
Java分布式锁方案和区别 - Redis,Zookeeper,数据库 - redisson demo
Java分布式锁方案和区别 - Redis,Zookeeper,数据库
1. 基于 Redis 的实现
在 Redis 中有 3 个重要命令,通过这三个命令可以实现分布式锁
setnx key val:当且仅当key不存在时,set一个key为val的字符串,返回1;若key存在,则什么都不做,返回0。
expire key timeout:为key设置一个超时时间,单位为second,超过这个时间 key 会自动删除。
delete key:删除key
Redission 实现
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.5.0</version>
</dependency>
import org.redisson.Redisson; import org.redisson.api.RLock; import org.redisson.api.RedissonClient; import org.redisson.config.Config; import java.util.concurrent.TimeUnit; public class RedissonTest { /** * 未获取到锁 * 未释放锁 * @param args */ public static void main(String[] args) { Config config = new Config(); config.useSingleServer().setAddress("redis://127.0.0.1:6379").setPassword("xxxxxx").setDatabase(0); RedissonClient redissonClient = Redisson.create(config); RLock rLock = redissonClient.getLock("lockKey240808"); boolean locked = false; try { /* * waitTimeout 尝试获取锁的最大等待时间,超过这个值,则认为获取锁失败 * leaseTime 锁的持有时间,超过这个时间锁会自动失效 */ locked = rLock.tryLock((long) 30, (long) 300, TimeUnit.SECONDS); if (!locked) { // 没有获取锁的逻辑 System.out.println("未获取到锁"); }else{ // 获取锁的逻辑 System.out.println("获取到锁"); } } catch (Exception e) { throw new RuntimeException("aquire lock fail"); } finally { // if(locked) { // rLock.unlock(); // System.out.println("释放锁"); // } System.out.println("未释放锁"); } } }
查看redisson key数据类型
type lockKey240808 hash hgetall lockKey240808 1) 0d46aa7f-424f-45f3-b3a8-b56ec4f59ce6:1 2) 1
redis hset 哈希表操作添加json串为单引号且客户端窗口需要最大化,字符串不能断行
https://www.cnblogs.com/oktokeep/p/16999417.html
注意点:
waitTime 为了获取锁愿意等待的时长 <= 0 不愿意等待,即没有获取到锁时直接返回false
leaseTime 加锁成功后自动释放锁的时长:
>0 时 不论锁定的业务是否执行完毕都会在这个时间到期时释放锁---这个很要命(一定不会死锁);肯能会存在线程1执行业务没有完毕,锁自动释放了,线程2获取到锁执行了业务,锁失效了;
=-1表示这个锁不会自动释放必须手动释放(可能会死锁),看门狗每10秒(默认配置)延期一次锁(实际是重置锁的过期时间为30秒:默认配置)
Redission 通过续约机制,每隔一段时间去检测锁是否还在进行,如果还在运行就将对应的 key 增加一定的时间,保证在锁运行的情况下不会发生 key 到了过期时间自动删除的情况
2. 基于 Zookeeper 的实现
2.1 实现原理
基于zookeeper临时有序节点可以实现的分布式锁。
大致步骤:客户端对某个方法加锁时,在 zookeeper 上的与该方法对应的指定节点的目录下,生成一个唯一的临时有序节点。 判断是否获取锁的方式很简单,只需要判断有序节点中序号最小的一个。 当释放锁的时候,只需将这个瞬时节点删除即可。同时,其可以避免服务宕机导致的锁无法释放,而产生的死锁问题。
使用:
compile "org.springframework.integration:spring-integration-zookeeper:5.1.2.RELEASE"
//增加配置 @Configuration public class ZookeeperLockConfig { @Value("${zookeeper.host}") private String zkUrl; @Bean public CuratorFrameworkFactoryBean curatorFrameworkFactoryBean() { return new CuratorFrameworkFactoryBean(zkUrl); } @Bean public ZookeeperLockRegistry zookeeperLockRegistry(CuratorFramework curatorFramework) { return new ZookeeperLockRegistry(curatorFramework, "/lock"); } } @Autowired private ZookeeperLockRegistry lockRegistry; Lock lock = lockRegistry.obtain(key); boolean locked = false; try { locked = lock.tryLock(); if (!locked) { // 没有获取到锁的逻辑 } // 获取锁的逻辑 } finally { // 一定要解锁 if (locked) { lock.unlock(); } }
3. 基于数据库的实现
3.1 实现原理
create table distributed_lock (
id int(11) unsigned NOT NULL auto_increment primary key,
key_name varchar(30) unique NOT NULL comment '锁名',
update_time datetime default current_timestamp on update current_timestamp comment '更新时间'
)ENGINE=InnoDB comment '数据库锁';
方式一:通过 insert 和 delete 实现
使用数据库唯一索引,当我们想获取一个锁的时候,就 insert 一条数据,如果 insert 成功则获取到锁,获取锁之后,通过 delete 语句来删除锁
这种方式实现,锁不会等待,如果想设置获取锁的最大时间,需要自己实现
方式二:通过for update 实现
以下操作需要在事务中进行
select * from distributed_lock where key_name = 'lock' for update;
在查询语句后面增加 for update,数据库会在查询过程中给数据库表增加排他锁。当某条记录被加上排他锁之后,其他线程无法再在该行记录上增加排他锁。for update 的另一个特性就是会阻塞,这样也间接实现了一个阻塞队列,但是 for update 的阻塞时间是由数据库决定的,而不是程序决定的。
在 MySQL 8 中,for update 语句可以加上 nowait 来实现非阻塞用法
select * from distributed_lock where key_name = 'lock' for update nowait;
在 InnoDB 引擎在加锁的时候,只有通过索引查询时才会使用行级锁,否则为表锁,而且如果查询不到数据的时候也会升级为表锁。
这种方式需要在数据库中实现已经存在数据的情况下使用。
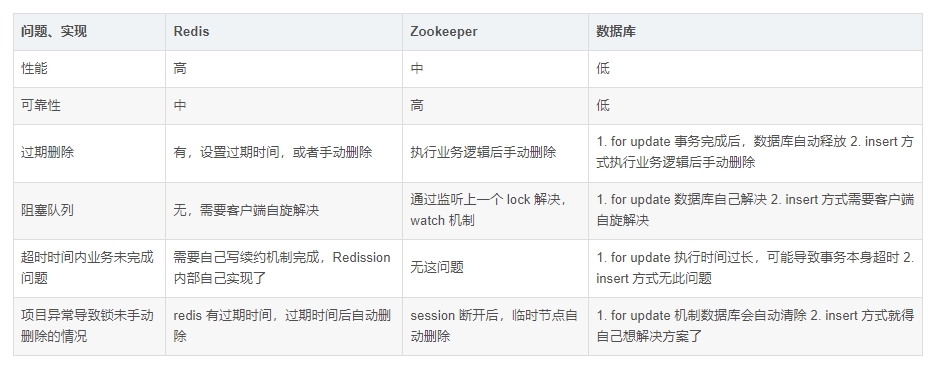
对比
从性能角度(从高到低)缓存 > Zookeeper >= 数据库
从可靠性角度(从高到低)Zookeeper > 缓存 > 数据库

 浙公网安备 33010602011771号
浙公网安备 33010602011771号