负数
浮点型(float、double)
| 符号位 | 指数位 | 数字范围 | 科学计数法表示范围 | |
|---|---|---|---|---|
| float | 1 bit | (7+1) bit | -2^128 ~ +2^128 | -3.40E+38 ~ +3.40E+38 |
| double | 1 bit | (10+1) bit | -2^1024 ~ +2^1024 | -1.79E+308 ~ +1.79E+308 |
浮点数也叫小数或实数
float是32位浮点数,内存中占4个字节,按科学计数法来存储,精度约为7位小数
double是64位浮点数,内存中占8个字节,按科学计数法来存储,精度约为15位小数
浮点型例如:5.6在程序中默认为double类型,5.6f则表示float类型
类型转换
若一个表达式包含多个不同类型数字,计算机会先将他妈转换为同类型然后再计算,转换过程叫隐式类型转换
转换规则:
-
整数转浮点数
-
有符号转无符号
-
字节小的数据类型转字节大的数据类型
-
强制类型转换有可能导致数据内容丢失
-
类型转换不回修改存储区内容
-
常用语指针类型转换
int a = 98;
char ch = (char)a;
print("%c\n",ch);//将a转换为char类型赋值给ch,输出结果为b
占位符
数据类型对应相关占位符:
| 类型 | 占位符 | 类型 | 占位符 |
|---|---|---|---|
| char | %c、%hhd | unsigned char | %c、%hhu |
| short | %hd | unsigned short | %hu |
| int | %d | unsigned int | %u |
| long | %l | unsigned long | %lu |
| float | %f、%g | double | %lf、%lg |
| 字符串string | %s | 指针point | %p |
其他占位符:
%d //以十进制整型格式
%i //以十进制整型格式
%ld //以十进制长整型(long int)格式
%lld //以十进制长长整型(long long int)格式
%u //以无符号十进制整型格式
%c //以字符格式
%f //以float型格式输出
%lf //以double型格式输出
%e //以指数格式
%le //以指数格式
%E //以指数格式
%lE //以指数格式
%g //%e或%f的缩短版
%G //%E的缩短版
%s //以字符串格式
%o //以无符号八进制整型格式
%ho //以八进制短整型格式输出
%p //以地址格式
%x //以无符号十六进制整型格式(小x输出的十六进制为小写的)
%X //以无符号十六进制整型格式(大X输出的十六进制为大写的)
%hd //以短整型格式
%hu //以无符号短整型格式
%lu //以无符号长整型格式
%# //完整呈现所有数值位数,显示八进制时,在数值前会加上数字0 显示十六进制时,会在数值前加上0x
格式输出控制(以下的m和n都是整数)
%+md /*按照指定宽度m输出十进制整型数据,如果数据实际宽度大于m则按照实际输出,小于m
则按照右对齐(+表示右对齐)输出,+通常省略不写*/
%-md /*按照指定宽度m输出十进制整形数据,如果数据实际宽度大于m则按照实际输出,小于m
则按照左对齐(-表示左对齐)输出,-不能省略*/
%+mc //按照指定宽度m输出字符,+通常省略不写,+表示右对齐
%-mc //按照指定宽度m输出字符,不能省略,-表示左对齐
%+mf /*按照包括小数点在内的数据宽度m输出浮点型数据,当m大于实际数据宽度时,右对齐,+通常省略
当m小于实际数据宽度时,将以实际数值输出*/
%-mf /*按照包括小数点在内的数据宽度m输出浮点型数据,当m大于实际数据宽度时,左对齐,-不能省略
当m小于实际数据宽度时,将以实际数值输出*/
%.nf /*按照指定小数点后的输出宽度输出浮点型数据,当n大于实际数据有效位数时,右边补0,当n小于
实际数据有效位数时采用四舍五入处理*/
%+m.nf /*按照指定包括小数点在内的数据输出全部宽度,当m大于输出数据全部数据宽度时,左边补空格,
当m小于输出全部数据宽度时,将按照实际宽度输出,注意:使用这种格式输出时,将优先考虑n的
值,即在满足n的值基础上再判断m对数据输出的影响。当m小于n时,则m对输出数据不起作用*/
%-m.nf /*按照指定包括小数点在内的数据输出全部宽度,当m大于输出数据全部数据宽度时,右边边补空 格,当m小于输出全部数据宽度时,将按照实际宽度输出,注意:使用这种格式输出时,将优先考虑n 的值,即在满足n的值基础上再判断m对数据输出的影响。当m小于n时,则m对输出数据不起作用*/
%+ms /*按照输出宽度为m列的字符串输出字符串,当m小于实际的字符串长度时,将按实际字符串输出
当m大于实际字符串长度时m时,左补空格*/
%-ms /*按照输出宽度为m列的字符串输出字符串,当m小于实际的字符串长度时,将按实际字符串输出
当m大于实际字符串长度时m时,右补空格*/
%+m.ns /*按照指定输出字符串的长度m输出字符串,当m大于实际字符串长度时,输出的字符串左补空格,
当m小于等于实际字符串长度时,将按实际字符串输出。n用于指定输出左边n个字符,当n大于实际
字符串长度时,将按实际字符串输出。当m小于n时,忽略m的作用*/
%-m.ns /*按照指定输出字符串的长度m输出字符串,当m大于实际字符串长度时,输出的字符串右补空格,
当m小于等于实际字符串长度时,将按实际字符串输出。n用于指定输出左边n个字符,当n大于实际
字符串长度时,将按实际字符串输出。当m小于n时,忽略m的作用*/
%.ns /*用于输出字符串左边n个字符,当n大于实际字符串长度时,按实际字符串输出*/
%*s //scanf中忽略指定类型的输入的值,使其不会被参数所获取
运算符
运算符是diabetes数字处理规则的符号
根据运算需要配合的数字个数分为单目运算符、双目运算符和三目运算符
算术运算符 + - * /表示加减乘除,都是双目运算符
| 运算符 | 作用 | 示例 |
|---|---|---|
| / | 除号,结果只保留整数部分 | 5 / 2 = 2 |
| % | 取余,结果值保留相除后的余数,禁止对小数取余 | 5 % 2 = 1 |
| = | 赋值,将等号右边的数据放到左边表示的内存中 | a = b = 1 |
复合运算符:+=、-=、/=、*=、%=
- a += 10相当于a = a + 10;a /= 10相当于a = a / 10
自增运算符(++)和自减运算符(--)都是单目运算符
- 只能配合变量使用,不能对常数自增自减
- 前操作:++a表示先做自增计算,再返回值;例如a=1;print(++a)输出结果为2;
- 后操作:a++表示先返回值,再做自增计算;例如a=1;print(a++)输出结果为1;
逻辑(关系)运算符
逻辑表达式的结果只有真和假,表达式成立为真(true),不成立为假(false)
数字0表示假,非0表示真
| 逻辑运算符 | 含义 |
|---|---|
| == | 等于 |
| != | 不等于 |
| >、>= | 大于、大于等于 |
| <、<= | 小于、小于等于 |
| ! | 非运算符,将结果转换为布尔类型,然后取反 |
| && | 逻辑与,&&左右两边同真为真,否则为假 |
| || | 逻辑或,||两边同假为假,否则为真 |
- (&&)和(||)存在短路特征:若左边表达式的结果能确定整个逻辑运算的结果就直接忽略右边表达式
- 短路与:左侧为假,则结果为假,右侧表达式不计算。
- 短路或:左侧为真,则结果为真,右侧表达式不计算。
int a = 10;
int b = 10;
//a短路,b不短路
if ( (a < 0 && a++) || (b > 0 && b++))
printf("a:%d\tb:%d\n", a, b); //输出结果为a:10 b:11
//a短路,b不短路
if ( (a > 0 || a++) && (b < 0 || b++))
printf("a:%d\tb:%d\n", a, b); //输出结果为a:10 b:12
位运算符
- 位运算符直接操作二进制数位内容,使用位运算符前提是将数据转换为二进制方式
- 位运算符包括:
按位与(&):两个操作数的对应位都为1时,结果为1。- 示例:
5 & 3=0101 & 0011,结果为1 (0001)。
- 示例:
按位或(|):两个操作数的对应位中至少有一个为1时,结果为1。- 示例:
5 | 3=0101 | 0011,结果为7 (0111)。
- 示例:
按位异或(^):两个操作数的对应位不同时,结果为1。- 示例:
5 ^ 3=0101 ^ 0011,结果为6 (0110)。
- 示例:
按位非(~):对操作数的每一位进行取反操作。- 示例:
~5(1111 1110 1111 1111 1111 1111 1111 1011),结果为-6(假设为4字节)。
- 示例:
左移(<<):将操作数的所有位向左移动指定的位数。- 示例:
5 << 2(0101向左移动2位变成10100),结果为20。 - 左移操作会将高位移出的数据丢弃,有无符号位都丢弃,低位填充0
- 示例:
右移(>>):将操作数的所有位向右移动指定的位数。- 示例:
20 >> 2(10100向右移动2位变成00010),结果为5。 - 右移会将低位的数据丢弃,高位填充符号位,无符号数右移填充0
- 示例:
- 位移运算符不会修改存储区的内容,一般配合赋值使用,将移位后的新数据赋值给变量

位运算符的一些常见用途包括:
- 设置特定位:使用或运算符(
|)可以设置特定位为1。 - 清除特定位:使用与运算符(
&)可以清除特定位为0。 - 切换特定位:使用异或运算符(
^)可以切换特定位的状态。 - 检查特定位:使用与运算符(
&)可以检查特定位是否为1。
三目运算符
- 格式:
布尔值(逻辑表达式)? 表达式1 : 表达式2- 若布尔值为真,则执行表达式1;若布尔值为假,则执行表达式2
#define MINCOST 10
#define HOURCOST 100
int time = 61;
int cost;
cost = (time < 60) ? MINCOST : HOURCOST;
print("cost=%d",cost); //输出结果为100
运算符优先级
| 优先级 | 类别 | 运算符 |
|---|---|---|
| 12 | 初等运算 | ()、[]、 . 、-> |
| 11 | 单目运算 | !、~、++、--、类型转换、&、*、sizeof |
| 10 | 算数运算 | *、/、% 高于 +、- |
| 9 | 移位运算 | <<、>> |
| 8 | 关系运算 | >、>=、<、<= 高于 ==、!= |
| 7 | 位与运算 | & |
| 6 | 异或运算 | ^ |
| 5 | 位或运算 | | |
| 4 | 逻辑运算 | ! 高于 && 高于 || |
| 3 | 条件运算 | ( ) ? ( ) : ( ) |
| 2 | 赋值运算 | =、+=、-+、*=、/=、%=、&=、|=、^=、>>=、<<= |
| 1 | 逗号运算 | , |
单目、三目和赋值运算符具有右结合序。例如:
-----a<==>-(--(--a))a>b?a:c>d?c:d<==>a>b?a:(c>d?c:d)a=b++c<==>a=(b+=c)
控制结构
分支结构
根据条件选择执行的代码块。包含if-else和switch语句
if分支结构
if(逻辑表达式){
语句块1;
}
- 如果逻辑表达式为真,就执行语句块1;
- 如果逻辑表达式为假,就不执行语句块1.
- 逻辑表达式:布尔值,可以作为布尔值的数据或表达式都可以放到圆括号中
- 通过判断逻辑表达式的真假,觉得是否执行某一语句块
if(逻辑表达式){
语句块1;
}
else{
语句块2;
}
- 如果逻辑表达式为真,就执行语句块1;
- 如果逻辑表达式为假,就执行语句块2;
if(逻辑表达式1){
语句块1;
}
else if(逻辑表达式2){
语句块2;
}
else{
语句块3;
}
if(逻辑表达式3)
语句块4; /*如果执行语句只有一句,可以不加{}*/
语句块5; /*语句5已经在条件判断范围之外,if条件为假也会执行*/
switch分支结构
/*switch语句格式*/
switch(控制表达式){
case 常量表达式1:
语句块1;
break;
case 常量表达式2:
语句块2;
break;
case 常量表达式2:
语句块2;
break;
...
default:
语句块0;
break;
}
循环结构
根据条件重复执行一段代码块。包含for、while、do-while循环语句
for循环
for(表达式1;表达式2;表达式3){
语句块4;
}
/*
表达式1只会在最开始执行一次,可以在表达式1中定义局部变量,循环结束后局部变量会自动释放
表达式2作为条件判断语句,如果条件成立就执行[4][3]代码,执行完成后再判断是否循环
表达式3在语句块4全部执行完之后才执行
语句块4在表达式2判断成立之后就会立即执行,语句块4执行完之后会执行表达式3
*/
-
for循环中小括号的每条语句都可以省略,如
for(;;) -
若小括号中间表达式省略表示循环条件判定一直为真,成为死循环,可以使用break语句结束循环
for(;;){ ... break; ... } -
表达式1中可以定义局部变量,循环结束后局部变量会自动(C99规范)
-
如果循环体只有一条语句,可以不用加{}
for(int i=0;i<10;i++) j++; -
break:用于强制退出循环结构
- 执行到
break语句时,会立即退出当前循环体,循环体中后续代码不再执行
- 执行到
-
continue:用于结束本次循环,继续下次循环
- 当程序执行到
continue语句时,循环体中后续代码不再执行,而是回到循环结构的条件判断处,开始下次循环
- 当程序执行到
while循环
while循环可以看作简化版的for循环
while(条件表达式){
循环体;
}
- 条件表达式,运算结果为布尔值
- 如果条件为真,则运行循环体代码,直到条件表达式布尔值为假时结束
- 如果条件表达式的布尔值永远为真,则成为死循环
- while循环也可以使用
break;和continue;语句,作用和在for循环中一样
do-while循环
do{
循环体;
}while(条件表达式);
- do-while循环和while循环区别:
- while循环先进行条件判断再执行循环代码
- do-while循环则是先执行循环代码再进行条件判断
- while循环以{ }结束
- do-while需要在
while( );后使用分号结束 - while循环中的循环体可能1次都不执行
- do-while中循环体的语句至少执行1次
goto
goto语句是一种无条件跳转语句,它允许程序的控制流跳转到程序中预先定义的标签(label)处。使用goto语句可以跳出多层循环或复杂的代码结构,直接跳转到指定的位置执行。
#include <stdio.h>
int main() {
int i;
// 外层循环
for (i = 0; i < 5; i++) {
printf("Outer loop: %d\n", i);
// 内层循环
for (int j = 0; j < 5; j++) {
if (j == 3) {
// 当j等于3时,跳转到end标签
goto end;
}
printf(" Inner loop: %d\n", j);
}
}
end:
printf("Jumped out of loops.\n");
return 0;
}
虽然goto语句在某些情况下可以简化程序的编写,但由于其使用导致程序的结构更具复杂,代码的可读性和可维护性降低,因此往往不鼓励使用goto语句

 浙公网安备 33010602011771号
浙公网安备 33010602011771号