RCNN
区域卷积神经网络(Regions with CNN features,简称 R-CNN) ,用于目标检测。
R-CNN: https://arxiv.org/abs/1311.2524
它的思路很简单,有些类似传统数据结构算法中的暴力搜索,即找出图像中所有可能存在目标的区域,对每个区域进行一次识别。
流程图可以表示为下图:
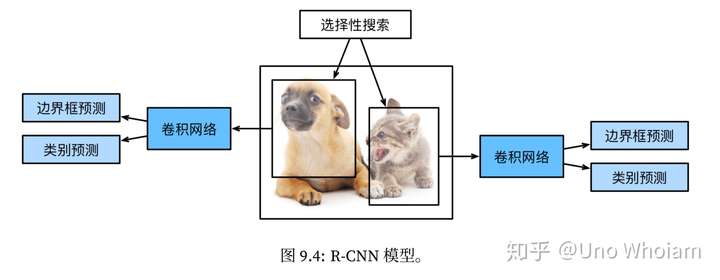
具体来说,它主要由以下四步构成:

- 候选区域生成:对每张输入图像使用选择性搜索来选取多个高质量的候选区域(Region Proposal)。这个算法先对图像基于像素信息做快速分割来得到多个区域,然后将当下最相似的两区域合并成一个区域,重复进行合并直到整张图像变成一个区域。最后根据合并的信息生成多个有层次结构的提议区 域,并为每个提议区域生成物体类别和真实边界框。
- 特征提取:选取一个预先训练好的卷积神经网络,去掉最后的输出层来作为特征抽取模块。对每个提议区域,将其变形成卷积神经网络需要的输入尺寸后进行前向计算抽取特征。
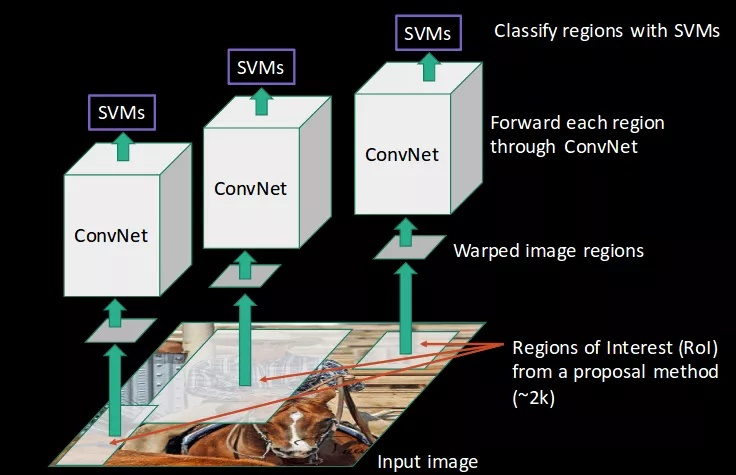
- SVM分类器:将每个提议区域的特征连同其标注做成一个样本,训练多个支持向量机(SVM)来进行物 体类别分类,这里第 i 个 SVM 预测样本是否属于第 i 类。
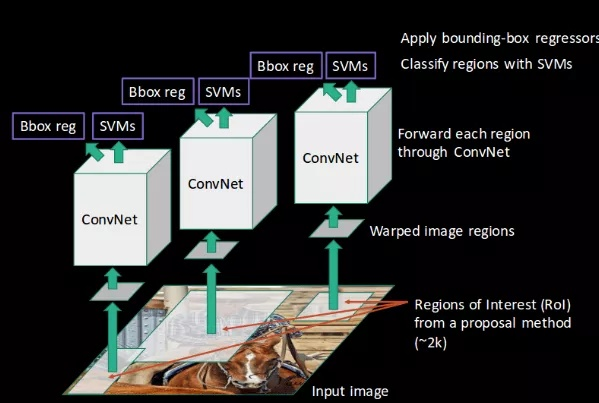
- 边界框回归器:在这些样本上训练一个线性回归模型来预测(精修)真实边界框。对于SVM分好类的候选区域做边框回归,用Bounding box回归值校正原来的建议窗口,生成预测窗口坐标
第一步 候选区域生成

图像是如何生成候选区域的呢?
参考链接:
【目标检测】RCNN算法详解 - shenxiaolu1984的专栏 - CSDN博客
Selective Search for Object Recognition
Selective Search 方法:
- 使用一种过分割手段,将图像分割成小区域
- 查看现有小区域,合并可能性最高的两个区域。重复直到整张图像合并成一个区域位置
- 输出所有曾经存在过的区域,所谓候选区域
候选区域生成和后续步骤相对独立,实际可以使用任意算法进行。
合并规则:
优先合并以下四种区域:
- 颜色(颜色直方图)相近的
- 纹理(梯度直方图)相近的
- 合并后总面积小的
- 合并后,总面积在其BBOX中所占比例大的
保证合并操作的尺度较为均匀,避免一个大区域陆续“吃掉”其他小区域。
例:
设有区域a-b-c-d-e-f-g-h。较好的合并方式是:ab-cd-ef-gh -> abcd-efgh -> abcdefgh。
不好的合并方法是:ab-c-d-e-f-g-h ->abcd-e-f-g-h ->abcdef-gh -> abcdefgh。
保证合并后形状规则。

例:左图适于合并,右图不适于合并。
上述规则只涉及区域的颜色直方图、纹理直方图、面积和位置。合并后的区域特征可以直接由子区域特征计算而来,速度较快。
多样化与后处理:
为尽可能不遗漏候选区域,上述操作在多个颜色空间中同时进行(RGB,HSV,Lab等)。在一个颜色空间中,使用上述四条规则的不同组合进行合并。所有颜色空间与所有规则的全部结果,在去除重复后,都作为候选区域输出。

第二步 特征提取
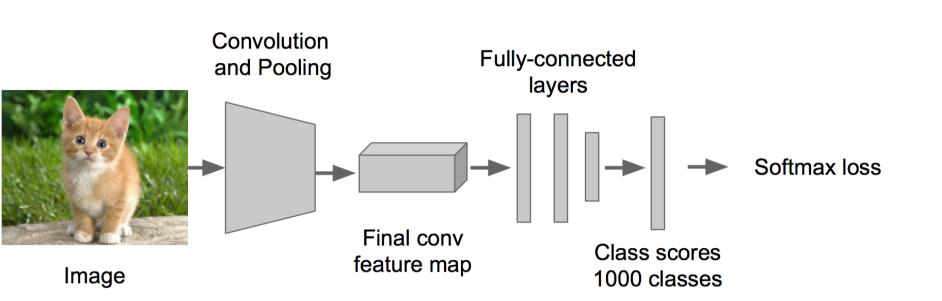
当边框方案生成之后,R-CNN 把选取区域变形为标准的方形,并将之喂给卷积神经网络,可以使用预先训练好的卷积神经网络可以选择训练好的AlexNet、VGG etc.
1:预训练 训练(或者下载)一个分类模型(比如AlexNet)
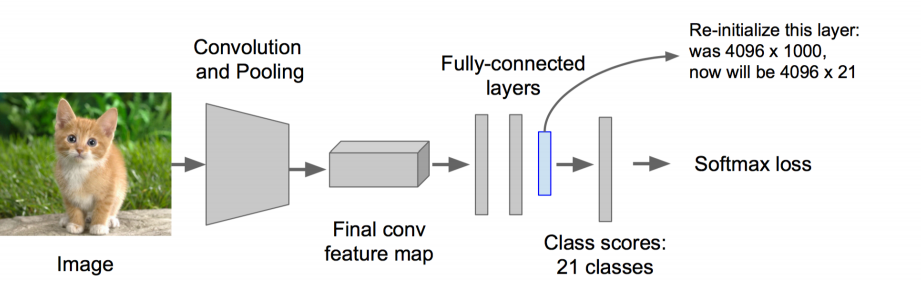
2:对该模型做fine-tuning
• 将分类数从1000改为21,比如20个物体类别 + 1个背景
• 去掉最后一个全连接层
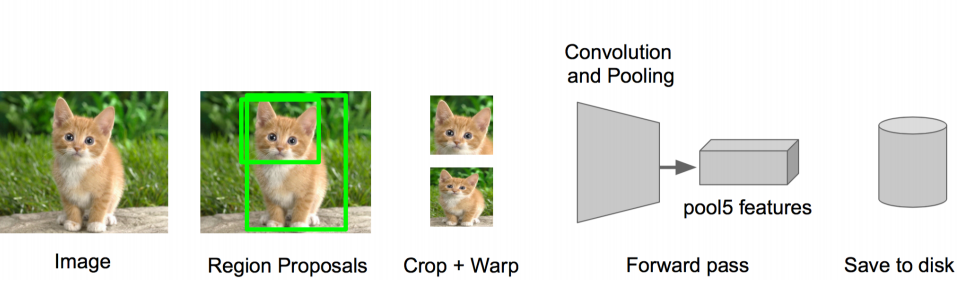
 3:特征提取
3:特征提取
• 提取图像的所有候选框(选择性搜索Selective Search)
• 对于每一个区域:修正区域大小以适合CNN的输入,做一次前向运算,将第五个池化层的输出(就是对候选框提取到的特征)存到硬盘
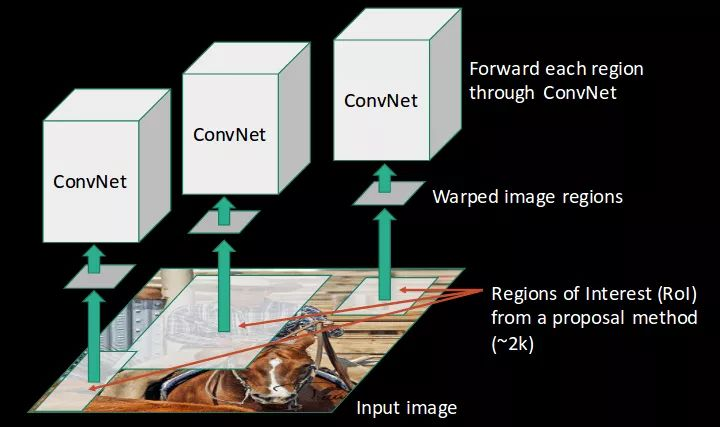
第三步 SVM分类器
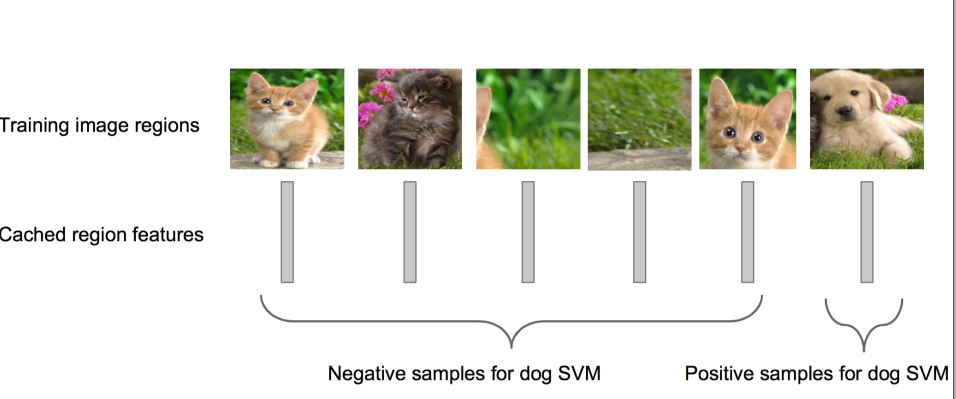
它要做的事很简单:对这是否是一个物体进行分类,如果是,是什么物体。具体做法是,训练一个SVM分类器(二分类)来判断这个候选框里物体的类别,每个类别对应一个SVM,判断是不是属于这个类别,是就是positive,反之nagative。
比如下图,就是狗分类的SVM
第四步 bounding box regression
使用边框回归(Bounding Box Regression)精细修正候选框位置。
参考链接:边框回归(Bounding Box Regression)详解、bounding box regression

所以,概括一下,R-CNN 只是以下几个简单的步骤
1. 为边界框生成一组提案。
2. 通过预训练的 AlexNet 运行边界框中的图像,最后通过 SVM 来查看框中图像的目标是什么。
3. 通过线性回归模型运行边框,一旦目标完成分类,输出边框的更紧密的坐标。
R-CNN 这个方法可以得出比较正确的物体检测结果,但问题在于太慢了。它对之前物体识别算法的主要改进是使用了预先训练好的卷积神经网络来抽取特征,有效的提升了识别精度。对一张图像我们可能选出上千个兴趣区域,每个兴趣区域都要放入卷积网络,进行识别,这个计算量无疑是非常巨大以至于无法实际运用。
为了解决这个问题,便有了 Fast-RCNN

 浙公网安备 33010602011771号
浙公网安备 33010602011771号