第四周作业
1. 自定义写出10个定时任务的示例:
SHELL=/bin/bash PATH=/usr/lib64/qt-3.3/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin/ MAILTO=root * * * 1-12/3 * rm -rf rubbish #每三个月删除一次垃圾文件 30 1 * * * cp -a /data/ /backup #每天1点30备份data内的文件 15 6 */10 * * ls >> /data/ls.txt #每隔10天6点15执行ls命令 30 8-10/1 * * * ls >> /data/ls.txt;ip a &> /data/ip.log #8点30,9点30,10点30执行ls;ip a命令 * 6-10/2 * * 1,5 data >> /data/data.log #每周1或周五6,8,10点执行date命令 30 1 * * 6 systemctl restart httpd #每周6的1点30分重启http服务 30 1 * * 0 systemctl stop sshd#每周日1点30分关闭ssh服务 * 6,18 * * 0,1,2 /data/check.sh #每周7或1或周2的6点,18点执行一次check.sh脚本 * 1 * * * df -Th >> /data/df.log #每隔1小时执行df -Th命令 18 8 1,10,20 * * ehtool bond0 &> /data/bond.log #每个月的1号10号20号8点18分执行ehtool bond0命令
2. 图文并茂说明Linux进程和内存概念
进程概念
进程:是运行程序的副本,将程序动态的运行起来,就转成进程,操作系统通过给进程分配资源(如内存空间、文件描述符等)来控制和管理进程的执行,
包含进程的创建,进程的运行以及进程消亡,确保它们能够正确地完成任务。进程是操作系统分配资源的最小单位
线程:线程是程序执行的最小单位。一个进程由多个线程组成,进程最少只有一个线程
进程一般包含两种:前台进程和后台进程
内存:是运行进程的空间,CPU待处理的数据和运行的程序暂时存储的空间

进程使用问题
1.内存泄漏
指程序中用malloc或new申请了一块内存,但是没有用free或delete将内存释放,导致这块内存一直处于占用状态
2. 内存溢出
指程序申请了10M的空间,但是在这个空间写入10M以上字节的数据,就是溢出,
3. 进程过度分配内存:
进程在运行过程中可能会分配过多的内存资源,超过实际需要的大小。这种情况下,会浪费系统内存资源,并可能导致其他进程无法分配到足够的内存。
4. 内存不足
应用分配内存太少或者用的太多,并且用完没有释放,导致浪费,此时就会造成内存泄漏或溢出
进程状态
R running 状态就是运行状态S sleeping 状态是睡眠状态(浅度睡眠)又叫可中断睡眠 小s是会话 子进程发起者D 状态是深度睡眠状态(磁盘休眠)又叫不可中断睡眠T stopped是暂停状态t(tracing stop)追踪暂停状态Z zombie僵尸状态X 死亡状态l 多线程
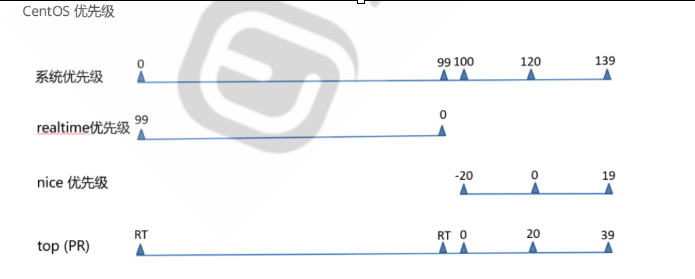
进程优先级
进程优先级是操作系统中用来确定处理器分配时间的重要参数之一。进程优先级较高的进程在竞争处理器资源时会被优先调度,并获得较多的处理器时间。
常见的进程优先级取值范围是0到127,其中0表示最低优先级,127表示最高优先级。
系统优先级: 0-139,数字越小,优先级越高,各有140个运行队列和过期队列
实时优先级:99-0值最大优先级最高,非实时进程优先级低 100-139
nice值: -20到19,对应系统优先级100-139 20以上就是高优先级对应0-99
top:高优先级RT对应0-99值 低优先级0-39 对应100-139
3. 图文并茂说明Linux启动流程
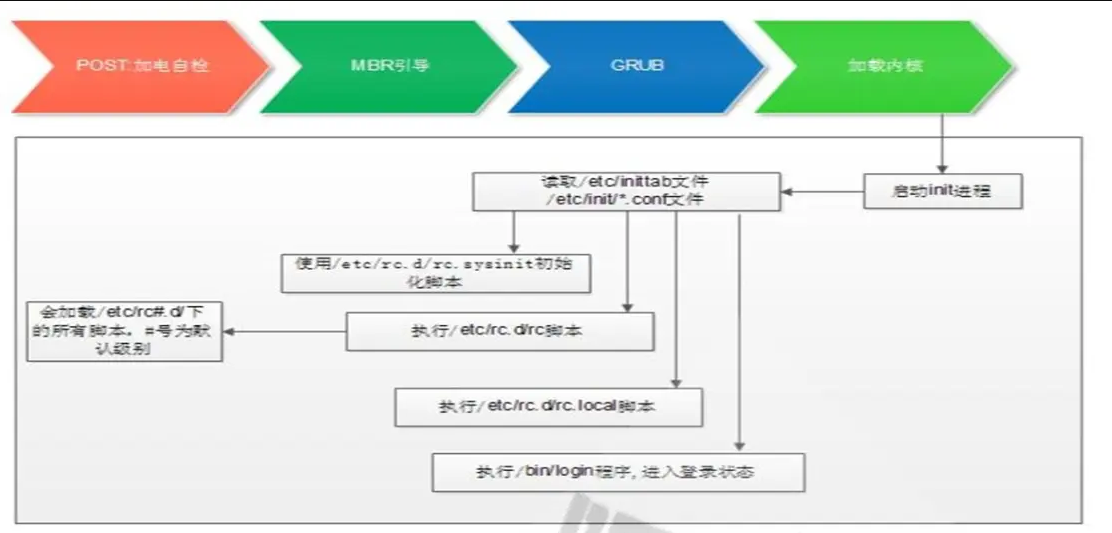
CentOS6启动流程
(1) 加载BIOS的硬件信息,获取第一个启动设备
(2) 读取第一个启动设备MBR的引导加载程序(grub)的启动信息
(3) 加载核心操作系统的核心信息,核心开始解压缩,并尝试驱动所有的硬件设备
(4) 核心执行init程序,并获取默认的运行信息
(5)init程序执行/etc/rc.d/rc.sysinit文件,重新挂载根文件系统
(6)启动核心的外挂模块
(7)init执行运行的各个批处理文件(scripts)
(8) init执行/etc/rc.d/rc.local
(9)执行/bin/login程序,等待用户登录
(10)登录之后开始以Shell控制主机
CentOS7以后启动流程
(1) UEFi或BIOS初始化,运行POST开机自检
(2) 选择启动设备
(3) 引导装载程序, centos7是grub2,加载装载程序的配置文件:
/etc/grub.d/
/etc/default/grub
/boot/grub2/grub.cfg
(4) 加载initramfs驱动模块
(5) 加载内核选项
(6)内核初始化,centos7使用systemd代替init
(7) 执行initrd.target所有单元,包括挂载/etc/fstab
(8) 从initramfs根文件系统切换到磁盘根目录
(9) systemd执行默认target配置,配置文件/etc/systemd/system/default.target
(10)systemd执行sysinit.target初始化系统及basic.target准备操作系统
(11) systemd启动multi-user.target下的本机与服务器服务
(12) systemd执行multi-user.target下的/etc/rc.d/rc.local
(13) Systemd执行multi-user.target下的getty.target及登录服务
(14)systemd执行graphical需要的服务
4. 自定义一个systemd服务定时去其他服务器上检查/tmp/下文件的个数,如果发现数量有变化就记录变化情况到文件中。
1.脚本
#!/bin/bash
#vim/data/script/check_tmp.sh
#chmod +x /data/script/check_tmp.sh
#1) 检查远程文件数量
current_count=$(ssh root@192.168.80.101 "ls -1 /tmp/ | wc -l")
# 读取上一次保存的文件数量
last_count=$(cat /data/ceck_tmp/last_count.txt)
# 如果当前数量和上次保存的数量不一致,则记录变化情况到文件中
if [[ $current_count -ne $last_count ]]; then
date +"%Y-%m-%d %H:%M:%S - File count changed: $current_count" >> /data/ceck_tmp/change_log.txt
fi
# 保存当前文件数量到文件中,以供下次比较
echo "$current_count" &> /data/ceck_tmp/last_count.txt
2.systemd服务
#/lib/systemd/system
[Unit] Description=check tmp
[Service] TimeoutStartSec=0 ExecStart=/bin/sh -c "ssh root@192.168.80.101 bash /data/script/check_tmp.sh" #基于key验证
ExecStop=ps auxf | grep check_tmp.sh |awk '{print $2}' |xargs kill -9 2>/dev/null
ExecReload=/bin/kill -s HUP $MAINPID
[Install] Wantedby=multi-user.target
systemctl daemon-reload
systemctl enable --now find.service
5. 写Linux内核编译安装博客
6. 总结5个自我觉得比较有用的awk的使用场景,比如在什么情况下用awk处理文本效率最高,发散题,至少写1个。
awk简介
awk就好像一门编程语言,是GNU项目三个人一起写的 a w k 组成awk,也叫gawkAWK 是一种用于文本处理和数据提取的依次查询工具,在 AWK 脚本中,可以使用BEGIN和END关键字定义在处理输入之前和之后执行的块。BEGIN块在处理输入之前执行一次。它通常用于初始化变量、打印标题行或执行其他需要在处理输入之前完成的操作。使用BEGIN块时,它必须放在 AWK 脚本的开头,并用花括号{}包围。
作用:
- 1、按行查找文件内容
- 2、模糊过滤文件内容
- 3、按照列查找文件内容,可以对文件内容取列
- 4、还可以做数值运算,数值比对,字符串比对
- 5、支持for循环,while循环,if判断,数组,格式化输出
- 6、
awk '找谁{干啥}' file ( []'' /正则/ {print $1})
awk '查找' file 没有动作会输出所有的行(对每行进行一个默认的动作处理 输出)
df -h|awk '查找{干啥}'
#打印 data.txt 文件中包含 “pattern” 的每一行 awk '/pattern/ { print $0 }' data.txt
#先模糊过滤找行“root”,再找以冒号分割最后一列减2 得到倒数第3列 cat /etc/passwd |awk -F: '/root/{print $(NF-2)}'
#取第三四五行的第2列和最后一列 awk 'NR>2&&NR<6{print $2,$NF}' file
#数组: 取反去重
awk {!line[$0]++ ; print $0} file

 浙公网安备 33010602011771号
浙公网安备 33010602011771号