
mongodb复制+分片集原理
----------------------------------------复制集----------------------------------------
一、复制集概述
Mongodb复制集(replica set)由一组Mongod实例(进程)组成,包含一个Primary节点和多个Secondary节点,Mongodb Driver(客户端)的所有数据都写入Primary,Secondary通过oplog来同步Primary的数据,保证主从节点数据的一致性;复制集在完成主从复制的基础上,通过心跳机制,一旦Primary节点出现宕机,则触发选举一个新的主节点,剩下的secondary节点指向新的Primary,时间应该在10-30s内完成感知Primary节点故障,实现高可用数据库集群
特点:
Primary节点是唯一的,但不是固定的
由大多数据原则保证数据的一致性
Secondary节点无法写入(默认情况下,不使用驱动连接时,也是不能查询的)
相对于传统的主从结构,复制集可以自动容灾
二、复制集原理
角色(按是否存储数据划分):
Primary:主节点,由选举产生,负责客户端的写操作,产生oplog日志文件
Secondary:从节点,负责客户端的读操作,提供数据的备份和故障的切换
Arbiter:仲裁节点,只参与选举的投票,不会成为primary,也不向Primary同步数据,若部署了一个2个节点的复制集,1个Primary,1个Secondary,任意节点宕机,复制集将不能提供服务了(无法选出Primary),这时可以给复制集添加一个Arbiter节点,即使有节点宕机,仍能选出Primary
角色(按类型区分):
Standard(标准):这种是常规节点,它存储一份完整的数据副本,参与投票选举,有可能成为主节点
Passive(被动):存储完整的数据副本,参与投票,不能成为活跃节点
Arbiter(投票):仲裁节点只参与投票,不接收复制的数据,也不能成为活跃节点
注:每个参与节点(非仲裁者)有个优先权(0-1000),优先权(priority)为0则是被动的,不能成为活跃节点,优先权不为0的,按照由大到小选出活跃节点,优先值一样的则看谁的数据比较新
注:Mongodb 3.0里,复制集成员最多50个,参与Primary选举投票的成员最多7个
选举:
每个节点通过优先级定义出节点的类型(标准、被动、投票)
标准节点通过对比自身数据进行选举出primary节点或者secondary节点
影响选举的因素:
1.心跳检测:复制集内成员每隔两秒向其他成员发送心跳检测信息,若10秒内无响应,则标记其为不可用
2.连接:在多个节点中,最少保证两个节点为活跃状态,如果集群中共三个节点,挂掉两个节点,那么剩余的节点无论状态是primary还是处于选举过程中,都会直接被降权为secondary
触发选举的情况:
1.初始化状态
2.从节点们无法与主节点进行通信
3.主节点辞职
主节点辞职的情况:
1.在接收到replSetStepDown命令后
2.在现有的环境中,其他secondary节点的数据落后于本身10s内,且拥有更高优先级
3.当主节点无法与群集中多数节点通信
注:当主节点辞职后,主节点将关闭自身所有的连接,避免出现客户端在从节点进行写入操作
----------------------------------------分片----------------------------------------
一、分片概述
分片(sharding)是指将数据库拆分,将其分散在不同的机器上的过程。分片集群(sharded cluster)是一种水平扩展数据库系统性能的方法,能够将数据集分布式存储在不同的分片(shard)上,每个分片只保存数据集的一部分,MongoDB保证各个分片之间不会有重复的数据,所有分片保存的数据之和就是完整的数据集。分片集群将数据集分布式存储,能够将负载分摊到多个分片上,每个分片只负责读写一部分数据,充分利用了各个shard的系统资源,提高数据库系统的吞吐量
注:mongodb3.2版本后,分片技术必须结合复制集完成
应用场景:
1.单台机器的磁盘不够用了,使用分片解决磁盘空间的问题
2.单个mongod已经不能满足写数据的性能要求。通过分片让写压力分散到各个分片上面,使用分片服务器自身的资源
3.想把大量数据放到内存里提高性能。和上面一样,通过分片使用分片服务器自身的资源
二、分片存储原理
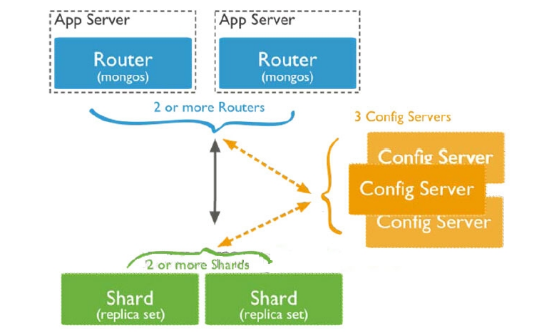
存储方式:
数据集被拆分成数据块(chunk),每个数据块包含多个doc,数据块分布式存储在分片集群中
角色:
Config server:MongoDB负责追踪数据块在shard上的分布信息,每个分片存储哪些数据块,叫做分片的元数据,保存在config server上的数据库 config中,一般使用3台config server,所有config server中的config数据库必须完全相同(建议将config server部署在不同的服务器,以保证稳定性)
Shard server:将数据进行分片,拆分成数据块(chunk),数据块真正存放的单位
Mongos server:数据库集群请求的入口,所有的请求都通过mongos进行协调,查看分片的元数据,查找chunk存放位置,mongos自己就是一个请求分发中心,在生产环境通常有多mongos作为请求的入口,防止其中一个挂掉所有的mongodb请求都没有办法操作
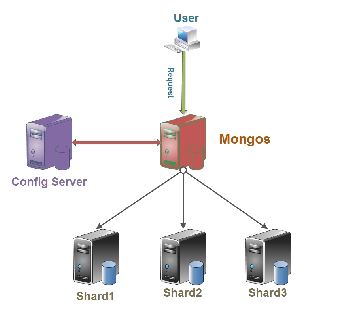
总结:
应用请求mongos来操作mongodb的增删改查,配置服务器存储数据库元信息,并且和mongos做同步,数据最终存入在shard(分片)上,为了防止数据丢失,同步在副本集中存储了一份,仲裁节点在数据存储到分片的时候决定存储到哪个节点
三、分片的片键
片键是文档的一个属性字段或是一个复合索引字段,一旦建立后则不可改变,片键是拆分数据的关键的依据,如若在数据极为庞大的场景下,片键决定了数据在分片的过程中数据的存储位置,直接会影响集群的性能
注:创建片键时,需要有一个支撑片键运行的索引
片键分类:
1.递增片键:使用时间戳,日期,自增的主键,ObjectId,_id等,此类片键的写入操作集中在一个分片服务器上,写入不具有分散性,这会导致单台服务器压力较大,但分割比较容易,这台服务器可能会成为性能瓶颈

语法解析: mongos> use 库名 mongos> db.集合名.ensureIndex({"键名":1}) ##创建索引 mongos> sh.enableSharding("库名") ##开启库的分片 mongos> sh.shardCollection("库名.集合名",{"键名":1}) ##开启集合的分片并指定片键
2.哈希片键:也称之为散列索引,使用一个哈希索引字段作为片键,优点是使数据在各节点分布比较均匀,数据写入可随机分发到每个分片服务器上,把写入的压力分散到了各个服务器上。但是读也是随机的,可能会命中更多的分片,但是缺点是无法实现范围区分

3.组合片键: 数据库中没有比较合适的键值供片键选择,或者是打算使用的片键基数太小(即变化少如星期只有7天可变化),可以选另一个字段使用组合片键,甚至可以添加冗余字段来组合

4.标签片键:数据存储在指定的分片服务器上,可以为分片添加tag标签,然后指定相应的tag,比如让10.*.*.*(T)出现在shard0000上,11.*.*.*(Q)出现在shard0001或shard0002上,就可以使用tag让均衡器指定分发


 浙公网安备 33010602011771号
浙公网安备 33010602011771号