[论文阅读]A_Real-Time_Incremental_Video_Mosaic_Framework_for_UAVRemote_Sensing
Article
文章
A Real-Time Incremental Video Mosaic Framework for UAV Remote Sensing
一种用于无人机遥感的实时增量视频拼接框架
Ronghao Li \({}^{1}\) , Pengqi Gao \({}^{2}\) , Xiangyuan Cai \({}^{1}\) , Xiaotong Chen \({}^{1}\) , Jiangnan Wei \({}^{1}\) , Yinqian Cheng \({}^{3}\) and Hongying Zhao \({}^{1, * }\) 1 School of Earth and Space Sciences, Peking University, Beijing 100871, China 2 National Astronomical Observatories, Chinese Academy of Sciences, Beijing 100864, China 3 Information Network Center, China University of Geosciences, Beijing 100083, China * Correspondence: zhaohy@pku.edu.cn
李荣浩 \({}^{1}\)、高鹏琪 \({}^{2}\)、蔡祥远 \({}^{1}\)、陈小桐 \({}^{1}\)、魏江南 \({}^{1}\)、程银倩 \({}^{3}\) 和赵红英 \({}^{1, * }\) 1 北京大学地球与空间科学学院,北京 100871,中国 2 中国科学院国家天文台,北京 100864,中国 3 中国地质大学信息网络中心,北京 100083,中国 * 通信作者:zhaohy@pku.edu.cn
Abstract: Unmanned aerial vehicles (UAVs) are becoming increasingly popular in various fields such as agriculture, forest protection, resource exploration, and so on, due to their ability to capture high-resolution images quickly and efficiently at low altitudes. However, real-time image mosaicking of UAV image sequences, especially during long multi-strip flights, remains challenging. In this paper, a real-time incremental UAV image mosaicking framework is proposed, which only uses the UAV image sequence, and does not rely on global positioning system (GPS), ground control points (CGPs), or other auxiliary information. Our framework aims to reduce spatial distortion, increase the speed of the operation in the mosaicking process, and output high-quality panorama. To achieve this goal, we employ several strategies. First, the framework estimates the approximate position of each newly added frame and selects keyframes to improve efficiency. Then, the matching relationship between keyframes and other frames is obtained by using the estimated position. After that, a new optimization method based on minimizing weighted reprojection errors is adopted to carry out precise position calculation of the current frame, so as to reduce the deformation caused by cumulative errors. Finally, the weighted partition fusion method based on the Laplacian pyramid is used to fuse and update the local image in real time to achieve the best mosaic result. We have carried out a series of experiments which show that our system can output high-quality panorama in real time. The proposed keyframe selection strategy and local optimization strategy can minimize cumulative errors, the image fusion strategy is highly robust, and it can effectively improve the panorama quality.
摘要:由于能够在低空快速高效地捕捉高分辨率图像,无人机(Unmanned aerial vehicles,UAVs)在农业、森林保护、资源勘探等多个领域越来越受欢迎。然而,无人机图像序列的实时图像拼接,尤其是在长距离多航带飞行过程中,仍然具有挑战性。本文提出了一种实时增量式无人机图像拼接框架,该框架仅使用无人机图像序列,不依赖全球定位系统(Global positioning system,GPS)、地面控制点(Ground control points,GCPs)或其他辅助信息。我们的框架旨在减少空间畸变,提高拼接过程的操作速度,并输出高质量的全景图像。为实现这一目标,我们采用了多种策略。首先,该框架估计每个新添加帧的大致位置并选择关键帧以提高效率。然后,利用估计的位置获取关键帧与其他帧之间的匹配关系。之后,采用一种基于最小化加权重投影误差的新优化方法对当前帧进行精确位置计算,以减少累积误差导致的变形。最后,使用基于拉普拉斯金字塔的加权分区融合方法实时融合和更新局部图像,以获得最佳拼接效果。我们进行了一系列实验,结果表明我们的系统能够实时输出高质量的全景图像。所提出的关键帧选择策略和局部优化策略可以将累积误差降至最低,图像融合策略具有很强的鲁棒性,能够有效提高全景图像的质量。
Keywords: UAV remote sensing; image mosaicking; homography estimation; local optimization
关键词:无人机遥感(UAV remote sensing);图像拼接(image mosaicking);单应性估计(homography estimation);局部优化(local optimization)
1. Introduction
1. 引言
The increasing demand for high-resolution remote sensing images and basic geographic information across various sectors of society is driven by the development of the social economy and the need for national defense. This demand has become increasingly pressing and requires immediate attention. Moreover, the current demands for these products are progressively increasing regarding their level of quality. While satellite, airplane, and radar remote sensing data have their respective applications, in some cases they may not fully satisfy the needs of image data acquisition and processing. Compared to traditional aerospace remote sensing technology, UAV low-altitude remote sensing technology, as a new low-altitude remote sensing technology, has many advantages such as high flexibility, easy operation, high resolution, and low investment [1]. Most UAVs mainly work at a low altitude. As a result, the area that a single image can cover is small. Consequently, image mosaicking is an important technique for utilizing UAV multi-strip mage data. In general, image mosaicking involves various steps of processing: registration, reprojection, stitching, and blending [2]. According to registration algorithms, image mosaicking can be divided into spatial domain-based algorithms and frequency domain-based algorithms. At the same time, some adopt the deep learning algorithms to do the image stitching end to end. In addition, many researchers have proposed new methods for UAV image mosaicking based on general image mosaicking. We will introduce each of these algorithms in the following sections.
随着社会经济的发展和国防建设的需要,社会各领域对高分辨率遥感影像和基础地理信息的需求日益迫切,且对这些产品质量的要求也在逐步提高。虽然卫星、飞机和雷达遥感数据各有其应用场景,但在某些情况下,它们可能无法完全满足影像数据采集和处理的需求。与传统的航空航天遥感技术相比,无人机(UAV)低空遥感技术作为一种新型的低空遥感技术,具有灵活性高、操作简便、分辨率高、投资少等诸多优点[1]。大多数无人机主要在低空作业,单幅影像覆盖范围较小,因此影像拼接是利用无人机多航带影像数据的一项重要技术。一般来说,影像拼接包括配准、重投影、缝合和融合等多个处理步骤[2]。根据配准算法,影像拼接可分为基于空间域的算法和基于频率域的算法。同时,也有一些采用深度学习算法进行端到端的影像拼接。此外,许多研究人员在通用影像拼接的基础上,提出了适用于无人机影像拼接的新方法。接下来,我们将对这些算法逐一进行介绍。
check for updates
检查更新
Citation: Li, R.; Gao, P.; Cai, X.; Chen, X.; Wei, J.; Cheng, Y.; Zhao, H. A Real-Time Incremental Video Mosaic Framework for UAV Remote Sensing. doi.org/10.3390/rs15082127
引用:李(Li),R.;高(Gao),P.;蔡(Cai),X.;陈(Chen),X.;魏(Wei),J.;程(Cheng),Y.;赵(Zhao),H. 一种用于无人机遥感的实时增量视频拼接框架。doi.org/10.3390/rs15082127
Academic Editor: Jon Atli Benediktsson
学术编辑:乔恩·阿特利·贝内迪克松(Jon Atli Benediktsson)
Received: 13 March 2023
接收日期:2023年3月13日
Revised: 10 April 2023
修订日期:2023年4月10日
Accepted: 11 April 2023
接受日期:2023年4月11日
Published: 18 April 2023
发布时间:2023年4月18日
Copyright: \(\circledcirc {2023}\) by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article 4.0/).
版权信息:\(\circledcirc {2023}\) 作者保留版权。许可方:瑞士巴塞尔的MDPI出版社。本文是一篇开放获取文章(4.0/)。
1.1. Spatial Domain Image Mosaicking Algorithms
1.1. 空间域图像拼接算法
Image mosaicking algorithms based on spatial domains use pixel-to-pixel related information for registration. Most of the existing algorithms fall into this category. Spatial domain-based image mosaicking can be either area-based or feature-based. Area-based algorithms rely on computation between "windows" of pixel values in the two images, which need to be mosaicked [3]. For example, normalized cross correlation can be used as a metric to calculate the pixel distribution similarity of each window in the images [4]. Mutual Information can be used to calculate the shared information between two images to measure the similarity. However, due to the fact that area-based algorithms match images by comparing patches, these techniques have the disadvantage of being computationally slow, and require high areas of overlap between input images.
基于空间域的图像拼接算法利用像素间的相关信息进行配准。现有的大多数算法都属于这一类别。基于空间域的图像拼接可以是基于区域的,也可以是基于特征的。基于区域的算法依赖于对两幅需要拼接的图像中像素值“窗口”之间的计算[3]。例如,归一化互相关可以用作一种度量,来计算图像中每个窗口的像素分布相似度[4]。互信息可以用于计算两幅图像之间的共享信息,以衡量它们的相似度。然而,由于基于区域的算法是通过比较图像块来匹配图像的,这些技术存在计算速度慢的缺点,并且要求输入图像之间有较大的重叠区域。
Different from area-based algorithms, feature-based algorithms do not require large areas of overlap between two images. Instead, they use pixel-level features to match images and calculate the geometric transformation between a pair of images. These algorithms rely on feature extraction algorithms, which can detect significant features in an image, including edges, corners, domain histograms, etc., and assign a descriptor to each feature for comparison with the features of another image. Depending on the types of features extracted, feature-based algorithms can be classified into low-level feature-based algorithms and contour-based algorithms. Low-level feature-based algorithms usually determine features and descriptors by calculating the distribution and gradients of the surrounding domain.
与基于区域的算法不同,基于特征的算法不需要两幅图像之间有大面积的重叠。相反,它们使用像素级特征来匹配图像,并计算一对图像之间的几何变换。这些算法依赖于特征提取算法,该算法可以检测图像中的显著特征,包括边缘、角点、区域直方图等,并为每个特征分配一个描述符,以便与另一幅图像的特征进行比较。根据提取的特征类型,基于特征的算法可分为基于低级特征的算法和基于轮廓的算法。基于低级特征的算法通常通过计算周围区域的分布和梯度来确定特征和描述符。
Scale invariant feature transform (SIFT) [5] is a feature detector and descriptor that is invariant to image scaling and rotation in most cases, and also has a tolerance to illumination and 3D camera viewpoint change, but this algorithm needs a large amount of computation. Based on SIFT, Speeded Up Robust Features (SURF) [6] is proposed. Similar to SIFT, this algorithm is also based on scale space. However, SURF uses the Hessian matrix of integrated images to estimate the local maximum values of different scale spaces. The oriented FAST and rotated BRIEF (ORB) [7] uses the feature from accelerated segment test (FAST) algorithm to detect feature points of the image, and then describes the detected feature points with the binary robust independent elementary feature (BRIEF) algorithm.
尺度不变特征变换(Scale invariant feature transform,SIFT)[5]是一种特征检测器和描述符,在大多数情况下对图像缩放和旋转具有不变性,并且对光照和三维相机视角变化也有一定的容忍度,但该算法需要大量的计算。基于SIFT,提出了加速稳健特征(Speeded Up Robust Features,SURF)[6]。与SIFT类似,该算法同样基于尺度空间。然而,SURF使用积分图像的黑塞矩阵(Hessian matrix)来估计不同尺度空间的局部最大值。定向FAST和旋转BRIEF(Oriented FAST and rotated BRIEF,ORB)[7]使用加速分割测试特征(Feature from accelerated segment test,FAST)算法来检测图像的特征点,然后使用二进制稳健独立基本特征(Binary robust independent elementary feature,BRIEF)算法来描述检测到的特征点。
Since low-level features are not intuitive for human perception, contour features can be another choice, and they are high-level features because they are more natural to human perception. These high-level features focus mainly on extracting shape or texture in the image. Regions with different structures are described as different descriptors and matched in both images. This type of algorithm is suitable for complex parameters and motion models, as it looks for advanced features under extreme image changes [8-10].
由于低级特征对于人类感知而言并不直观,因此轮廓特征可以作为另一种选择,并且它们属于高级特征,因为它们更符合人类的感知习惯。这些高级特征主要侧重于提取图像中的形状或纹理。具有不同结构的区域被描述为不同的描述符,并在两幅图像中进行匹配。这种类型的算法适用于复杂的参数和运动模型,因为它能够在图像发生极端变化的情况下寻找高级特征[8 - 10]。
1.2. Frequency Domain Image Mosaicking Algorithms
1.2. 频域图像拼接算法
Unlike spatial domain-based image mosaicking algorithms, frequency domain image mosaicking algorithms require computation in the frequency domain to find the optimal transformation parameters between a pair of images. These algorithms adopt phase correlation properties to register images, usually using Fourier transform and inverse Fourier transform to transform between spatial and frequency domains and register images in the frequency domain. However, the frequency domain image mosaicking algorithms are too sensitive to noise, and can only get a rough result. To obtain accurate results, the overlap between the images needs to be high.
与基于空间域的图像拼接算法不同,频域图像拼接算法需要在频域中进行计算,以找到一对图像之间的最优变换参数。这些算法利用相位相关特性来配准图像,通常使用傅里叶变换(Fourier transform)和逆傅里叶变换(inverse Fourier transform)在空间域和频域之间进行转换,并在频域中进行图像配准。然而,频域图像拼接算法对噪声过于敏感,只能得到一个粗略的结果。为了获得准确的结果,图像之间的重叠部分需要足够大。
1.3. Deep Learning-Based Image Mosaicking Algorithms
1.3. 基于深度学习的图像拼接算法
With the rapid development of deep learning, many scholars have tried to use deep learning algorithms for image mosaicking tasks. There are two main development directions in this category. One is to learn features and descriptors of images to obtain features with stronger generalization capability than traditional handcrafted features, and the other attempts to use an end-to-end approach for image stitching.
随着深度学习的快速发展,许多学者尝试将深度学习算法应用于图像拼接任务。该领域主要有两个发展方向。一是学习图像的特征和描述符,以获得比传统手工特征具有更强泛化能力的特征;二是尝试使用端到端的方法进行图像拼接。
SuperPoint [11] is a self-supervised framework for training interest point detectors and descriptors suitable for a large number of multiple-view geometry problems in computer vision, but it uses self-generated data to train for corner detection; its generalization for real scenarios needs to be verified. Learned invariant feature transform (LIFT) [12], a recently introduced convolutional replacement for SIFT, stays close to the traditional patch-based detect-then-describe recipe; the limited applicability of this algorithm is due to its dependence on image patches as input rather than entire images, which prevents the algorithm from processing the entirety of an image for mosaicking. L2-Net [13] proposes to learn high-performance descriptors in Euclidean space via the convolutional neural network (CNN); Unsuperpoint [14] utilizes a siamese network and a novel loss function that enables interest point scores and positions to be learned automatically using a self-supervised approach. Compared to handcrafted algorithms such as SIFT and SURF, the feature points and descriptors extracted by a neural network can express deeper features of images and have a stronger generalization ability. However, the correct key points that can be identified by these algorithms are limited. Under the condition that the number of key points is not limited, the handcrafted algorithms can obtain more accurate matching through quantitative advantage.
SuperPoint [11]是一个用于训练兴趣点检测器和描述符的自监督框架,适用于计算机视觉中大量的多视图几何问题,但它使用自生成的数据进行角点检测训练;其在真实场景中的泛化能力有待验证。学习不变特征变换(Learned invariant feature transform,LIFT)[12]是最近提出的一种用于替代尺度不变特征变换(SIFT)的卷积方法,它与传统的基于图像块的先检测后描述的方法相近;该算法适用性有限,是因为它依赖图像块作为输入,而非整幅图像,这使得该算法无法处理整幅图像以进行拼接。L2网络(L2-Net)[13]提出通过卷积神经网络(CNN)在欧几里得空间中学习高性能描述符;无监督点(Unsuperpoint)[14]利用孪生网络和一种新颖的损失函数,通过自监督方法实现兴趣点分数和位置的自动学习。与尺度不变特征变换(SIFT)和加速稳健特征(SURF)等手工算法相比,神经网络提取的特征点和描述符能够表达图像更深层次的特征,且具有更强的泛化能力。然而,这些算法能够识别的正确关键点数量有限。在关键点数量不受限制的情况下,手工算法可以通过数量优势实现更精确的匹配。
Some scholars consider using deep neural networks (DNN) to learn the transformation relationship between image pairs. Geometric Matching Networks (GMN) [15] and Deep Image Homography Estimation (DIHE) [16] use a similar self-supervision strategy to create training data for estimating global transformations. Some algorithms use an individual homography estimation network for coarse alignment and optimize the pre-aligned images by reconstruction networks to achieve better stitching results in large-baseline scenes [17,18]. However, the current deep-learning-based algorithms can only input two images and output a panorama; the deep learning framework of multi-strip sequences remains to be studied.
一些学者考虑使用深度神经网络(DNN)来学习图像对之间的变换关系。几何匹配网络(GMN)[15]和深度图像单应性估计(DIHE)[16]采用了类似的自监督策略来创建用于估计全局变换的训练数据。一些算法使用单独的单应性估计网络进行粗对齐,并通过重建网络对预对齐的图像进行优化,以在大基线场景中获得更好的拼接效果[17,18]。然而,目前基于深度学习的算法只能输入两幅图像并输出一幅全景图;多条带序列的深度学习框架仍有待研究。
1.4.UAV Image Mosaicking Algorithms
1.4 无人机图像拼接算法
With the advancements in UAV and sensor technology, UAVs are being increasingly used for photogrammetric data acquisition. Their low flight altitude makes them ideal for capturing high-resolution images of small to medium-sized areas. However, when it comes to large areas, image mosaicking technology is needed to stitch together multiple images into a single panorama. Compared with other requirements, the UAV often obtains multi-strip and large-scale image sequences. In this case, it is difficult to obtain panoramas by directly stitching images. In general, image mosaicking for UAV missions focuses more on improving the performance and efficiency of multi-strip image sequences.
随着无人机和传感器技术的进步,无人机正越来越多地用于摄影测量数据采集。其较低的飞行高度使其非常适合捕捉中小面积区域的高分辨率图像。然而,在处理大面积区域时,需要使用图像拼接技术将多幅图像拼接成一幅全景图。与其他需求相比,无人机通常会获取多条带、大规模的图像序列。在这种情况下,直接拼接图像很难获得全景图。一般来说,无人机任务中的图像拼接更侧重于提高多条带图像序列的性能和效率。
The high resolution and large number of images acquired by UAV leads to huge time consumption of image mosaicking. Yahyanejad [19] used multi-source data mixing to try to accelerate the stitching process. They determined the rough position of each image with the help of the GPS information or inertial measurement unit data carried by the UAV, and carried out feature matching in the rough position to reduce the retrieval space of image features. This algorithm can obtain panoramic images without obvious distortion of the view angle, and retain certain geo-reference information from the GPS. However, this algorithm did not solve the cumulative error in a large sequence of image mosaicking. Danilo Avola [20] proposed an algorithm to obtain panoramic images increasingly at low altitudes. In order to accelerate matching, they adopted A-KAZE features instead of SIFT and ORB features for feature matching. They also used ROI to reduce the amount of calculation for each new frame and adopted rigid transformation to replace homography. However, the rigid transformation did not perform well with complex terrain. Liu [21] proposed an integrated GPS/INS/Vision system. They assumed a negligible change in ground height between two adjacent frames during the UAV aerial mission. After obtaining the image, GPS/IMU was used for geometric correction, and then the transformation of image pixels was interpreted as a linear function transformation, and a parameter was added for places with large terrain fluctuations. Compared with other algorithms, their operation speed was faster, but as their algorithm focuses on raising the accuracy of the corresponding points, the image stitching errors were obvious even though the accuracy of corresponding points was high.
无人机获取的高分辨率和大量图像导致图像拼接耗时巨大。亚赫亚内贾德(Yahyanejad)[19]采用多源数据融合的方法试图加速拼接过程。他们借助无人机携带的GPS信息或惯性测量单元数据确定每幅图像的大致位置,并在大致位置进行特征匹配,以缩小图像特征的检索空间。该算法可以获得视角无明显畸变的全景图像,并保留GPS中的一定地理参考信息。然而,该算法未能解决大序列图像拼接中的累积误差问题。达尼洛·阿沃拉(Danilo Avola)[20]提出了一种在低空逐步获取全景图像的算法。为了加速匹配,他们采用A-KAZE特征而非SIFT和ORB特征进行特征匹配。他们还使用感兴趣区域(ROI)减少每一帧新图像的计算量,并采用刚性变换代替单应性变换。然而,刚性变换在复杂地形下效果不佳。刘(Liu)[21]提出了一种集成GPS/INS/视觉系统。他们假设无人机在航拍任务中相邻两帧之间的地面高度变化可忽略不计。获取图像后,利用GPS/IMU进行几何校正,然后将图像像素的变换解释为线性函数变换,并为地形起伏较大的地方添加一个参数。与其他算法相比,他们的运算速度更快,但由于其算法侧重于提高对应点的精度,即使对应点精度较高,图像拼接误差仍很明显。
The other group focuses on how to reduce the accumulated errors in UAV image mosaicking. Zhang [1] proposed an optimization algorithm. They introduced the Levenberg-Marquardt (LM) algorithm to globally optimize the position of an image in the panorama and generate a panorama with high precision, but their global optimization does not allow incremental input. Zhao [22] presented an online sequential orthophoto mosaicking solution for large baseline high-resolution aerial images with high efficiency and novel precision. An appearance- and spatial-correlation-constrained fast low-overlap neighbor candidate query and matching strategy were used for efficient and robust global matching, but this algorithm requires a very high altitude of UAV. Ren [23] proposed a simplified algorithm for UAV stitching. Based on image contrast, they determined the optimal band for extracting SIFT, and then extracted SIFT on a single band image to improve the speed. A simplified projection model was proposed to avoid huge computation caused by 3D reconstruction and irregular resampling. Jyun-Gu [24] proposed a novel speed estimation algorithm capable of measuring the distance of pixel movement between consecutive frames. However, this algorithm was limited in that the flight path must be a straight line, and that moving objects in the scene would affect the algorithm's estimation of the pixel motion speed, resulting in distortion of the panorama. Chen [25] proposed a nonrigid matching algorithm based on motion field interpolation; the homography transformation relationship was improved by vector field consensus (VFC), which had better robustness to image mosaicking, but required a lot of computation. Map2DFusion [26] proposed a real-time approach to stitch large-scale aerial images incrementally. It used a monocular SLAM system to estimate camera position and attitude, but this algorithm relies on ORBSLAM or other SLAM systems. Zhang [27] proposed a novel image-only real-time UAV image mosaic framework for long-distance multistrip flights, and it does not require any auxiliary information such as GPS or GCPs; their optimize algorithm is worth learning, and this algorithm mitigates the cumulative error by using a least-squares-based pose optimization, but it is too sensitive to noise.
另一组则专注于如何减少无人机图像拼接中的累积误差。张[1]提出了一种优化算法。他们引入了列文伯格 - 马夸尔特(Levenberg - Marquardt,LM)算法来全局优化图像在全景图中的位置,并生成高精度的全景图,但他们的全局优化不允许增量输入。赵[22]针对大基线高分辨率航空图像提出了一种高效且具有新精度的在线顺序正射影像拼接解决方案。采用了基于外观和空间相关性约束的快速低重叠邻域候选查询与匹配策略进行高效且稳健的全局匹配,但该算法要求无人机飞行高度非常高。任[23]提出了一种简化的无人机拼接算法。他们基于图像对比度确定提取尺度不变特征变换(SIFT)的最佳波段,然后在单波段图像上提取SIFT以提高速度。提出了一种简化的投影模型,以避免三维重建和不规则重采样带来的大量计算。朱俊谷(Jyun - Gu)[24]提出了一种新颖的速度估计算法,能够测量连续帧之间像素移动的距离。然而,该算法的局限性在于飞行路径必须是直线,并且场景中的移动物体将影响算法对像素运动速度的估计,从而导致全景图失真。陈[25]提出了一种基于运动场插值的非刚性匹配算法;通过向量场一致性(VFC)改进了单应性变换关系,该算法对图像拼接具有更好的鲁棒性,但需要大量的计算。Map2DFusion[26]提出了一种实时增量拼接大规模航空图像的方法。它使用单目同时定位与地图构建(SLAM)系统来估计相机的位置和姿态,但该算法依赖于ORB - SLAM或其他SLAM系统。张[27]为长距离多航带飞行提出了一种新颖的仅基于图像的实时无人机图像拼接框架,并且不需要任何诸如全球定位系统(GPS)或地面控制点(GCPs)之类的辅助信息;他们的优化算法值得学习,该算法通过基于最小二乘法的位姿优化来减轻累积误差,但对噪声过于敏感。
Although considerable progress has been achieved in this area, a fast, robust, and efficient aerial image mosaic system in an unknown environment is still worthwhile to study, especially in long-distance multi-strip flights. There are two main problems in the current UAV image mosaic algorithm. First, most of the UAV image mosaicking algorithms are not real-time. They require all the image sequences before they can perform global optimization. The quality of the image obtained is relatively high. However, it cannot perform fast, real-time, and incremental mosaicking. It is difficult to achieve the expected effect in some tasks that need to quickly obtain the panorama of the region of interest, such as the task of simultaneous mapping in flight. In the algorithms that are in real time, most of them focus on fusing sensor data, reducing the matching space, and replacing the features to accelerate the algorithm. The advantage is that they can be stitched incrementally, but they cannot solve the error accumulation problem caused by the incremental stitching of long sequences of UAV images.
尽管在这一领域已经取得了相当大的进展,但在未知环境中开发一种快速、稳健且高效的航空影像拼接系统仍然值得研究,特别是在长距离多航带飞行中。当前的无人机影像拼接算法主要存在两个问题。首先,大多数无人机影像拼接算法并非实时算法。它们需要获取所有影像序列后才能进行全局优化。虽然这样得到的影像质量相对较高,但无法进行快速、实时和增量式拼接。在一些需要快速获取感兴趣区域全景图的任务中,如飞行中同步建图任务,很难达到预期效果。在实时算法中,大多数算法侧重于融合传感器数据、减少匹配空间以及替换特征以加速算法。其优点是可以进行增量式拼接,但无法解决无人机长序列影像增量式拼接所导致的误差累积问题。
In this paper, a real-time UAV image mosaic framework is proposed, aimed at tasks such as rapid post-disaster reconstruction and search and rescue operations, which allows the UAV to synchronously return images and incrementally assemble them during the execution of aerial photography tasks. Core technologies used to construct our framework are:
本文提出了一种实时无人机图像拼接框架,该框架针对灾后快速重建和搜救行动等任务,允许无人机在执行航拍任务期间同步回传图像并逐步拼接。构建我们框架所使用的核心技术如下:
-
A fuzzy positioning-based keyframe selection strategy, which greatly improves the efficiency of the algorithm without compromising the stitching effect.
-
一种基于模糊定位的关键帧选择策略,该策略在不影响拼接效果的前提下,极大地提高了算法效率。
-
A new local optimization strategy to minimize the weighted reprojection error, which minimizes the cumulative error when stitching sequences from multi-strip, which has a large number of images.
-
一种新的局部优化策略,用于最小化加权重投影误差,该策略可在拼接大量多航带序列图像时将累积误差降至最低。
-
A partition-weighted pyramid fusion algorithm, which is used to give the best visual effect to the generated panoramas.
-
一种分区加权金字塔融合算法,用于为生成的全景图提供最佳视觉效果。
-
Although our algorithm is image-only mosaicking if the GPS corresponding to the image can be obtained, our algorithm also supports generating a panorama with geographic coordinates.
-
虽然我们的算法仅进行图像拼接,但如果能获取图像对应的全球定位系统(GPS)信息,我们的算法也支持生成带有地理坐标的全景图。
2. Materials and Methods
2. 材料与方法
Our framework consists of two simultaneous branches: the data synchronization branch and the image mosaicking branch. The data synchronization branch is mainly responsible for real-time video stream acquisition and data synchronization with the image mosaicking branch during the flight of the UAV, while the image mosaicking branch splits the acquired video stream into frames, and stitches the acquired frames. Our main innovative work focuses on the calculation branch.
我们的框架由两个并行分支组成:数据同步分支和图像拼接分支。数据同步分支主要负责在无人机飞行过程中实时采集视频流,并与图像拼接分支进行数据同步,而图像拼接分支则将采集到的视频流分割成帧,并对采集到的帧进行拼接。我们的主要创新工作集中在计算分支上。
The flow of our algorithm mainly includes four parts:
我们的算法流程主要包括四个部分:
-
Initialization of the mosaicking
-
拼接初始化
-
Fuzzy location of new frame and keyframe selection;
-
新帧的模糊定位和关键帧选择;
-
Local pose optimization of keyframe
-
关键帧的局部位姿优化
-
Expanding and generating panoramas.
-
扩展并生成全景图。
The overall frame framework is shown in Figure 1.
整体框架如图1所示。
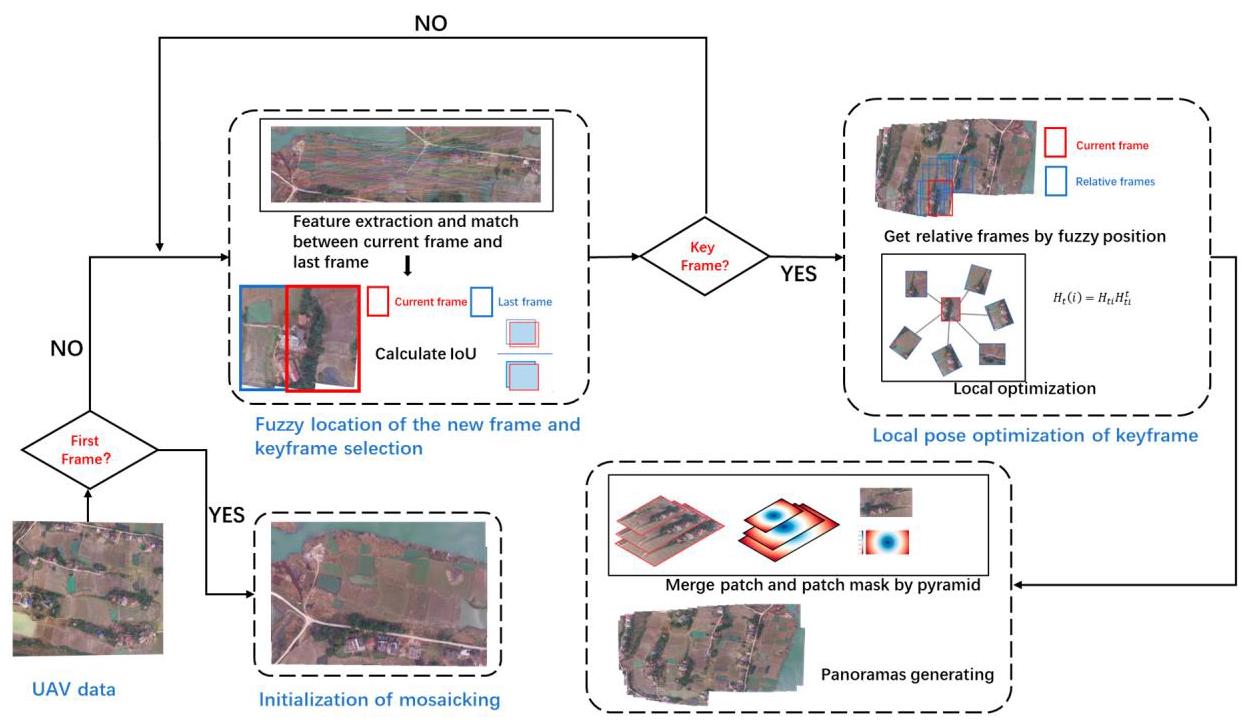
Figure 1. The overall framework. The framework mainly includes four tasks: (1) initialization of mosaicking, (2) fuzzy location of the new frame and keyframe selection, (3) local pose optimization of keyframe, (4) expanding and generating panoramas.
图1. 整体框架。该框架主要包括四项任务:(1)拼接初始化;(2)新帧的模糊定位与关键帧选择;(3)关键帧的局部位姿优化;(4)扩展并生成全景图。
2.1. Initialization of Mosaicking
2.1 拼接初始化
After the UAV starts flying, the data synchronization branch picks up video streaming data. Generally speaking, the camera's optical axis can be kept perpendicular to the ground with the help of the cradle head during flight. The aerial survey task of the UAV starts from the flight to the specified height. When the first image is captured by the UAV, the system first carries out an automatic initialization process. We set the first frame as the base plane of other images, and subsequent images are mapped to this plane.
无人机开始飞行后,数据同步分支会采集视频流数据。一般来说,飞行过程中借助云台可使相机光轴保持与地面垂直。无人机的航测任务从飞行至指定高度开始。当无人机捕获到第一幅图像时,系统首先会进行自动初始化过程。我们将第一帧设为其他图像的基准平面,后续图像将映射到该平面上。
We calculate and record the flight trajectory and the fuzzy position of keyframes, which provide optimization information for the subsequent image mosaic. At the same time, we use SIFT to extract features in the frame. The experimental results show that SIFT extraction algorithms are the most balanced choice in UAV image mosaicking. In fact, our algorithm supports most handcrafted features. In order to ensure generalization, we can also replace SIFT with other deep-learning feature extraction algorithms.
我们计算并记录飞行轨迹和关键帧的模糊位置,为后续的图像拼接提供优化信息。同时,我们使用尺度不变特征变换(SIFT)算法在帧中提取特征。实验结果表明,在无人机图像拼接中,SIFT 提取算法是最为均衡的选择。实际上,我们的算法支持大多数手工特征。为了确保泛化性,我们也可以用其他深度学习特征提取算法替代 SIFT。
2.2. Fuzzy Location of the New Frame and Keyframe Selection
2.2. 新帧的模糊定位与关键帧选择
In the stitching process, not all the frames are necessary. If the stitching is dense, it will lead to a rapid increase in information redundancy and computational burden, so it is important to select keyframes.
在拼接过程中,并非所有帧都是必需的。如果拼接过于密集,会导致信息冗余和计算负担迅速增加,因此选择关键帧非常重要。
The newly added image is called the current frame \({K}_{t}\) , and we will calculate its position relative to the previous keyframe \({K}_{t - 1}\) by matching each SIFT feature descriptor \({D}_{t}\left( {{x}_{i},{y}_{i}}\right)\) of \({K}_{t}\) with the descriptor \({D}_{t - 1}\left( {x, y}\right)\) of \({K}_{t - 1}.{D}_{j}\left( {{x}_{i},{y}_{i}}\right)\) represents the descriptor of SIFT keypoints at coordinate \(\left( {{x}_{i},{y}_{i}}\right)\) in frame \({K}_{j}\) , which is described as a 128-dimensional vector [5]:
新添加的图像称为当前帧 \({K}_{t}\),我们将通过将 \({K}_{t}\) 的每个尺度不变特征变换(SIFT,Scale-Invariant Feature Transform)特征描述符 \({D}_{t}\left( {{x}_{i},{y}_{i}}\right)\) 与 \({K}_{t - 1}\) 的描述符 \({D}_{t - 1}\left( {x, y}\right)\) 进行匹配,来计算其相对于前一个关键帧 \({K}_{t - 1}\) 的位置。\({K}_{t - 1}.{D}_{j}\left( {{x}_{i},{y}_{i}}\right)\) 表示帧 \({K}_{j}\) 中坐标 \(\left( {{x}_{i},{y}_{i}}\right)\) 处的 SIFT 关键点的描述符,它被描述为一个 128 维向量 [5]:
The feature descriptor of SIFT extraction algorithms is composed of the local gradient information calculated in the region around the keypoint. This gradient information is obtained by statistics of gradient direction histograms in a specific way, then the histograms are concatenated into a 128-dimensional vector as the descriptor of the keypoint. The SIFT feature descriptor is characterized by good invariance to image rotation and scaling. We find two neighboring matches, the nearest neighbor \(\left( {{D}_{t}\left( {{x}_{i},{y}_{i}}\right) ,{D}_{t - 1}\left( {{x}_{k},{y}_{k}}\right) }\right)\) and the next nearest neighbor \(\left( {{D}_{t}\left( {{x}_{i},{y}_{i}}\right) ,{D}_{t - 1}\left( {{x}_{j},{y}_{j}}\right) }\right)\) . In order to maintain robustness, false matches should be eliminated. It is generally assumed that if two pairs of neighboring matches have similar internal distances, they have a high probability of being false matches, and a threshold \(P\) is used to filter which matches are correct.
SIFT提取算法的特征描述符由关键点周围区域计算得到的局部梯度信息组成。该梯度信息是通过以特定方式统计梯度方向直方图获得的,然后将这些直方图连接成一个128维向量,作为关键点的描述符。SIFT特征描述符具有对图像旋转和缩放良好的不变性。我们找到两个相邻匹配,最近邻\(\left( {{D}_{t}\left( {{x}_{i},{y}_{i}}\right) ,{D}_{t - 1}\left( {{x}_{k},{y}_{k}}\right) }\right)\)和次近邻\(\left( {{D}_{t}\left( {{x}_{i},{y}_{i}}\right) ,{D}_{t - 1}\left( {{x}_{j},{y}_{j}}\right) }\right)\)。为了保持鲁棒性,应消除错误匹配。一般认为,如果两对相邻匹配的内部距离相似,它们很可能是错误匹配,并使用一个阈值\(P\)来过滤哪些匹配是正确的。
After matching the feature points of two images, we need to calculate the relative position between the two images with the matched feature points. While the scenes are almost planar, the homography can precisely describe the projective transformation that relates to two images of the same scene [28]. In this paper, the homography model is used to describe the inter-image projection. A homography that relates two planes is usually represented as an invertible \(3 \times 3\) matrix [29].
在匹配两幅图像的特征点之后,我们需要利用匹配的特征点来计算这两幅图像之间的相对位置。当场景几乎为平面时,单应性矩阵可以精确描述与同一场景的两幅图像相关的投影变换[28]。在本文中,使用单应性模型来描述图像间的投影。关联两个平面的单应性矩阵通常表示为一个可逆的\(3 \times 3\)矩阵[29]。
It is constrained by 8 independent parameters, requiring at least 4 corresponding points for determination. We use random sample consensus (RANSAC) to estimate the homography \({H}_{t}^{t - 1}\) from the current frame \({K}_{t}\) to the previous frame \({K}_{t - 1}\) . The homography transforms the pixel coordinates \(\left\lbrack {x, y,1}\right\rbrack\) in the current frame to that in the previous one.
它受8个独立参数的约束,确定该矩阵至少需要4个对应点。我们使用随机抽样一致性算法(RANSAC)来估计从当前帧\({K}_{t}\)到前一帧\({K}_{t - 1}\)的单应性矩阵\({H}_{t}^{t - 1}\)。单应性矩阵将当前帧中的像素坐标\(\left\lbrack {x, y,1}\right\rbrack\)转换为前一帧中的像素坐标。
The homography transforms the pixel coordinates in the previous frame \({K}_{t - 1}\) to that in the base plane \({K}_{\text{base }}\) , which can be described as the following formula:
单应性变换将前一帧 \({K}_{t - 1}\) 中的像素坐标转换到基准平面 \({K}_{\text{base }}\) 中的像素坐标,这可以用以下公式描述:
where \(\left( {{x}_{t},{y}_{t}}\right)\) denotes the coordinates of the image point in the current frame, \(\left( {{x}_{t - 1},{y}_{t - 1}}\right)\) denotes the coordinates of the corresponding point in the previous frame, and \({\mathrm{{eH}}}_{t - 1}\) denotes the homography from the previous frame \({K}_{t - 1}\) to the base plane. The projection from the current frame to the base plane can be calculated using the homography \({H}_{t}^{\prime } = {H}_{t - 1}{H}_{t}^{t - 1}\) . Due to accumulated error, the position calculated by this homography matrix is not very accurate. We call it a fuzzy position. The real position of the current frame should be close to this fuzzy position. As shown in Figure 2, the minimum bounding rectangle of the position contour is used to describe the fuzzy position, and it is assumed that the real position of the frame should be located in this rectangle.
其中 \(\left( {{x}_{t},{y}_{t}}\right)\) 表示当前帧中图像点的坐标,\(\left( {{x}_{t - 1},{y}_{t - 1}}\right)\) 表示前一帧中对应点的坐标,\({\mathrm{{eH}}}_{t - 1}\) 表示从前一帧 \({K}_{t - 1}\) 到基准平面的单应性矩阵。可以使用单应性矩阵 \({H}_{t}^{\prime } = {H}_{t - 1}{H}_{t}^{t - 1}\) 计算从当前帧到基准平面的投影。由于累积误差,通过该单应性矩阵计算得到的位置不是非常准确。我们将其称为模糊位置。当前帧的真实位置应该接近这个模糊位置。如图 2 所示,使用位置轮廓的最小外接矩形来描述模糊位置,并假设帧的真实位置应该位于该矩形内。
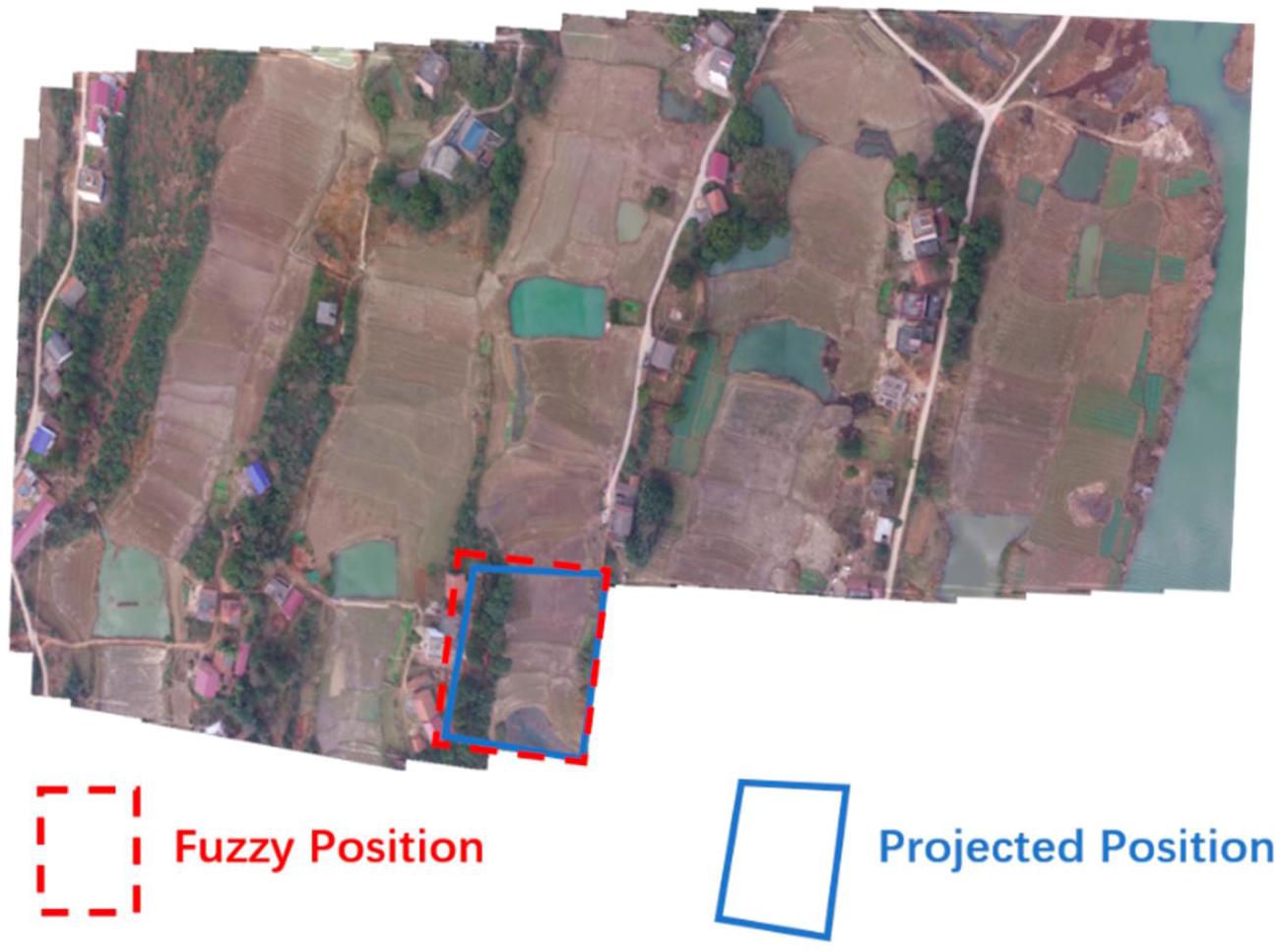
Figure 2. Fuzzy location. Red dashed box represents fuzzy position and blue box represents projected position. Fuzzy position is the minimum bounding rectangle of projected position.
图2. 模糊位置。红色虚线框表示模糊位置,蓝色框表示投影位置。模糊位置是投影位置的最小边界矩形。
To compromise between speed and mosaic quality, a specified keyframe selection strategy is proposed in the framework. If the keyframes are sparse, the overlap between frames is too small, resulting in stitching failure. If the keyframes are dense, there will be a lot of redundant information. Such information cannot improve the results much, but does cost a lot of computing resources. In this paper, the keyframe selection strategy is based on the intersection over union (IoU) between the fuzzy position of the current frame and the position of the previous frame. We define the IoU between the current frame \({K}_{t}\) and the previous keyframe \({K}_{t - 1}\) as shown in the following formula [30]:
为了在速度和拼接质量之间取得平衡,本框架提出了一种特定的关键帧选择策略。如果关键帧稀疏,帧与帧之间的重叠区域过小,会导致拼接失败。如果关键帧密集,则会存在大量冗余信息。这些信息对拼接结果的提升作用不大,但会消耗大量计算资源。本文中,关键帧选择策略基于当前帧的模糊位置与前一帧位置的交并比(IoU,Intersection over Union)。我们将当前帧\({K}_{t}\)与前一关键帧\({K}_{t - 1}\)之间的交并比定义如下式[30]所示:
As shown in Figure 3, Area(K)denotes the area of frame \(K\) in the base plane. \(\cap\) denotes the intersection between the two images, and \(\cup\) denotes the union of the two images. The IoU value ranges from 0 to 1 , with larger values indicating greater overlap between the two images and hence greater similarity, and smaller values indicating less overlap and hence less similarity.
如图3所示,Area(K)表示基础平面中帧\(K\)的面积。\(\cap\)表示两个图像的交集,\(\cup\)表示两个图像的并集。交并比(IoU)值的范围是0到1,值越大表示两个图像的重叠部分越大,因此相似度越高;值越小表示重叠部分越小,因此相似度越低。
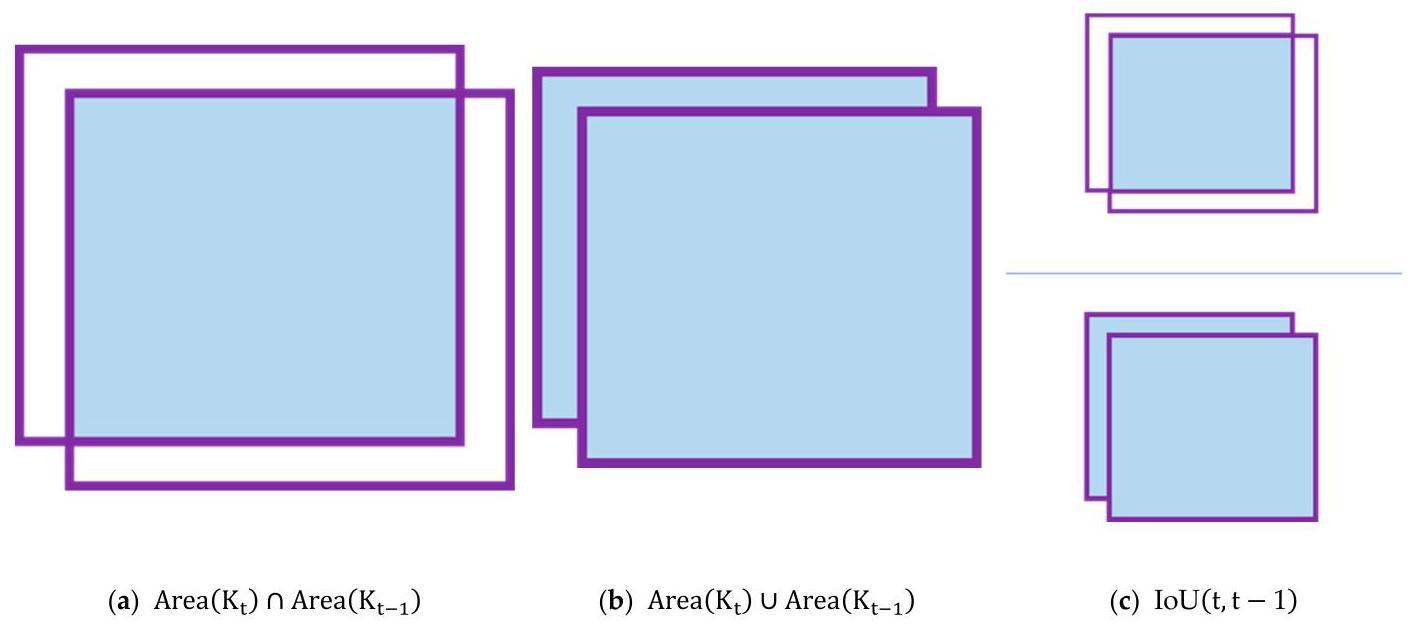
Figure 3. IoU of two areas. IoU is calculated by dividing the overlap between two areas by the union of these.
图3. 两个区域的交并比(IoU)。交并比(IoU)的计算方法是用两个区域的重叠部分除以它们的并集。
Two thresholds \({P}_{\min }\) and \({P}_{\max }\) are defined as low and high limits for keyframe determination. Compared with these thresholds, if \(\operatorname{IoU}\left( {t, t - 1}\right) > {P}_{\left( \max \right) }\) , the overlapping area of two frames is too large, and we consider that the current frame does not introduce enough information; if \(\operatorname{IoU}\left( {t, t - 1}\right) < {P}_{\min }\) , we consider that the overlapping area of two frames is too small, meaning it is easy to introduce noise and get the wrong match and transformation; if \({P}_{\text{min }} \leq {IoU} \leq {P}_{\text{max }}\) , the current frame is considered a keyframe.
定义了两个阈值 \({P}_{\min }\) 和 \({P}_{\max }\) 作为关键帧判定的下限和上限。与这些阈值相比,如果 \(\operatorname{IoU}\left( {t, t - 1}\right) > {P}_{\left( \max \right) }\),则两帧的重叠区域过大,我们认为当前帧引入的信息不足;如果 \(\operatorname{IoU}\left( {t, t - 1}\right) < {P}_{\min }\),我们认为两帧的重叠区域过小,这意味着容易引入噪声并得到错误的匹配和变换;如果 \({P}_{\text{min }} \leq {IoU} \leq {P}_{\text{max }}\),则当前帧被视为关键帧。
2.3. Local Pose Optimization of Keyframe
2.3. 关键帧的局部位姿优化
For incremental image mosaicking, the naive idea of calculating the position of the current frame \({K}_{t}\) is to calculate the homography matrix \({H}_{t}^{t - 1}\) , the homography \({H}_{t - 1}\) , and then project \({K}_{t}\) to the base plane. We can derive this relationship from Formulas (4) and (5)
对于增量式图像拼接,计算当前帧 \({K}_{t}\) 位置的简单想法是计算单应性矩阵 \({H}_{t}^{t - 1}\)、单应性 \({H}_{t - 1}\),然后将 \({K}_{t}\) 投影到基准平面上。我们可以从公式 (4) 和 (5) 推导出这种关系
This formula represents the candidate homography when the current frame matches \({K}_{ti}\) . We need to choose the best of the \(t - 1\) candidate homographies that we calculated. Although this approach is intuitive and simple, it can cause very large cumulative errors. Li [31] analyzed the cumulative error of the sequence images. They subdivided the cumulative error of matrix calculation into addition errors and multiplication errors. It was found that the error propagation in matrix operation is very fast. This error leads to worse mosaicking results in later stages.
该公式表示当前帧与 \({K}_{ti}\) 匹配时的候选单应性。我们需要从计算得到的 \(t - 1\) 个候选单应性中选择最佳的一个。虽然这种方法直观且简单,但会导致非常大的累积误差。李 [31] 分析了序列图像的累积误差。他们将矩阵计算的累积误差细分为加法误差和乘法误差。研究发现,矩阵运算中的误差传播非常快。这种误差会导致后期的拼接结果变差。
We propose a new local optimization strategy to mitigate cumulative errors. When the current frame is determined as keyframe \({K}_{t}\) , we not only calculate the position from the previous frame \({K}_{t - 1}\) , but also try to obtain more information to optimize the position of \({K}_{t}\) .
我们提出一种新的局部优化策略来减轻累积误差。当当前帧被确定为关键帧 \({K}_{t}\) 时,我们不仅计算其相对于前一帧 \({K}_{t - 1}\) 的位置,还尝试获取更多信息来优化 \({K}_{t}\) 的位置。
As mentioned above, we store the position of every keyframe \({K}_{i}\left( {i < t}\right)\) . We need to quickly determine the relative keyframes that match the current frame \({K}_{t}\) . The IoU between the current frame \({K}_{t}\) and every previous keyframe is calculated. If the IoU between \({K}_{t}\) and a frame \({K}_{i}\) is greater than a predefined threshold \(P,{K}_{i}\) is considered the relative frame of the current frame. All such frames consist of a candidate keyframe set. The frames in this set will provide important information to optimize the position of the current frame.
如上所述,我们存储每个关键帧 \({K}_{i}\left( {i < t}\right)\) 的位置。我们需要快速确定与当前帧 \({K}_{t}\) 匹配的相对关键帧。计算当前帧 \({K}_{t}\) 与每个先前关键帧之间的交并比(IoU)。如果 \({K}_{t}\) 与某一帧 \({K}_{i}\) 之间的交并比大于预定义的阈值 \(P,{K}_{i}\),则该帧被视为当前帧的相对帧。所有此类帧构成一个候选关键帧集。该集合中的帧将为优化当前帧的位置提供重要信息。
In this formula, we create a set that contains all frames for which the IoU satisfies the condition. After that, the transformations of the current frame from the frames in the set are calculated by matching the features of the pair. For each frame \({K}_{t1},{K}_{t2},\ldots ,{K}_{tn}\) in the set, their homography matrices to the base plane are \({H}_{t1},{H}_{t2},\ldots ,{H}_{tn}\) . For any keyframe \({K}_{ti}\) in this set, we can get the homography \({H}_{ti}^{t}\) from \({K}_{t}\) to \({K}_{ti}\) , then the candidate homography \({H}_{t}\left( i\right)\) from the current frame and the base plane can be calculated through the following formula, which has a form that is similar to Formula (7):
在这个公式中,我们创建一个集合,该集合包含所有交并比(IoU)满足条件的帧。之后,通过匹配当前帧与集合中各帧的特征对,计算当前帧相对于集合中各帧的变换。对于集合中的每一帧\({K}_{t1},{K}_{t2},\ldots ,{K}_{tn}\),它们相对于基准平面的单应性矩阵为\({H}_{t1},{H}_{t2},\ldots ,{H}_{tn}\)。对于该集合中的任意关键帧\({K}_{ti}\),我们可以得到从\({K}_{t}\)到\({K}_{ti}\)的单应性\({H}_{ti}^{t}\),然后可以通过以下公式计算当前帧与基准平面之间的候选单应性\({H}_{t}\left( i\right)\),该公式的形式与公式(7)类似:
A good homography should be one with as little cumulative error as possible. We can calculate all the candidate homography and then query the optimal one. The weighted reprojection error is used as the criterion to judge whether the homography is optimal, which is defined as follows:
一个好的单应性矩阵(homography)应该是累积误差尽可能小的矩阵。我们可以计算所有候选单应性矩阵,然后找出最优的那个。加权重投影误差被用作判断单应性矩阵是否最优的标准,其定义如下:
where \({C}_{tj} \cap {C}_{t}\) represents the matched feature points between \({K}_{t}\) and \({K}_{tj}\) , and the function \(\operatorname{Proj}\left( {x, H}\right)\) represents the coordinate of the point after projecting it back to the reference plane through the homography \(H\) . We use \({IoU}\) to balance out the difference in the number of feature points between different matched image pairs.
其中 \({C}_{tj} \cap {C}_{t}\) 表示 \({K}_{t}\) 和 \({K}_{tj}\) 之间的匹配特征点,函数 \(\operatorname{Proj}\left( {x, H}\right)\) 表示通过单应性矩阵 \(H\) 将点投影回参考平面后的坐标。我们使用 \({IoU}\) 来平衡不同匹配图像对之间特征点数量的差异。
In Formula (11), \(\mathbf{m}\) is the index of the best frame we find. Through Formula (10), we can determine the best frame \({k}_{tm}\) that matches the current frame, and the homography from \({K}_{t}\) to \({K}_{tm}\) is used to project the current frame to the base plane, as referred to in Formula (8). Then, the homography from \({K}_{t}\) to the base plane is determined.
在公式(11)中,\(\mathbf{m}\)是我们找到的最佳帧的索引。通过公式(10),我们可以确定与当前帧匹配的最佳帧\({k}_{tm}\),并使用从\({K}_{t}\)到\({K}_{tm}\)的单应性矩阵将当前帧投影到基准平面,如公式(8)所述。然后,确定从\({K}_{t}\)到基准平面的单应性矩阵。
2.4. Expanding and Generating Panoramas
2.4. 扩展和生成全景图
After local optimization, the keyframe can be projected to the base plane through the resulting homography. However, due to errors caused by image distortion and geometric offset, there will still be misalignment between two geometrically aligned images. We can use some fusion strategies to generate better panoramas. Other methods usually find the best stitching seam to obtain better results. However, the computational cost is very high. In our framework, we refer to the algorithm from map2dfusion [26]. We use a partition-weighted pyramid fusion algorithm to generate the stitching results naturally, and use a partition processing method to make the process faster.
经过局部优化后,关键帧可以通过得到的单应性矩阵投影到基准平面。然而,由于图像畸变和几何偏移导致的误差,两幅几何对齐的图像之间仍然会存在不对齐的情况。我们可以使用一些融合策略来生成更好的全景图。其他方法通常会寻找最佳拼接缝以获得更好的结果。然而,计算成本非常高。在我们的框架中,我们参考了map2dfusion [26]中的算法。我们使用分区加权金字塔融合算法自然地生成拼接结果,并使用分区处理方法使处理过程更快。
In order to reduce the exposure differences and misalignments between the images, a Gaussian pyramid is constructed to fuse multiple scale spaces, and a Laplacian pyramid is computed in the construction process for the restoration of the original image with an expanded operation [32].
为了减少图像之间的曝光差异和对齐误差,构建高斯金字塔以融合多个尺度空间,并在构建过程中计算拉普拉斯金字塔,通过扩展操作恢复原始图像[32]。
To quicken the operation, a k-level Gaussian pyramid is computed first, and each level is subtracted from the lower level of the pyramid [33]:
为加快运算速度,首先计算k级高斯金字塔,并从金字塔的下一层减去每一层[33]:
The highest level equals since there is no higher level computed.
由于没有计算更高层,所以最高层保持不变。
The Gaussian pyramids of the two images have the overlapping area. In traditional methods, the pixel of the overlapping area is usually obtained by the weighted sum or average of the pixel of the two pyramid layers. However, this approach will inevitably produce blur and ghosting.
两幅图像的高斯金字塔存在重叠区域。在传统方法中,重叠区域的像素通常通过两个金字塔层像素的加权和或平均值来获取。然而,这种方法不可避免地会产生模糊和重影。
For an aerial image, the center part of the image is more ortho and has both less distortion and a smaller scale change than the edge. For each image, we construct a mask representing how close each pixel is to the center of the image. As shown in Figure 4, for an image of size \(w \times h\) , we can build a mask \(M\) of the same size. The pixel value in the mask
对于航空图像,图像的中心部分更接近正射,与边缘部分相比,其畸变更小且尺度变化也更小。对于每幅图像,我们构建一个掩码,以表示每个像素与图像中心的接近程度。如图4所示,对于大小为\(w \times h\)的图像,我们可以构建一个相同大小的掩码\(M\)。掩码中的像素值
is as follows:
如下:

Figure 4. An image and its corresponding mask. (a) Image. (b) The mask of this image. The value in the mask represents how close each pixel is to the center of the image.
图4. 一幅图像及其对应的掩码。(a) 图像。(b) 该图像的掩码。掩码中的值表示每个像素与图像中心的接近程度。
As you can see from this formula, we construct a mask with decreasing values from the center of the image to the edge. This formula is used to generate a mask for an image, where the value of the mask falls within the range of 0 to 1 . The value of each pixel in the formula depends on its distance to the center of the image and the diagonal length of the image. The farther the distance, the smaller the corresponding mask value, and the closer the distance, the larger the corresponding mask value. The mask will do the same homography transformation as the corresponding image. The pixels in the overlapping part of the pyramid are determined by comparing the mask pixel at the same position.
从这个公式可以看出,我们构建了一个从图像中心到边缘值逐渐减小的掩码。这个公式用于为图像生成一个掩码,其中掩码的值在0到1的范围内。公式中每个像素的值取决于它到图像中心的距离以及图像的对角线长度。距离越远,对应的掩码值越小;距离越近,对应的掩码值越大。掩码将与对应的图像进行相同的单应性变换。金字塔重叠部分的像素通过比较相同位置的掩码像素来确定。
At the beginning of image fusion, we initialize a canvas of fixed size. When the boundary of the new frame exceeds the canvas boundary, the boundary will be dynamically expanded to ensure the integrity of the canvas.
在图像融合开始时,我们初始化一个固定大小的画布。当新帧的边界超出画布边界时,边界将动态扩展以确保画布的完整性。
In the process of stitching, the panorama keeps growing, and in the fusion algorithm, it is very computationally expensive to build the pyramid and compare the mask size pixel by pixel. Therefore, we adopt the method of local fusion. We captured the pixel change area of the new frame and captured the corresponding area of the panorama and two masks. After fusing them with our algorithm, they are pasted back onto the original canvas. Thus, it greatly reduces the computational complexity and accelerates the operation speed.
在拼接过程中,全景图不断增大,而在融合算法中,构建金字塔并逐像素比较掩码大小的计算成本非常高。因此,我们采用局部融合的方法。我们捕捉新帧的像素变化区域,并获取全景图的相应区域以及两个掩码。使用我们的算法将它们融合后,再将其粘贴回原始画布。这样,大大降低了计算复杂度,加快了运算速度。
2.5. Generating Panorama Geographic Coordinates
2.5. 生成全景地理坐标
Our algorithm can incrementally output high-quality panoramas from image-only input. In some scenarios, we want to output the panoramic with geographic information. This scenario inevitably requires us to input some location information to assist in the stitching process. We can use a small amount of GPS at the beginning of the flight to obtain the geographic information of the panorama. For the first \(\mathrm{n}\) frame keyframe \({K}_{i}\) , we obtain the GPS coordinates \(\left( {{la}{t}_{i},{ln}{g}_{i}}\right)\) f the image center. We convert the GPS coordinates to the UTM coordinate system \(\left( {{X}_{i},{Y}_{i}}\right)\) , and obtain the coordinates on the base plane \(\left( {{x}_{i},{y}_{i}}\right)\) . We believe that in the case that the base plane is parallel to the ground, a simple model can be used to describe their transformation:
我们的算法可以仅从图像输入逐步输出高质量的全景图。在某些场景中,我们希望输出带有地理信息的全景图。这种场景不可避免地要求我们输入一些位置信息以辅助拼接过程。我们可以在飞行开始时使用少量的全球定位系统(GPS)来获取全景图的地理信息。对于第一个\(\mathrm{n}\)帧关键帧\({K}_{i}\),我们获取图像中心的全球定位系统(GPS)坐标\(\left( {{la}{t}_{i},{ln}{g}_{i}}\right)\)。我们将全球定位系统(GPS)坐标转换为通用横轴墨卡托投影(UTM)坐标系\(\left( {{X}_{i},{Y}_{i}}\right)\),并获得基准平面上的坐标\(\left( {{x}_{i},{y}_{i}}\right)\)。我们认为,在基准平面与地面平行的情况下,可以使用一个简单的模型来描述它们之间的转换:
We use this formula to describe a simple rotation and translation model. Let \(A = \cos \theta\) , \(B = \sin \theta\) , and then it can be described as format of matrix operation:
我们使用这个公式来描述一个简单的旋转和平移模型。设\(A = \cos \theta\),\(B = \sin \theta\),然后它可以用矩阵运算的形式来描述:
When \(n > 2\) , we have some redundant observations, and we can construct the formula:
当 \(n > 2\) 时,我们有一些冗余观测值,并且可以构建公式:
We transform the problem into an overdetermined equation to solve the problem. We can use QR decomposition to quickly solve the overdetermined equation and obtain four parameters.
我们将问题转化为超定方程来解决。我们可以使用QR分解(QR decomposition)快速求解超定方程并得到四个参数。
For the following keyframes, we can calculate the coordinates of the corner points of the image in the base plane so that the panoramic image with geographic information can be generated.
对于后续关键帧,我们可以计算图像角点在基准平面中的坐标,从而生成具有地理信息的全景图像。
3. Experiment and Result
3. 实验与结果
In this section, we evaluate our algorithm through a series of experiments. First, we test the overall feasibility and performance of our algorithm with the most popular datasets and our data. Then, we verify the environmental adaptability and robustness of the algorithm by simulating changes in real-world scenarios and sensor variations, such as changes in brightness and random noise.
在本节中,我们通过一系列实验评估我们的算法。首先,我们使用最流行的数据集和我们自己的数据测试算法的整体可行性和性能。然后,我们通过模拟现实场景的变化和传感器的变化(如亮度变化和随机噪声)来验证算法的环境适应性和鲁棒性。
We also verify the algorithm selection of each strategy in our framework. First, we prove the excellent performance of SIFT by testing the performance and robustness of various feature extraction algorithms under the influence of geometric transformations, brightness changes, and random noise. Then, we verify that our frame extraction strategy greatly reduces the mosaic speed without affecting the mosaic results. Finally, we show that our local pose optimization algorithm and fusion algorithm have superior performance compared to the popular ones.
我们还验证了框架中每种策略的算法选择。首先,通过测试各种特征提取算法在几何变换、亮度变化和随机噪声影响下的性能和鲁棒性,证明了尺度不变特征变换(SIFT)算法的卓越性能。然后,验证了我们的帧提取策略在不影响拼接结果的情况下,大大提高了拼接速度。最后,表明我们的局部位姿优化算法和融合算法与流行算法相比具有更优的性能。
3.1. Dataset and Experimental Setup
3.1. 数据集与实验设置
To evaluate the effectiveness of the algorithm, we check it in real UAV aerial sequences. The NPU drone map dataset is adopted; this data set is available on the website [34]. It contains several aerial video sequences taken at different terrains and altitudes and is widely used to evaluate aerial image mosaics. This dataset was collected by the Phantom3 during flight. In addition to the publicly available dataset, we also collected some data using our UAV, the CW-15. Table 1 provides detailed description of the UAVs and sensor parameters used to acquire data.
为了评估该算法的有效性,我们在真实的无人机航拍序列中对其进行了验证。采用了西北工业大学(NPU)无人机地图数据集;该数据集可在文献[34]的网站上获取。它包含了在不同地形和高度拍摄的多个航拍视频序列,被广泛用于评估航拍图像拼接效果。该数据集是由“幻影3”(Phantom3)无人机在飞行过程中采集的。除了公开可用的数据集外,我们还使用自己的CW - 15无人机采集了一些数据。表1详细描述了用于采集数据的无人机和传感器参数。
Table 1. Detailed description of the UAVs and sensors parameters used to acquire data.
表1. 用于采集数据的无人机和传感器参数的详细描述。
| UAV | Camera | CMOS Size (inch) | Focal Distance (mm) | FOV | Photo Size |
| Phantom3 | Phantom3-Camera | 1/2.3 | 20 | ${94}^{ \circ }$ | ${4000} \times {3000}$ |
| CW-15 | CA-103 | 1/1.7 | 31.7 | ${66.6}^{ \circ }$ | ${3840} \times {2160}$ |
| 无人机(UAV) | 相机 | 互补金属氧化物半导体尺寸(英寸)(CMOS Size (inch)) | 焦距(毫米)(Focal Distance (mm)) | 视场角(FOV) | 照片尺寸 |
| 精灵3(Phantom3) | 精灵3相机(Phantom3-Camera) | 1/2.3 | 20 | ${94}^{ \circ }$ | ${4000} \times {3000}$ |
| CW - 15 | CA - 103 | 1/1.7 | 31.7 | ${66.6}^{ \circ }$ | ${3840} \times {2160}$ |
In order to measure the efficiency of our algorithm and reproduce our results more intuitively, we carefully documented our hardware configuration. Our experiments were conducted on a laptop running the Windows 11 operating system, equipped with a Ryzen 5600 U (CPU) and 16 GB RAM. The system configuration provided memory capacity for our experiments, allowing us to carry out large-scale image processing tasks efficiently. Our hardware configuration of the Ryzen 5600 U processor and \({16}\mathrm{{GB}}\) of RAM is a commonly found memory setup and is a low-voltage processor, which further emphasizes that our algorithm is not reliant on high-end hardware.
为了衡量我们算法的效率并更直观地重现我们的结果,我们仔细记录了我们的硬件配置。我们的实验是在一台运行Windows 11操作系统的笔记本电脑上进行的,该电脑配备了锐龙5600 U(CPU)和16GB内存。系统配置为我们的实验提供了内存容量,使我们能够高效地执行大规模图像处理任务。我们配备的锐龙5600 U处理器和\({16}\mathrm{{GB}}\)内存的硬件配置是一种常见的内存设置,并且该处理器是低压处理器,这进一步表明我们的算法不依赖于高端硬件。
3.2. Real-Scene Experiment
3.2. 真实场景实验
This section describes a set of experiments designed to validate the performance of the proposed framework in real UAV aerial scenes. In the NPU drone map, we select three groups of photographic sequences, including three scenes: village, highway, and factory. We also took some photos with our own UAV and selected a complex industrial park for testing. See Table 2 for the detailed data of image sequences.
本节描述了一组旨在验证所提出的框架在真实无人机航测场景中性能的实验。在NPU无人机地图中,我们选择了三组摄影序列,包括三种场景:村庄、高速公路和工厂。我们还使用自己的无人机拍摄了一些照片,并选择了一个复杂的工业园区进行测试。图像序列的详细数据见表2。
Table 2. Test Image Sequences Information. 'H-max' denotes the maximum flight height and "Area" denotes the area of ground.
表2. 测试图像序列信息。“H - max”表示最大飞行高度,“Area”表示地面面积。
| Sequence | Location | UAV | H-Max (m) | Area $\left( {\mathrm{{km}}}^{2}\right)$ | Frames |
| Phantom3-village | Hengdong, Hunan | Phantom3 | 196.6 | 0.932 | 406 |
| Phantom3-huangqi | Hengdong, Hunan | Phantom3 | 222.3 | 1.313 | 393 |
| Phantom3-factory | Luoyang, Henan | Phantom3 | 181.8 | 0.782 | 406 |
| CW15-boyang | Gongqingcheng, Jiangxi | CW15 | 152.5 | 0.735 | 235 |
| 序列 | 位置 | 无人机(UAV) | 最大高度(米)(H-Max (m)) | 面积 $\left( {\mathrm{{km}}}^{2}\right)$ | 帧 |
| 幻影3村(Phantom3-village) | 湖南衡东 | 幻影3(Phantom3) | 196.6 | 0.932 | 406 |
| 幻影3黄岐(Phantom3-huangqi) | 湖南衡东 | 幻影3(Phantom3) | 222.3 | 1.313 | 393 |
| 幻影3工厂(Phantom3-factory) | 河南洛阳 | 幻影3(Phantom3) | 181.8 | 0.782 | 406 |
| CW15-鄱阳 | 江西共青城 | CW15 | 152.5 | 0.735 | 235 |
From Figure 5, we can see the experimental results of sequences in the Phantom3- factory, Phantom3-huangqi, and Phantom3-factory selected from the NPU drone map, and our own data CW15-boyang.
从图5中,我们可以看到从西北工业大学(NPU)无人机地图中选取的Phantom3-工厂、Phantom3-黄旗和Phantom3-工厂序列,以及我们自己的数据CW15-鄱阳的实验结果。
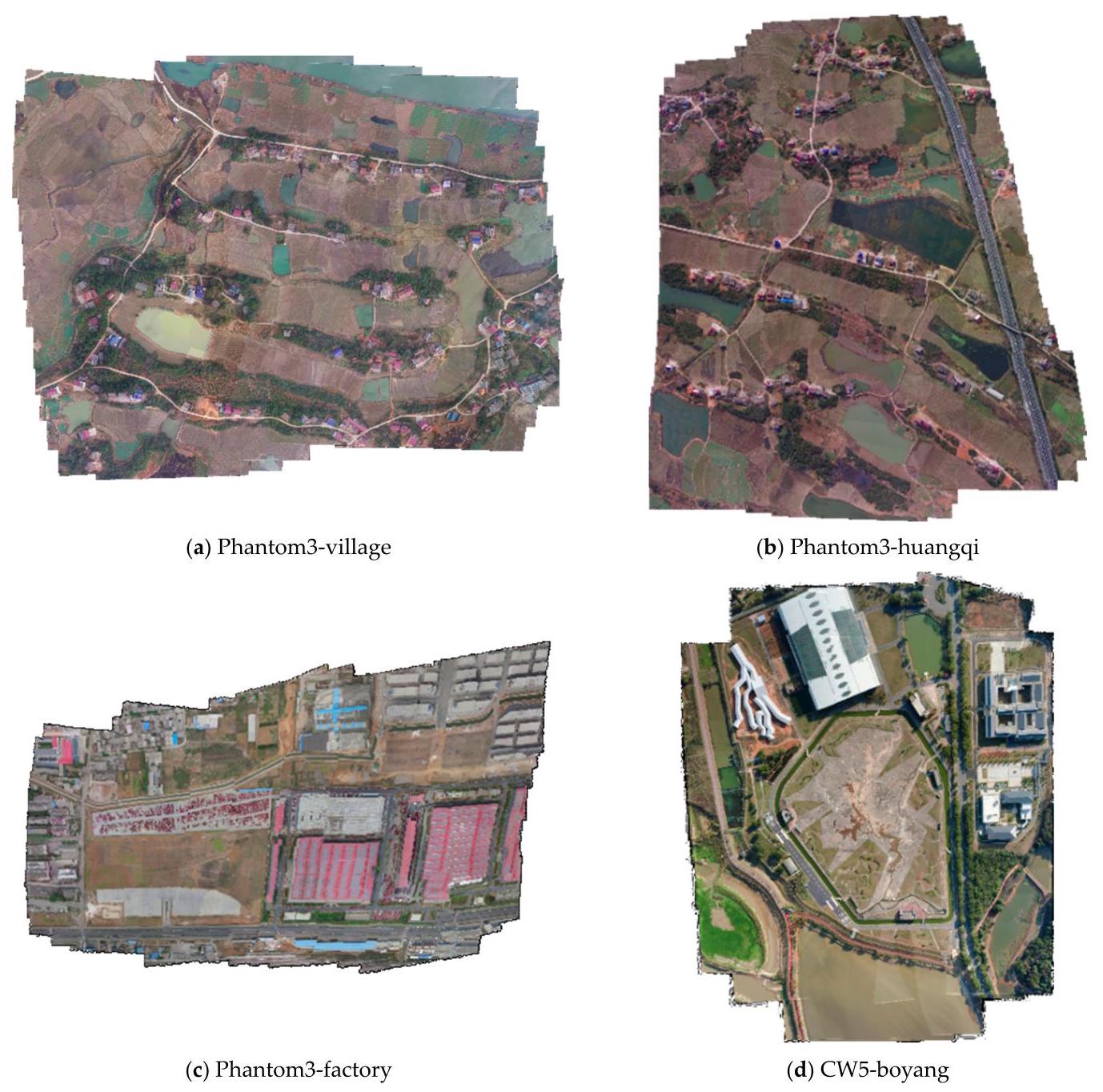
Figure 5. UAV image mosaicking result of the proposed system in real scenes. The sequences Phantom3-village, Phantom3-huangqi, and Phantom3-factory are from the NPU drone map dataset and CW5-boyang is collected by us.
图5. 所提出的系统在真实场景中的无人机图像拼接结果。Phantom3-村庄、Phantom3-黄旗和Phantom3-工厂序列来自西北工业大学(NPU)无人机地图数据集,CW5-鄱阳是我们自己采集的。
Sequence Phantom3-village was taken by a phantom3 UAV in the area of Hengdong, Hunan, and the mosaic results are shown in the first row and first column of Figure 5. The area mainly covers a plain of scattered villages with several running paths. The paths are well mosaicked and the houses are shown in their original shapes. The upper part of the area is adjacent to a piece of water. Its feature points are unstable and difficult to extract, so the position of the calculated image is affected and some gaps on the waterfront are not fully aligned.
Phantom3-村庄序列是由一架Phantom3无人机在湖南衡东地区拍摄的,拼接结果显示在图5的第一行第一列。该区域主要覆盖着一个有几条跑道的零散村庄平原。跑道拼接良好,房屋呈现出原始形状。该区域的上部与一片水域相邻。其特征点不稳定且难以提取,因此计算出的图像位置受到影响,水边的一些缝隙没有完全对齐。
Phantom3-huangqi was taken by a phantom3 UAV in the area of Hengdong, Hunan, and the mosaic results can be seen on the right side of the first row of Figure 5. This is mainly a plain area traversed by a highway, interspersed with waters. It covers an area of 1.31 square kilometers, but most of the parts can be regarded as planes, so the mosaic results of the roads and waters are pretty good. However, the roads at the edge are misaligned. This is because our algorithm eliminates the cumulative error by searching the neighborhood of the current frame and then optimizing it locally, and the road at the edge lacks surrounding supports. However, multiple images in the same strip also inhibit the expansion of this misalignment.
“Phantom3 - 黄岐(Phantom3 - huangqi)”影像由一架Phantom3无人机在湖南衡东(Hengdong)地区拍摄,拼接结果可在图5第一行右侧看到。这主要是一个有高速公路穿过、水域穿插其中的平原地区。该区域面积为1.31平方公里,但大部分区域可视为平面,因此道路和水域的拼接效果相当不错。然而,边缘的道路存在错位现象。这是因为我们的算法通过搜索当前帧的邻域然后进行局部优化来消除累积误差,而边缘的道路缺乏周围的支撑。不过,同一条带中的多幅图像也抑制了这种错位的扩大。
Phantom3-factory was taken by a phantom3 UAV in the area of Luoyang, Henan Province, and the mosaic results are shown on the left side of the second line. This set of images includes some open spaces such as factory buildings and parking lots. There are some misalignments at the edges of some houses because of the shape of the houses and the relief of the terrain. However, thanks to our optimization algorithm, these misalignment errors are not accumulated in the mosaic process. They are just scattered in the image and do not lead to greater misalignment. Moreover, because of our fusion algorithm, strong pixel segmentation does not appear in the images, and in most affected areas, pixel transitions are natural and reasonable.
“幻影3号”工厂(Phantom3-factory)的影像由一架“幻影3号”无人机(phantom3 UAV)在河南省洛阳市区域内拍摄,拼接结果显示在第二行左侧。这组影像包含了一些如厂房和停车场之类的开阔区域。由于房屋形状和地形起伏,部分房屋边缘存在一些拼接错位情况。不过,得益于我们的优化算法,这些拼接错位误差在拼接过程中不会累积。它们只是分散在影像中,不会导致更大的错位。此外,由于我们的融合算法,影像中不会出现明显的像素分割现象,在大多数受影响区域,像素过渡自然合理。
The last set of the data sequence is obtained by CW-15 UAV in a test site. In this sequence, our UAV kept flying at a low altitude of about \({150}\mathrm{\;m}\) . The area contains an open space surrounded by houses of different sizes, and waters at the edge of the area. Although there are many elements in the image, our algorithm still restores this area well, and the details are restored better because of the low flight altitude. The edge of the white house in the image produces some small pixel misalignment, which is caused by the lack of relevant frames for position settlement when the UAV reaches the edge of the strip. However, the misalignment is corrected by the algorithm in the image mosaic and does not cause greater misalignments.
数据序列的最后一组是由CW - 15无人机(CW - 15 UAV)在一个试验场获取的。在该序列中,我们的无人机保持在约\({150}\mathrm{\;m}\)的低空飞行。该区域包含一片被不同大小房屋环绕的空地,以及区域边缘的水域。尽管图像中有许多元素,但我们的算法仍然很好地还原了该区域,并且由于低空飞行,细节还原得更好。图像中白色房屋的边缘产生了一些小的像素错位,这是由于无人机到达条带边缘时缺乏用于位置确定的相关帧造成的。然而,这种错位在图像拼接过程中被算法纠正,不会导致更大的错位。
The experiment shows excellent performance and robustness in the sequences of different ground objects taken by different UAVs at different flight altitudes. The keyframe extraction strategy and local optimization strategy of our algorithm greatly reduces the common error accumulation in multi-strip mosaics, and our fusion algorithm also makes some small mosaic misalignments more natural and improves the overall mosaic performance.
实验表明,该算法在不同无人机于不同飞行高度拍摄的不同地物序列中表现出了出色的性能和鲁棒性。我们算法的关键帧提取策略和局部优化策略大大减少了多航带拼接中常见的误差累积,并且我们的融合算法还使一些小的拼接错位更加自然,提高了整体拼接性能。
3.3. Robustness Experiment
3.3. 鲁棒性实验
In this section, we focus on the robustness of our algorithm in different scenarios. The robustness experiments consist of two parts: robustness experiments to changes in lighting and noise, and robustness experiments to moving targets. The former tests our algorithm's performance under different weather conditions and images obtained from different sensors through a series of artificial changes of brightness and noise, while the latter examines whether our algorithm is robust to interference from moving targets.
在本节中,我们重点关注我们的算法在不同场景下的鲁棒性。鲁棒性实验包括两部分:光照和噪声变化的鲁棒性实验,以及移动目标的鲁棒性实验。前者通过一系列人为改变亮度和噪声的操作,测试我们的算法在不同天气条件下以及从不同传感器获取的图像上的性能,而后者则检验我们的算法是否对移动目标的干扰具有鲁棒性。
3.3.1. Robustness Experiment to Changes in Lighting and Noise
3.3.1. 光照和噪声变化的鲁棒性实验
Due to different sensors and weather changes, it is difficult to ensure consistency in image quality, though it is obtained after surveying and mapping the same area. The image quality is usually affected by random noise and brightness changes. However, an excellent algorithm needs to be able to run stably in a variety of situations.
由于不同的传感器和天气变化,即使对同一区域进行测绘后获取的图像,也难以保证图像质量的一致性。图像质量通常会受到随机噪声和亮度变化的影响。然而,一个优秀的算法需要能够在各种情况下稳定运行。
We selected Phantom3-village to process the image sequence. Each image in the sequence is completely random as to whether noise is added, the ratio of noise added, whether brightness changes are made, the region of brightness changes, and the intensity. We use the newly generated data as the input of the algorithm, and compare the speed and quality with the unprocessed mosaic results. The experimental results are shown in Figure 6.
我们选择了Phantom3 - 村庄(Phantom3 - village)来处理图像序列。序列中的每一幅图像在是否添加噪声、添加噪声的比例、是否进行亮度变化、亮度变化的区域以及变化强度等方面都是完全随机的。我们将新生成的数据作为算法的输入,并将处理速度和质量与未处理的拼接结果进行比较。实验结果如图6所示。
In the mosaic result, many irregular bright blocks and dark blocks are distributed in the image. These blocks affect our feature performance at different scales. However, SIFT extraction algorithms are not sensitive to brightness and noise, and our local optimization algorithm can eliminate those misalignments. As a result, there are no serious misalignments, and the accuracy is not greatly affected compared with the original mosaic results.
在拼接结果中,图像中分布着许多不规则的亮块和暗块。这些块会在不同尺度上影响我们的特征表现。然而,尺度不变特征变换(SIFT,Scale-Invariant Feature Transform)提取算法对亮度和噪声不敏感,并且我们的局部优化算法可以消除那些对齐误差。因此,不存在严重的对齐误差,与原始拼接结果相比,精度没有受到太大影响。
However, in some areas, such as in the yellow frame, a few pixel misalignments are shown in the road. The overall mosaic result performs well.
然而,在某些区域,如黄色框内,道路上出现了一些像素对齐误差。整体拼接结果表现良好。
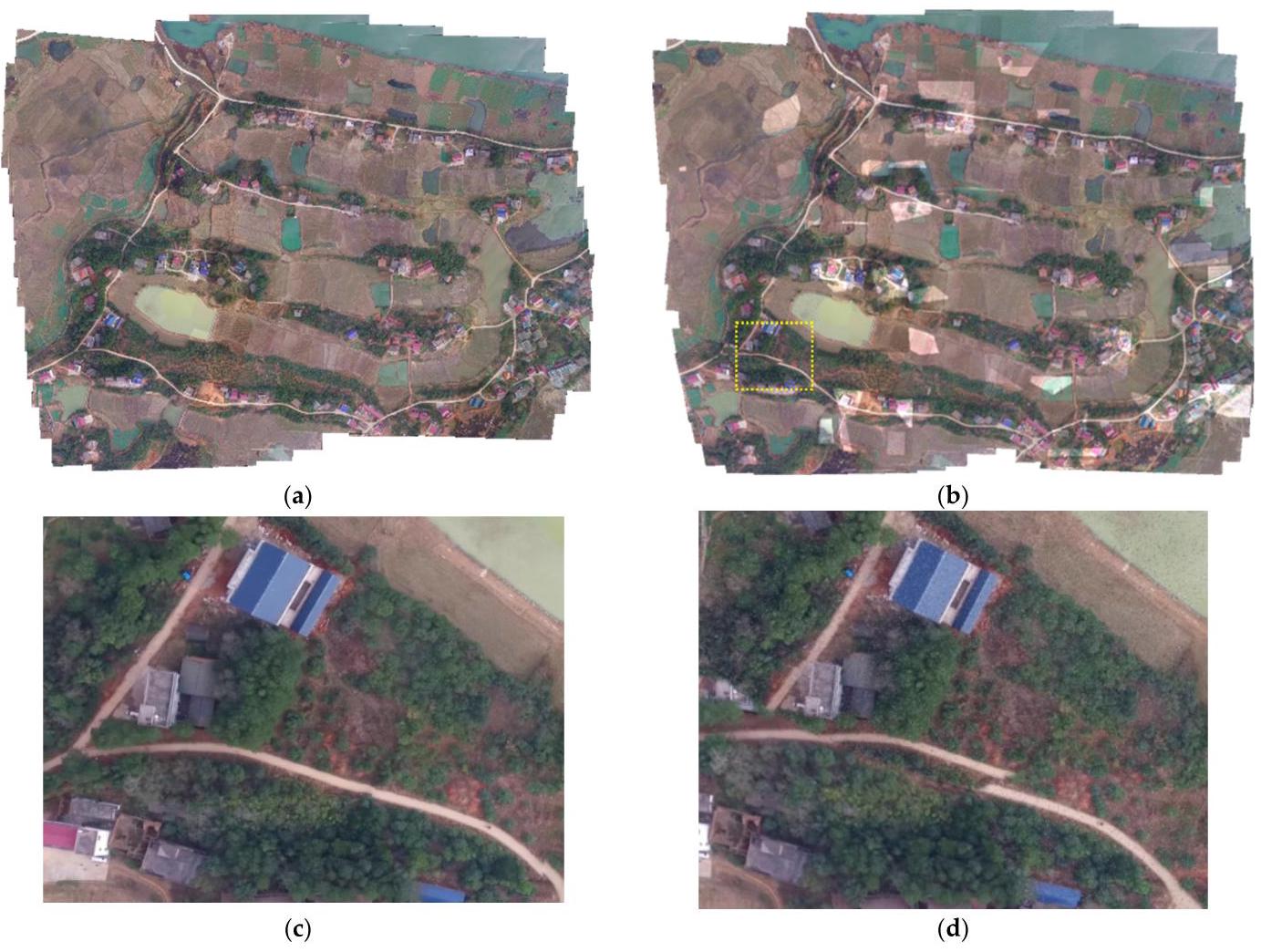
Figure 6. Comparison of sequences. Original Phantom3-village (a) and the randomly processed one (b). Images(c, d)are the detail of the yellow dash box in panoramas.
图6. 序列对比。原始的Phantom3-村庄图像(a)和随机处理后的图像(b)。图像(c,d)是全景图中黄色虚线框的细节。
To sum up, the proposed image mosaic algorithm is robust to brightness changes. It can avoid image brightness adjustment preprocessing, thus reducing the computational burden.
综上所述,所提出的图像拼接算法对亮度变化具有鲁棒性。它可以避免图像亮度调整预处理,从而减轻计算负担。
3.3.2. Robustness Experiment of Moving Targets
3.3.2. 移动目标的鲁棒性实验
In practical applications, moving targets often exist in image sequences, which may affect the stitching result. In this study, we use real-world data containing motion targets to verify the robustness of our algorithm in this aspect. We captured aerial imagery of a road using the CW-15 with three flight strips to demonstrate the robustness of our algorithm in the presence of moving targets. The road had many moving vehicles, and the vehicles' positions were not fixed in each frame, making it more challenging than stitching frames without moving targets. We processed the collected data with our algorithm and obtained the following results:
在实际应用中,图像序列中往往存在运动目标,这可能会影响拼接结果。在本研究中,我们使用包含运动目标的真实世界数据来验证我们的算法在这方面的鲁棒性。我们使用CW - 15(CW - 15)无人机以三条航带拍摄了一条道路的航空影像,以证明我们的算法在存在运动目标时的鲁棒性。这条道路上有许多行驶的车辆,并且车辆在每一帧中的位置都不固定,这比拼接没有运动目标的帧更具挑战性。我们使用我们的算法处理了收集到的数据,并得到了以下结果:
Figure 7a shows the trajectory of the collected data, indicating that we flew three flight lines above the road to ensure multiple captures. Figure \(7\mathrm{\;b}\) is the result of our algorithm, which shows that the panorama is not misaligned due to moving targets such as vehicles. We calculate the position of each frame by computing the transformation of a large number of matching point pairs. In this process, moving vehicles are treated as noise. Unlike the least squares algorithm, which is sensitive to noise, the RANSAC algorithm we used separates all data into inliers and outliers, thereby accurately computing the transformation while removing noise. Moreover, Figure 7c shows a close-up of the vehicles on the road. Our fusion algorithm ensures that the images of the vehicles on the road are clear without blurring or ghosting, contrary to expectations. More comparative experiments and analyses of fusion algorithms can be found in Section 3.4.6.
图7a展示了所采集数据的轨迹,表明我们在道路上方飞行了三条航线,以确保多次捕获数据。图\(7\mathrm{\;b}\)是我们算法的结果,显示全景图不会因车辆等移动目标而出现错位。我们通过计算大量匹配点对的变换来计算每一帧的位置。在这个过程中,移动的车辆被视为噪声。与对噪声敏感的最小二乘法不同,我们使用的随机抽样一致性(RANSAC)算法将所有数据分为内点和外点,从而在去除噪声的同时准确计算变换。此外,图7c展示了道路上车辆的特写。与预期相反,我们的融合算法确保道路上车辆的图像清晰,没有模糊或重影。关于融合算法的更多对比实验和分析可在3.4.6节中找到。
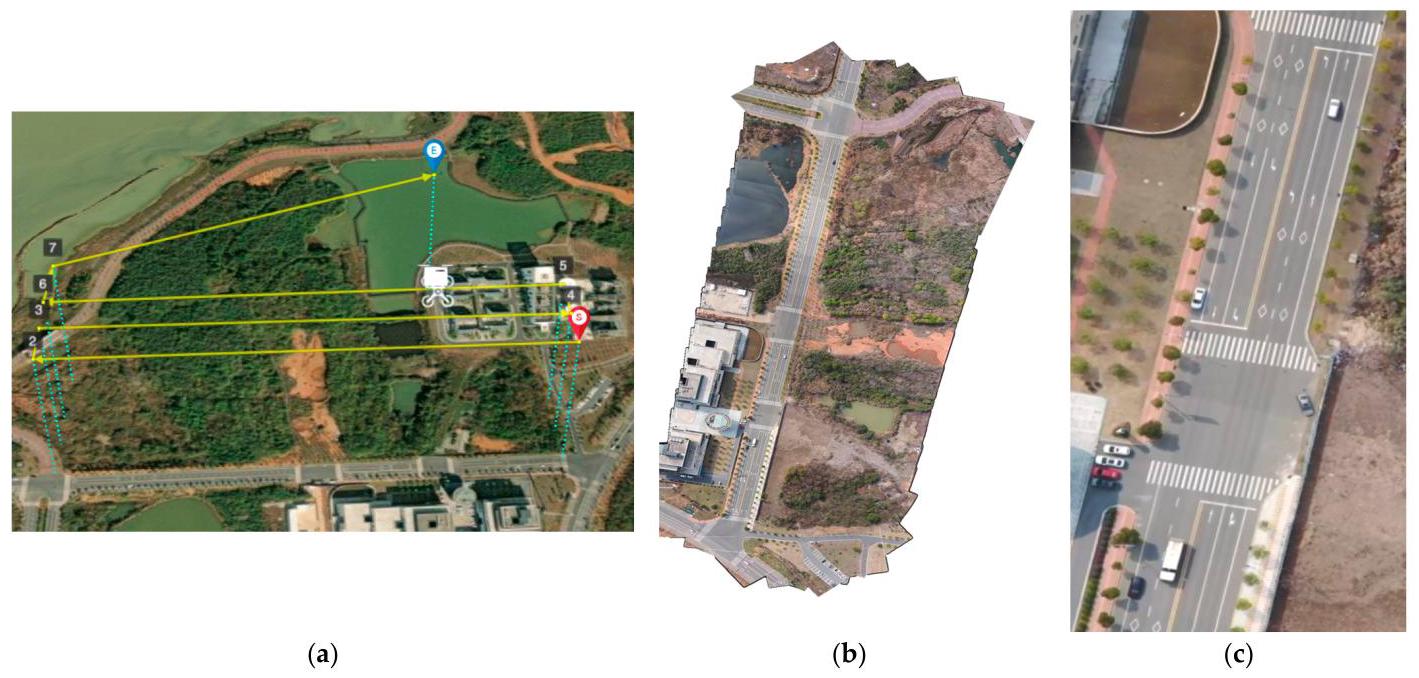
Figure 7. Result of robustness experiment of moving targets. Including (a) flight trajectory, (b) panorama from our framework and (c) detailed close-up of the vehicle.
图7. 移动目标鲁棒性实验结果。包括(a)飞行轨迹,(b)我们框架生成的全景图,以及(c)车辆的详细特写。
The above experiments and results demonstrate that our algorithm exhibits strong robustness when processing images containing moving targets. It effectively avoids image stitching errors caused by moving targets, and with the help of our fusion algorithm, moving targets in the image can also be correctly displayed in the panoramic image. Therefore, our algorithm has great practical value for processing images in real scenes.
上述实验及结果表明,我们的算法在处理包含运动目标的图像时表现出了很强的鲁棒性。它能有效避免因运动目标导致的图像拼接错误,并且借助我们的融合算法,图像中的运动目标也能在全景图像中正确显示。因此,我们的算法在处理真实场景中的图像方面具有很大的实用价值。
3.4. Comparative Experiment
3.4. 对比实验
In this section, we designed a series of comparative experiments. The comparison experiment included two parts: comparison of strategies and comparisons with other UAV mosaicking algorithms. The comparison of strategies was conducted to demonstrate the effectiveness of the strategies selected in our framework. We designed four sets of comparative experiments to demonstrate the superiority of the SIFT extraction algorithms we selected over other feature extraction algorithms, as detailed in Sections 3.4.1-3.4.4. In this section, we simulate image transformations in different environments and measure the performance of feature extraction algorithms by matching them using different feature extraction techniques. We visualize these matches, although due to the large number of connecting lines between matched points, it may be difficult to distinguish each line with the naked eye. However, we can judge the overall trend. Generally, better feature extraction algorithms can obtain matching lines with consistent directions. To further illustrate this trend, we have calculated the correct matching rate and processing time of these feature extraction algorithms to quantitatively measure their performance.
在本节中,我们设计了一系列对比实验。对比实验包括两部分:策略对比和与其他无人机图像拼接算法的对比。进行策略对比是为了证明我们框架中所选策略的有效性。我们设计了四组对比实验,以证明我们所选的尺度不变特征变换(SIFT)提取算法相对于其他特征提取算法的优越性,具体细节见3.4.1 - 3.4.4节。在本节中,我们模拟不同环境下的图像变换,并通过使用不同的特征提取技术对特征进行匹配来衡量特征提取算法的性能。我们将这些匹配结果可视化,尽管由于匹配点之间的连接线数量众多,可能难以用肉眼区分每条线。然而,我们可以判断总体趋势。一般来说,更好的特征提取算法可以获得方向一致的匹配线。为了进一步说明这一趋势,我们计算了这些特征提取算法的正确匹配率和处理时间,以定量衡量它们的性能。
We also validated the effectiveness of our keyframe selection strategy through a set of ablation experiments detailed in Section 3.4.5. Finally, we compared our fusion algorithm with other fusion methods to demonstrate its efficacy in Section 3.4.6. In the comparison experiment with other UAV mosaicking algorithms, we validated the performance of our framework in terms of effect and speed by comparing it with mature commercial software such as QuickBird [35] and AutoPano [36], as well as advanced stitching algorithms such as Open-Stitcher [37].
我们还通过一组在3.4.5节中详细介绍的消融实验验证了我们关键帧选择策略的有效性。最后,我们在3.4.6节中将我们的融合算法与其他融合方法进行了比较,以证明其有效性。在与其他无人机图像拼接算法的对比实验中,我们通过将我们的框架与成熟的商业软件(如快鸟(QuickBird)[35]和自动全景(AutoPano)[36])以及先进的拼接算法(如开放拼接器(Open - Stitcher)[37])进行比较,从效果和速度方面验证了我们框架的性能。
3.4.1. Comparative Experiment of Feature Extraction Algorithms under Random Noise
3.4.1. 随机噪声下特征提取算法的对比实验
Salt and pepper noise is common in UAV images, which is usually caused by pixel failure due to sensor interference or transmission error. We add random salt and pepper noise to images to test the performance of various features. We evaluate our algorithm by matching images with and without special processing using different features, using processing time as an efficiency indicator and match rate as a quality indicator. The experimental results are shown in Figure 8 and Table 3.
椒盐噪声在无人机图像中很常见,通常是由传感器干扰导致的像素故障或传输错误引起的。我们向图像中添加随机椒盐噪声以测试各种特征的性能。我们通过使用不同特征对经过特殊处理和未经过特殊处理的图像进行匹配来评估我们的算法,使用处理时间作为效率指标,使用匹配率作为质量指标。实验结果如图8和表3所示。

Figure 8. The matching of the original image with the image added with a salt and pepper noise using (a) SIFT feature algorithm (b) SURF feature algorithm (c) ORB feature algorithm.
图8. 使用(a)SIFT特征算法(尺度不变特征变换算法,Scale-Invariant Feature Transform)、(b)SURF特征算法(加速稳健特征算法,Speeded Up Robust Features)、(c)ORB特征算法对原始图像与添加了椒盐噪声的图像进行匹配。
As the results show, among the three features, the SIFT feature extraction algorithm has the highest matching rate, reaching 63%, and is 10% higher than the other two feature extraction algorithms, which are only half of the correct rate. It shows that the SIFT has the strongest resistance to salt and pepper noise and is more robust to different sensors and environments.
结果表明,在这三种特征中,SIFT特征提取算法的匹配率最高,达到63%,比其他两种特征提取算法高出10%,而后两者的正确率仅为SIFT算法的一半。这表明SIFT算法对椒盐噪声的抗性最强,并且对不同的传感器和环境具有更强的鲁棒性。
Table 3. Results of the image matching by adding salt and pepper noise randomly. the image changed brightness. The best result is marked in bold.
表3. 随机添加椒盐噪声和改变图像亮度后的图像匹配结果。最佳结果用粗体标记。
| Feature Extraction Algorithm | Time (s) | Matches | Correct Matches | Match Rate |
| SIFT | 0.387 | 7970 | 5036 | 0.632 |
| SURF | 0.502 | 10987 | 5865 | 0.534 |
| ORB | 0.050 | 500 | 251 | 0.502 |
| 特征提取算法 | 时间(秒) | 匹配项 | 正确匹配项 | 匹配率 |
| 尺度不变特征变换(SIFT) | 0.387 | 7970 | 5036 | 0.632 |
| 加速稳健特征(SURF) | 0.502 | 10987 | 5865 | 0.534 |
| 定向 FAST 和旋转 BRIEF(ORB) | 0.050 | 500 | 251 | 0.502 |
3.4.2. Comparative Experiment of Feature Extraction Algorithms under Random Brightness Change
3.4.2. 随机亮度变化下特征提取算法的对比实验
When the UAV takes aerial photos, due to time and position differences, the image will show different shadows and the local brightness of the image changes. We randomly pick some areas on the image to change the brightness and test the performance of features. The results are shown in Figure 9 and Table 4:
无人机进行航空摄影时,由于时间和位置的差异,图像会呈现出不同的阴影,且图像的局部亮度会发生变化。我们随机选取图像上的一些区域来改变亮度,并测试特征的性能。结果如图9和表4所示:

Figure 9. The matching of the original image with the image changed brightness using (a) SIFT feature extraction algorithm (b) SURF feature extraction algorithm (c) ORB feature extraction algorithm.
图9. 原始图像与亮度改变后的图像的匹配情况,采用(a)尺度不变特征变换(SIFT)特征提取算法 (b)加速稳健特征(SURF)特征提取算法 (c)Oriented FAST and Rotated BRIEF(ORB)特征提取算法。
Table 4. Results of comparing the image with the image changed in brightness. The best result is marked in bold.
表4. 原始图像与亮度改变后的图像的对比结果。最佳结果用粗体标记。
| Feature Extraction Algorithm | Time (s) | Matches | Correct Matches | Match Rate |
| SIFT | 0.368 | 7970 | 7857 | 0.986 |
| SURF | 0.524 | 10987 | 10678 | 0.972 |
| ORB | 0.042 | 500 | 381 | 0.762 |
| 特征提取算法 | 时间(秒) | 匹配项 | 正确匹配项 | 匹配率 |
| 尺度不变特征变换(SIFT) | 0.368 | 7970 | 7857 | 0.986 |
| 加速稳健特征(SURF) | 0.524 | 10987 | 10678 | 0.972 |
| 定向 FAST 和旋转 BRIEF(ORB) | 0.042 | 500 | 381 | 0.762 |
From the result, the SIFT feature extraction algorithm has the highest matching rate of 98%, while the ORB has the lowest. Thus, the SIFT feature extraction algorithm has better robustness under aerial survey tasks with more brightness changes.
从结果来看,尺度不变特征变换(SIFT)特征提取算法的匹配率最高,达到了98%,而Oriented FAST and Rotated BRIEF(ORB)算法的匹配率最低。因此,在亮度变化较大的航测任务中,尺度不变特征变换(SIFT)特征提取算法具有更好的鲁棒性。
3.4.3. Comparative Experiment of Feature Extraction Algorithm under Random Rotation
3.4.3. 随机旋转条件下特征提取算法的对比实验
The angle change of the image is very common in UAV mapping. This geometric transformation leads to the absolute orientation change of the image. We tested the rotation of 45 degrees, and the results are shown in Figure 10 and Table 5.
在无人机测绘中,图像的角度变化非常常见。这种几何变换会导致图像的绝对方位发生改变。我们测试了45度旋转的情况,结果如图10和表5所示。

Figure 10. Cont.
图10. 续

Figure 10. The matching of the original image with its rotated image using: (a) SIFT feature extraction algorithm (b) SURF feature extraction algorithm (c) ORB feature extraction algorithm.
图10. 原始图像与其旋转图像的匹配情况,采用:(a) 尺度不变特征变换(SIFT)特征提取算法 (b) 加速稳健特征(SURF)特征提取算法 (c) Oriented FAST and Rotated BRIEF(ORB)特征提取算法。
Table 5. Results of comparing the image with its rotated image. The best result is marked in bold.
表5. 图像与其旋转图像的对比结果。最佳结果用粗体标记。
| Feature Extraction Algorithm | Time (s) | Matches | Correct Matches | Match Rate |
| SIFT | 0.731 | 7544 | 4846 | 0.642 |
| SURF | 0.636 | 10954 | 4870 | 0.445 |
| ORB | 0.084 | 500 | 325 | 0.650 |
| 特征提取算法 | 时间(秒) | 匹配项 | 正确匹配项 | 匹配率 |
| 尺度不变特征变换(SIFT) | 0.731 | 7544 | 4846 | 0.642 |
| 加速稳健特征(SURF) | 0.636 | 10954 | 4870 | 0.445 |
| 定向 FAST 和旋转 BRIEF(ORB) | 0.084 | 500 | 325 | 0.650 |
The ORB feature extraction algorithm has a correct matching rate of 65%, the SIFT feature extraction algorithm is almost the same as the ORB feature extraction algorithm, and the SURF feature extraction algorithm is less resistant to rotation. As shown in Table 6, we compare the performance of each feature extraction algorithms at 45 degree intervals. The result shows that the SIFT feature extraction algorithm has the best matching rate when the rotation angle is a multiple of 90 , and the ORB feature extraction algorithm has the best matching rate in other cases, but the difference between the SIFT feature extraction algorithm and ORB feature extraction algorithm matching rate is small in these cases, while SURF has the lowest matching rate at all angles.
ORB特征提取算法的正确匹配率为65%,SIFT特征提取算法与ORB特征提取算法几乎相同,而SURF特征提取算法的抗旋转能力较差。如表6所示,我们以45度为间隔比较了各特征提取算法的性能。结果表明,当旋转角度为90的倍数时,SIFT特征提取算法的匹配率最高;在其他情况下,ORB特征提取算法的匹配率最高,但在这些情况下,SIFT特征提取算法和ORB特征提取算法的匹配率差异较小,而SURF在所有角度下的匹配率最低。
Table 6. Matching rate versus the rotation angle. Best results are marked in bold.
表6. 匹配率与旋转角度的关系。最佳结果用粗体标记。
| Feature Extraction Algorithm | ${45}^{ \circ }$ | ${90}^{ \circ }$ | ${\mathbf{{135}}}^{ \circ }$ | ${\mathbf{{180}}}^{ \circ }$ | ${225}^{ \circ }$ | ${270}^{ \circ }$ |
| SIFT | 0.642 | 0.966 | 0.638 | 0.955 | 0.639 | 0.970 |
| SURF | 0.445 | 0.962 | 0.444 | 0.951 | 0.445 | 0.963 |
| ORB | 0.650 | 0.916 | 0.666 | 0.880 | 0.674 | 0.918 |
| 特征提取算法 | ${45}^{ \circ }$ | ${90}^{ \circ }$ | ${\mathbf{{135}}}^{ \circ }$ | ${\mathbf{{180}}}^{ \circ }$ | ${225}^{ \circ }$ | ${270}^{ \circ }$ |
| 尺度不变特征变换(SIFT) | 0.642 | 0.966 | 0.638 | 0.955 | 0.639 | 0.970 |
| 加速稳健特征(SURF) | 0.445 | 0.962 | 0.444 | 0.951 | 0.445 | 0.963 |
| 定向 FAST 和旋转 BRIEF(ORB) | 0.650 | 0.916 | 0.666 | 0.880 | 0.674 | 0.918 |
3.4.4. Comparative Experiment of Feature Extraction Algorithms under Scale Change
3.4.4. 尺度变化下特征提取算法的对比实验
During the flight of the UAV, altitude changes leads to a scale change of the same ground area in the image. We randomly changed the scale and tested the performance of features. The results are shown in Figure 11 and Table 7.
无人机飞行过程中,高度变化会导致图像中同一地面区域的尺度发生变化。我们随机改变尺度并测试特征的性能。结果如图11和表7所示。

Figure 11. The matching of the original image with its scaled image using: (a) SIFT feature extraction algorithm (b) SURF feature extraction algorithm (c) ORB feature extraction algorithm.
图11. 使用以下算法对原始图像及其缩放图像进行匹配:(a) SIFT特征提取算法(尺度不变特征变换,Scale - Invariant Feature Transform)(b) SURF特征提取算法(加速稳健特征,Speeded - Up Robust Features)(c) ORB特征提取算法(Oriented FAST and Rotated BRIEF)。
Table 7. Results of comparing the image with its scaled image. The best result is marked in bold.
表7. 图像与其缩放图像的对比结果。最佳结果用粗体标记。
| Feature Extraction Algorithm | Time (s) | Matches | Correct Matches | Accuracy |
| SIFT | 0.249 | 1765 | 3530 | 0.751 |
| SURF | 0.393 | 4254 | 8508 | 0.721 |
| ORB | 0.032 | 500 | 273 | 0.546 |
| 特征提取算法 | 时间(秒) | 匹配项 | 正确匹配项 | 准确率 |
| 尺度不变特征变换(SIFT) | 0.249 | 1765 | 3530 | 0.751 |
| 加速稳健特征(SURF) | 0.393 | 4254 | 8508 | 0.721 |
| 定向 FAST 和旋转 BRIEF(ORB) | 0.032 | 500 | 273 | 0.546 |
The SIFT feature extraction algorithm has the highest matching rate in scale change and performs much better than the ORB feature extraction algorithm. The SIFT feature extraction algorithm has high robustness when UAV flight altitude changes, so it can still get excellent matches when the scale changes.
尺度不变特征变换(SIFT,Scale-Invariant Feature Transform)特征提取算法在尺度变化时具有最高的匹配率,其性能远优于定向 FAST 和旋转 BRIEF(ORB,Oriented FAST and Rotated BRIEF)特征提取算法。当无人机飞行高度发生变化时,SIFT 特征提取算法具有较高的鲁棒性,因此在尺度变化时仍能获得出色的匹配效果。
3.4.5. Comparison of Keyframe Selection Strategies
3.4.5. 关键帧选择策略比较
The aerial sequence acquired by the UAV has a lot of images. In the mosaic process, we do not regard every image acquired as the keyframe needed for final mapping. Sparse selection is easy to fail, and full frame mosaicking will make a lot of redundant calculations. Such calculations do not improve the mapping results much, but the computational resources consumed are huge. We designed an experiment to prove the effectiveness of our keyframe selection algorithm and we adopted the phantom3-village sequence. First, we do not use any selection strategies, and all images participate in settlement for mosaicking, timing, and storing results. Then, we use our keyframe selection strategy to compare their performance and efficiency. The results are as Table 8 and Figure 12.
无人机获取的航拍序列包含大量图像。在拼接过程中,我们不会将获取的每一幅图像都视为最终成图所需的关键帧。稀疏选择容易失败,而全帧拼接会产生大量冗余计算。此类计算对成图结果的改善作用不大,但消耗的计算资源却十分巨大。我们设计了一个实验来验证所提出的关键帧选择算法的有效性,并采用了 phantom3 - 村庄序列。首先,不使用任何选择策略,让所有图像参与拼接结算、计时并存储结果。然后,使用我们的关键帧选择策略,比较它们的性能和效率。结果如表 8 和图 12 所示。
Table 8. Comparison of full frame mosaicking and keyframe selection mosaicking.
表 8. 全帧拼接与关键帧选择拼接的比较。
| Full Frame Mosaicking | Keyframe Selection Mosaicking | |
| Adopt frames/all frames | 406/406 | 118/406 |
| Time consumed (s) | 384 | 77 |
| 全帧拼接 | 关键帧选择拼接 | |
| 采用帧/所有帧 | 406/406 | 118/406 |
| 耗时(秒) | 384 | 77 |

Figure 12. Comparison of full frame mosaicking and keyframe selection mosaicking. (a) Full frame mosaicking. (b) Keyframe selection mosaicking.
图12. 全帧拼接与关键帧选择拼接的比较。(a) 全帧拼接。(b) 关键帧选择拼接。
As shown in Figure 12, both strategies have successfully obtained panoramas in multi-strip aerial survey missions. A total of 118 frames from this set of data are keyframes. Our algorithm selects \(1/4\) frames for subsequent solution and mosaicking. The mosaic results of our algorithm do not show obvious pixel misalignment and mismatching. Thanks to the fact that we use fewer frames to solve the problem, our algorithm only takes \({77}\mathrm{\;s}\) , which is equivalent to 1/5 of the algorithm without keyframe selection, which enables our algorithm to mosaic images in real-time during the data transmission from the UAV. However, we discarded a part of the image at the edge, so the edges of the images are coarser than the algorithm without selecting keyframes. However, in the aerial survey mission, the number and length of strips set by the UAV include redundant observations at the edges of the survey area. Under this premise, our algorithm will not lose the information on the survey area.
如图12所示,在多航带航测任务中,两种策略均成功获取了全景图。该组数据中共有118帧为关键帧。我们的算法选择了\(1/4\)帧进行后续解算和拼接。我们算法的拼接结果没有明显的像素错位和不匹配现象。由于我们使用较少的帧来解决问题,我们的算法仅需\({77}\mathrm{\;s}\),相当于未进行关键帧选择算法所需时间的五分之一,这使得我们的算法能够在无人机数据传输过程中实时拼接图像。然而,我们舍弃了一部分边缘图像,因此图像边缘比未选择关键帧的算法更粗糙。不过,在航测任务中,无人机设置的航带数量和长度在测区边缘包含了冗余观测。在此前提下,我们的算法不会丢失测区的信息。
3.4.6. Comparison of Fusion Methods
3.4.6. 融合方法比较
Fusion is an important step in panoramic image generation. However, the difference in camera exposure, incomplete alignment geometric transformation, and the simple superposition of two images will lead to obvious visual disharmony. That is why an excellent fusion algorithm is needed. For two images, we tend to focus on their fusion effect at the seam and the inconsistent pixels. We compare four fusion methods:
融合是全景图像生成中的重要步骤。然而,相机曝光差异、几何变换对齐不完全以及两幅图像的简单叠加会导致明显的视觉不协调。这就是为什么需要一种优秀的融合算法。对于两幅图像,我们倾向于关注它们在接缝处的融合效果以及不一致的像素。我们比较四种融合方法:
-
Simple coverage, that is, after aligning two images, pixel coverage is performed.
-
简单覆盖,即对齐两幅图像后进行像素覆盖。
-
Weighted fusion. For the overlapping parts of two images, we weigh the pixel values of both to calculate the new pixel values.
-
加权融合。对于两幅图像的重叠部分,我们对两者的像素值进行加权以计算新的像素值。
-
Weight substitution. For each image, we construct a mask to express the priority value of the pixel, which represents the position of the pixel near the center of the image. Then, we compare the mask of the two images to decide which pixel to choose.
-
权重替换。对于每幅图像,我们构建一个掩码来表示像素的优先级值,该值代表像素靠近图像中心的位置。然后,我们比较两幅图像的掩码以决定选择哪个像素。
-
Our method.
-
我们的方法。
The stitching results are shown in Figure 13, and the result of seam and house in the panorama are shown in Figures 14 and 15. After simple coverage, the seam is serious with no algorithm processing. The ground and the house do not show their complete shapes. With the weighted fusion algorithm, the seam is not that serious, but houses are ghosting. The effect of the weight substitution algorithm is similar to that of direct substitution, but in multi-strip sequence images, the weight replacement algorithm can make the obtained panorama more similar to the result obtained after shooting vertically down. Finally, our method, with the help of the Gaussian pyramid, fuses in multiple scales to eliminate stiff seams and preserves the details of the house well without ghosting.
拼接结果如图13所示,全景图中接缝和房屋的结果分别如图14和图15所示。经过简单覆盖后,若不进行算法处理,接缝问题严重。地面和房屋无法呈现完整形状。采用加权融合算法时,接缝问题有所减轻,但房屋出现重影。权重替换算法的效果与直接替换算法类似,但在多带序列图像中,权重替换算法能使得到的全景图更接近垂直向下拍摄后得到的结果。最后,我们的方法借助高斯金字塔进行多尺度融合,消除了生硬的接缝,很好地保留了房屋的细节,且无重影现象。

Figure 13. Compositing comparison using different fusion methods. (a) Simple coverage. (b) Weighted fusion. (c) Weight substitution. (d) Our method.
图13. 使用不同融合方法的合成对比。(a) 简单覆盖。(b) 加权融合。(c) 权重替换。(d) 我们的方法。

Figure 14. Compositing comparison of seam in panorama using different fusion methods. (a) Simple coverage. (b) Weighted fusion. (c) Weight substitution. (d) Our method.
图14. 使用不同融合方法的全景图中接缝的合成对比。(a) 简单覆盖。(b) 加权融合。(c) 权重替换。(d) 我们的方法。

Figure 15. Cont.
图15. 续

Figure 15. Compositing comparison of house in panorama using different fusion methods. (a) Simple coverage. (b) Weighted fusion. (c) Weight substitution. (d) Our method.
图15. 使用不同融合方法对全景图中的房屋进行合成的比较。(a) 简单覆盖。(b) 加权融合。(c) 权重替换。(d) 我们的方法。
3.4.7. Comparison with Other UAV Mosaicking Algorithms
3.4.7. 与其他无人机拼接算法的比较
In our experiments, we compared QuickBird [35] and AutoPano [36], two pieces of well-established commercial stitching software, with Opencv-Stitcher, an advanced stitching algorithm. Our experiments were conducted on the Phantom3-village, and the results of each algorithm are presented in Figure 16. Additionally, Figure 17 displays the details of the roads, while Figure 18 highlights the details of the houses. In order to compare the efficiency of the algorithm, we recorded the algorithm time consumed, which can be seen in Table 9.
在我们的实验中,我们将两款成熟的商业拼接软件QuickBird [35]和AutoPano [36]与先进的拼接算法Opencv - Stitcher进行了比较。我们的实验在Phantom3 - 村庄数据集上进行,每种算法的结果如图16所示。此外,图17展示了道路的细节,而图18突出显示了房屋的细节。为了比较算法的效率,我们记录了算法消耗的时间,如表9所示。
Table 9. Comparison of time consuming.
表9. 耗时比较。
| QuickBird | AutoPano | Opencv-Stitcher | Our Method | |
| ned | $1\mathrm{\;{min}},{11}\mathrm{\;s}$ | 48 min, 04 s | Stitch-failure | 1 min, 17 s |
| 快鸟卫星(QuickBird) | 自动全景拼接软件(AutoPano) | 开源计算机视觉库图像拼接器(Opencv - Stitcher) | 我们的方法 | |
| 东北天坐标系(ned) | $1\mathrm{\;{min}},{11}\mathrm{\;s}$ | 48分04秒 | 缝线失效 | 1分17秒 |
Quick-Bird is a real-time processing system for dynamic drone videos. It is a real-time map stitching software developed independently by company ZTmapper [35], which solves another major problem in photogrammetry and fills a long-standing gap in this field both domestically and abroad. Quick-Bird is an unmanned aerial video processing system that integrates advantages such as a fully automatic processing process, real-time keyframe extraction and stitching, support for target detection, and massive data processing capabilities. Autopano is a product of the virtual reality software company Kolor [36]. It is a powerful, easy-to-use, practical, and professional image stitching software that supports more than 400 input file formats. Opencv-stitcher is a new module added in OpenCV 2.4.0 [37]. Its function is to achieve image stitching. The algorithm has many parameters, including feature point categories, coordinate transformation models, and so on. In the experiment, the parameters were set as default.
快鸟(Quick-Bird)是一款用于动态无人机视频的实时处理系统。它是ZTmapper公司[35]自主研发的实时地图拼接软件,解决了摄影测量领域的另一个重大问题,填补了国内外该领域长期存在的空白。快鸟(Quick-Bird)是一款无人机视频处理系统,集成了全自动处理流程、实时关键帧提取与拼接、支持目标检测以及海量数据处理能力等优势。全景自动拼接软件(Autopano)是虚拟现实软件公司科洛尔(Kolor)[36]的产品。它是一款功能强大、易于使用、实用且专业的图像拼接软件,支持400多种输入文件格式。OpenCV图像拼接器(Opencv-stitcher)是OpenCV 2.4.0版本[37]中新增的一个模块,其功能是实现图像拼接。该算法有许多参数,包括特征点类别、坐标变换模型等。在实验中,参数设置为默认值。
We observed that QuickBird, AutoPano and our method successfully stitched together the panorama, while Opencv-Stitcher failed to do so. Particularly, in Figure 17, we can see a road that spans two flight strips, which QuickBird and AutoPano were unable to stitch successfully, but our method was able to. This is because our method greatly suppresses the cumulative error caused by dozens of images between two flight strips. Additionally, we observed that when dealing with the breakage of roads, QuickBird employed a rough fusion method, which made the breakage very abrupt, while AutoPano used a weighted fusion method to handle visual errors, but this method made the broken road very blurry. In contrast, our method can better preserve the structure of the road and does not produce obvious breakage or blurring.
我们观察到,快鸟(QuickBird)、自动全景拼接软件(AutoPano)和我们的方法都成功地拼接出了全景图,而OpenCV拼接器(Opencv-Stitcher)未能做到这一点。特别是在图17中,我们可以看到一条横跨两个航带的道路,快鸟(QuickBird)和自动全景拼接软件(AutoPano)无法成功拼接这条道路,但我们的方法可以。这是因为我们的方法极大地抑制了两个航带之间数十张图像所导致的累积误差。此外,我们还观察到,在处理道路断裂问题时,快鸟(QuickBird)采用了一种粗略的融合方法,使得断裂处非常突兀,而自动全景拼接软件(AutoPano)使用了加权融合方法来处理视觉误差,但这种方法使断裂的道路变得非常模糊。相比之下,我们的方法能够更好地保留道路的结构,不会产生明显的断裂或模糊现象。

Figure 16. Comparison panorama using different methods. (a) QuickBird. (b) AutoPano. (c) Opencv-Stitcher. (d) Our method.
图16. 不同方法的全景图对比。(a) 快鸟(QuickBird)。(b) 自动全景拼接软件(AutoPano)。(c) OpenCV拼接器(Opencv-Stitcher)。(d) 我们的方法。

Figure 17. Cont.
图17. 续。

Figure 17. Comparison of road in panorama using different methods. (a) QuickBird. (b) AutoPano. (c) Opencv-Stitcher. (d) Our method.
图17. 不同方法全景图中道路的对比。(a) 快鸟(QuickBird)。(b) 自动全景拼接软件(AutoPano)。(c) OpenCV拼接器(Opencv-Stitcher)。(d) 我们的方法。

Figure 18. Comparison of house in panorama using different methods. (a) QuickBird. (b) AutoPano. (c) Opencv-Stitcher. (d) Our method.
图18. 使用不同方法的全景房屋对比。(a)快鸟(QuickBird)。(b)自动全景(AutoPano)。(c)开源计算机视觉拼接器(Opencv-Stitcher)。(d)我们的方法。
In Figure 18, we show the details of houses. Due to the height differences between buildings and the ground, even with perfect registration, pixel displacement may occur. Therefore, an efficient fusion algorithm is needed to eliminate this phenomenon. We found that QuickBird still used a rough fusion method here, resulting in some buildings being directly truncated, while AutoPano's result manifested as many, very blurry buildings. Compared to this, our method can display the structure of the buildings clearly and does not produce truncation or blurring phenomena.
在图18中,我们展示了房屋的细节。由于建筑物与地面之间存在高度差,即使进行了完美的配准,也可能会出现像素位移。因此,需要一种有效的融合算法来消除这种现象。我们发现,快鸟(QuickBird)在此仍采用了一种粗略的融合方法,导致一些建筑物被直接截断,而自动全景(AutoPano)的结果显示为许多非常模糊的建筑物。相比之下,我们的方法可以清晰地显示建筑物的结构,并且不会产生截断或模糊现象。
After comparing the processing times of different algorithms, our algorithm was able to complete the stitching of 406 images in the Phantom3-village dataset with a resolution of 1920*1080 within \(1\mathrm{\;{min}}\) and \({17}\mathrm{\;s}\) . This processing time is similar to that of the QuickBird algorithm, while the AutoPano algorithm took over 48 min to generate a panorama of this dataset.
在比较不同算法的处理时间后,我们的算法能够在\(1\mathrm{\;{min}}\)和\({17}\mathrm{\;s}\)内完成对幻影3村庄(Phantom3-village)数据集中406张分辨率为1920*1080的图像的拼接。这个处理时间与快鸟(QuickBird)算法相近,而自动全景(AutoPano)算法生成该数据集的全景图则花费了超过48分钟。
The Phantom3-village dataset covers an area of 0.9 square kilometers, and it typically takes several minutes for a drone to capture the necessary images. Our algorithm is capable of real-time parallel stitching during the process of image transmission from the drone.
幻影3(Phantom3)乡村数据集覆盖面积为0.9平方公里,无人机通常需要几分钟才能捕获所需图像。在无人机传输图像的过程中,我们的算法能够进行实时并行拼接。
Therefore, by comparing our method with QuickBird and AutoPano, we found that our method performs better in stitching panoramic images and can better handle visual errors and fusion problems. This proves the effectiveness and feasibility of our method in UAV image mosaickin.
因此,通过将我们的方法与快鸟(QuickBird)和自动全景(AutoPano)进行比较,我们发现我们的方法在拼接全景图像方面表现更好,并且能够更好地处理视觉误差和融合问题。这证明了我们的方法在无人机图像拼接中的有效性和可行性。
4. Discussion
4. 讨论
Through experiments on public datasets and our collected data, we verify the effectiveness of our algorithm. Our algorithm can output high-quality results in various ground scenes, and remains robust under the influence of varying lighting conditions and sensor noise. Additionally, we tested the keyframe selection strategy and the weighted partition fusion method based on the Laplacian pyramid. Experiments show that our keyframe selection strategy can greatly accelerate the stitching speed without affecting the result quality so that our algorithm can synchronize when the UAV executes the task. Compared to other methods, our fusion method not only preserves the complete form of ground objects such as tall buildings, but also avoids obvious ghosting and stiff seams, so as to output better panorama.
通过在公共数据集和我们收集的数据上进行实验,我们验证了我们算法的有效性。我们的算法可以在各种地面场景中输出高质量的结果,并且在不同光照条件和传感器噪声的影响下仍保持稳健。此外,我们测试了关键帧选择策略和基于拉普拉斯金字塔的加权分区融合方法。实验表明,我们的关键帧选择策略可以在不影响结果质量的情况下大大加快拼接速度,从而使我们的算法能够在无人机执行任务时同步。与其他方法相比,我们的融合方法不仅保留了高层建筑等地面物体的完整形态,还避免了明显的重影和生硬的接缝,从而输出更好的全景图。
5. Conclusions
5. 结论
In this paper, we propose a real-time incremental UAV image mosaicking framework, which only uses the UAV image sequence. The results suggest that our proposed real-time incremental UAV image mosaicking framework shows promising performance compared to other existing methods. Our keyframe selection strategy can greatly accelerate the speed of mosaicking. Moreover, we introduce frame fuzzy positioning and new local optimization strategy, which minimizes the parallax and cumulative error of large sequence images. The fusion algorithm we adopt also makes the algorithm result better.
在本文中,我们提出了一种仅使用无人机图像序列的实时增量式无人机图像拼接框架。结果表明,与其他现有方法相比,我们提出的实时增量式无人机图像拼接框架表现出了良好的性能。我们的关键帧选择策略可以大大加快拼接速度。此外,我们引入了帧模糊定位和新的局部优化策略,这将大序列图像的视差和累积误差降至最低。我们采用的融合算法也使算法效果更好。
While our algorithm has promising applications in UAV mapping, emergency management and other fields, it is important to consider its limitations when applying it in real-world scenarios. Our algorithm is aimed at tasks that require fast generation of large panoramic images, such as post-disaster assessments and search and rescue operations. In these tasks, the UAV often needs to fly at higher altitudes to cover larger areas. However, flying at too-low altitudes can increase the impact of dynamic objects and can potentially violate the homography assumption between images. This limitation should be taken into consideration when applying our algorithm in real-world scenarios.
虽然我们的算法在无人机测绘、应急管理等领域有良好的应用前景,但在实际场景中应用时,考虑其局限性很重要。我们的算法针对的是需要快速生成大尺寸全景图像的任务,如灾后评估和搜救行动。在这些任务中,无人机通常需要在更高的高度飞行以覆盖更大的区域。然而,飞行高度过低会增加动态物体的影响,并可能违反图像间的单应性假设。在实际场景中应用我们的算法时,应考虑到这一局限性。
In the future, we will improve the local optimization strategy, further reduce the cumulative error, and find a better algorithm to optimize our algorithm under the condition of GPS. We will also focus on expanding the scope of its applications. Specifically, we aim to apply our algorithm to a wider range of tasks, such as urban planning and infrastructure inspection. To achieve this, we will improve the robustness and scalability of our algorithm, allowing it to handle larger and more complex datasets.
未来,我们将改进局部优化策略,进一步降低累积误差,并在全球定位系统(GPS)条件下寻找更好的算法来优化我们的算法。我们还将着重拓展其应用范围。具体而言,我们旨在将我们的算法应用于更广泛的任务,如城市规划和基础设施检查。为实现这一目标,我们将提高算法的鲁棒性和可扩展性,使其能够处理更大、更复杂的数据集。
Author Contributions: Conceptualization, R.L. and P.G.; methodology, R.L. and X.C. (Xiangyuan Cai); software, R.L. and X.C. (Xiaotong Chen); validation, J.W. and Y.C.; writing-original draft preparation, R.L. and P.G.; writing-review and editing, R.L. and H.Z.; supervision, H.Z.; funding acquisition, H.Z. All authors have read and agreed to the published version of the manuscript.
作者贡献:概念构思,R.L. 和 P.G.;方法学,R.L. 和 X.C.(蔡祥远);软件,R.L. 和 X.C.(陈小桐);验证,J.W. 和 Y.C.;初稿撰写,R.L. 和 P.G.;稿件审核与编辑,R.L. 和 H.Z.;指导,H.Z.;资金获取,H.Z.。所有作者都已阅读并同意该论文的发表版本。
Funding: This research was funded by the National Key Research and Development Program of China, grant number No. 2022YFF0904403 and the National Natural Science Foundation of China, grant number No. 42130104.
资金支持:本研究得到了中国国家重点研发计划(项目编号:2022YFF0904403)和中国国家自然科学基金(项目编号:42130104)的资助。
Data Availability Statement: The data presented in this study are available upon request from the corresponding author.
数据可用性声明:本研究中呈现的数据可应通讯作者的要求提供。
Conflicts of Interest: The authors declare no conflict of interest.
利益冲突:作者声明不存在利益冲突。
References
参考文献
-
Zhang, W.; Li, X.; Yu, J.; Kumar, M.; Mao, Y. Remote sensing image mosaic technology based on SURF algorithm in agriculture. EURASIP J. Image Video Process. 2018, 2018, 1-9. [CrossRef]
-
张,W.;李,X.;余,J.;库马尔,M.;毛,Y. 基于SURF算法的农业遥感影像拼接技术。《欧洲信号处理协会期刊:图像与视频处理》2018年,2018,1 - 9。[CrossRef]
-
Ghosh, D.; Kaabouch, N. A survey on image mosaicing techniques. J. Vis. Commun. Image Represent. 2016, 34, 1-11. [CrossRef]
-
戈什,D.;卡布奇,N. 图像拼接技术综述。《视觉通信与图像表示期刊》2016年,34,1 - 11。[CrossRef]
-
Ghannam, S.; Abbott, A.L. Cross correlation versus mutual information for image mosaicing. Int. J. Adv. Comput. Sci. Appl. (IJACSA) 2013, 4. [CrossRef]
-
加纳姆,S.;阿博特,A.L. 图像拼接中的互相关与互信息比较。《国际高级计算机科学与应用期刊》(IJACSA)2013年,4。[CrossRef]
-
Szeliski, R. Image alignment and stitching: A tutorial. Found. Trends Comput. Graph. Vis. 2007, 2, 1-104. [CrossRef]
-
斯泽利斯基(Szeliski, R.)。图像对齐与拼接:教程。《计算机图形与视觉基础与趋势》(Found. Trends Comput. Graph. Vis.)2007年,第2卷,第1 - 104页。[参考文献交叉引用]
-
Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91-110. [CrossRef]
-
洛维(Lowe, D.G.)。基于尺度不变关键点的独特图像特征。《国际计算机视觉杂志》(Int. J. Comput. Vis.)2004年,第60卷,第91 - 110页。[参考文献交叉引用]
-
Yang, L.; Wu, X.; Zhai, J.; Li, H. A research of feature-based image mosaic algorithm. In Proceedings of the 2011 4th International Congress on Image and Signal Processing, Shanghai, China, 15-17 October 2011; Volume 2, pp. 846-849.
-
杨(Yang, L.);吴(Wu, X.);翟(Zhai, J.);李(Li, H.)。基于特征的图像拼接算法研究。收录于《2011年第四届图像与信号处理国际会议论文集》,中国上海,2011年10月15 - 17日;第2卷,第846 - 849页。
-
Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6-13 November 2011; pp. 2564-2571.
-
鲁布利(Rublee, E.);拉博(Rabaud, V.);科诺利奇(Konolige, K.);布拉德斯基(Bradski, G.)。ORB:SIFT或SURF的高效替代方案。收录于《2011年国际计算机视觉会议论文集》,西班牙巴塞罗那,2011年11月6 - 13日;第2564 - 2571页。
-
Xiao, J.; Zhang, Y.; Shah, M. Adaptive region-based video registration. In Proceedings of the 2005 Seventh IEEE Workshops on Applications of Computer Vision (WACV/MOTION’05)-Volume 1, Breckenridge, CO, USA, 5-7 January 2005; Volume 2, pp. 215-220.
-
肖(Xiao),J.;张(Zhang),Y.;沙阿(Shah),M. 基于自适应区域的视频配准。见《2005 年第七届 IEEE 计算机视觉应用研讨会(WACV/MOTION’05)论文集》 - 第 1 卷,美国科罗拉多州布雷肯里奇,2005 年 1 月 5 - 7 日;第 2 卷,第 215 - 220 页。
-
Prescott, J.; Clary, M.; Wiet, G.; Pan, T.; Huang, K. Automatic registration of large set of microscopic images using high-level features. In Proceedings of the 3rd IEEE International Symposium on Biomedical Imaging: Nano to Macro, Arlington, VA, USA, 6-9 April; 2006; pp. 1284-1287.
-
普雷斯科特(Prescott),J.;克莱里(Clary),M.;维特(Wiet),G.;潘(Pan),T.;黄(Huang),K. 利用高级特征对大量显微图像进行自动配准。见《第三届 IEEE 生物医学成像国际研讨会:从纳米到宏观》论文集,美国弗吉尼亚州阿灵顿,2006 年 4 月 6 - 9 日;第 1284 - 1287 页。
-
Deshmukh, M.; Bhosle, U. A survey of image registration. Int. J. Image Process. (IJIP) 2011, 5, 245.
-
德什穆克(Deshmukh, M.);博斯勒(Bhosle, U.)。图像配准综述。《国际图像处理杂志》(Int. J. Image Process. (IJIP))2011年,第5卷,第245页。
-
DeTone, D.; Malisiewicz, T.; Rabinovich, A. Superpoint: Self-supervised interest point detection and description. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18-22 June 2018; pp. 224-236.
-
德托内(DeTone, D.);马利谢维奇(Malisiewicz, T.);拉比诺维奇(Rabinovich, A.)。超级点:自监督兴趣点检测与描述。见《2018年美国犹他州盐湖城IEEE计算机视觉与模式识别研讨会论文集》,2018年6月18 - 22日;第224 - 236页。
-
Yi, K.M.; Trulls, E.; Lepetit, V.; Fua, P. Lift: Learned invariant feature transform. In Proceedings of the Computer Vision-ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11-14 October 2016; Springer International Publishing: Midtown Manhattan, New York City, NY, USA, 2016; pp. 467-483, Proceedings, Part VI 14.
-
伊(Yi, K.M.);特鲁尔斯(Trulls, E.);勒佩蒂(Lepetit, V.);富阿(Fua, P.)。Lift:学习不变特征变换。见《2016年计算机视觉 - ECCV第14届欧洲会议论文集》,2016年10月11 - 14日,荷兰阿姆斯特丹;施普林格国际出版公司:美国纽约市曼哈顿中城,2016年;第467 - 483页,论文集,第VI部分14。
-
Tian, Y.; Fan, B.; Wu, F. L2-net: Deep learning of discriminative patch descriptor in euclidean space. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21-26 July 2017; pp. 661-669.
-
田(Tian),Y.;范(Fan),B.;吴(Wu),F. L2网络:欧几里得空间中判别性图像块描述符的深度学习。见《IEEE计算机视觉与模式识别会议论文集》,美国夏威夷州火奴鲁鲁,2017年7月21 - 26日;第661 - 669页。
-
Christiansen, P.H.; Kragh, M.F.; Brodskiy, Y.; Karstoft, H. Unsuperpoint: End-to-end unsupervised interest point detector and descriptor. arXiv 2019, arXiv:1907.04011.
-
克里斯蒂安森(Christiansen),P.H.;克拉格(Kragh),M.F.;布罗德斯基(Brodskiy),Y.;卡斯托夫特(Karstoft),H. 无监督关键点:端到端无监督兴趣点检测器和描述符。预印本arXiv 2019,arXiv:1907.04011。
-
Rocco, I.; Arandjelovic, R.; Sivic, J. Convolutional neural network architecture for geometric matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21-26 July 2017; pp. 6148-6157.
-
罗科(Rocco),I.;阿兰杰洛维奇(Arandjelovic),R.;西维奇(Sivic),J. 用于几何匹配的卷积神经网络架构。见《IEEE计算机视觉与模式识别会议论文集》,美国夏威夷州火奴鲁鲁,2017年7月21 - 26日;第6148 - 6157页。
-
DeTone, D.; Malisiewicz, T.; Rabinovich, A. Deep image homography estimation. arXiv 2016, arXiv:1606.03798.
-
德托内(DeTone),D.;马利谢维奇(Malisiewicz),T.;拉宾诺维奇(Rabinovich),A. 深度图像单应性估计。预印本arXiv 2016,arXiv:1606.03798。
-
Nie, L.; Lin, C.; Liao, K.; Liu, M.; Zhao, Y. A view-free image stitching network based on global homography. J. Vis. Commun. Image Represent. 2020, 73, 102950. [CrossRef]
-
聂(Nie),L.;林(Lin),C.;廖(Liao),K.;刘(Liu),M.;赵(Zhao),Y. 一种基于全局单应性的无视角图像拼接网络。《视觉通信与图像表示杂志》(J. Vis. Commun. Image Represent.)2020年,73卷,102950页。[参考文献交叉引用]
-
Nie, L.; Lin, C.; Liao, K.; Liu, S.; Zhao, Y. Unsupervised deep image stitching: Reconstructing stitched features to images. IEEE Trans. Image Process. 2021, 30, 6184-6197. [CrossRef] [PubMed]
-
聂(Nie),L.;林(Lin),C.;廖(Liao),K.;刘(Liu),S.;赵(Zhao),Y. 无监督深度图像拼接:将拼接特征重构为图像。《IEEE图像处理汇刊》(IEEE Trans. Image Process.)2021年,30卷,6184 - 6197页。[参考文献交叉引用] [医学文献数据库索引]
-
Yahyanejad, S.; Wischounig-Strucl, D.; Quaritsch, M.; Rinner, B. Incremental mosaicking of images from autonomous, small-scale uavs. In Proceedings of the 2010 7th IEEE International Conference on Advanced Video and Signal Based Surveillance, Boston, MA, USA, 29 August-1 September 2010; pp. 329-336.
-
亚亚内贾德(Yahyanejad),S.;维绍尼希 - 斯特鲁克(Wischounig - Strucl),D.;夸里奇(Quaritsch),M.;林纳(Rinner),B. 自主小型无人机图像的增量式拼接。收录于《2010年第七届IEEE高级视频与基于信号的监控国际会议论文集》,美国马萨诸塞州波士顿,2010年8月29日 - 9月1日;第329 - 336页。
-
Avola, D.; Foresti, G.L.; Martinel, N.; Micheloni, C. Daniele Pannone and Claudio Piciarelli Real-time incremental and geo-referenced mosaicking by small-scale UAVs. In Proceedings of the Image Analysis and Processing-ICIAP 2017: 19th International Conference, Part I 19. Catania, Italy, 11-15 September 2017; pp. 694-705.
-
阿沃拉(Avola),D.;福雷斯蒂(Foresti),G.L.;马蒂内尔(Martinel),N.;米凯洛尼(Micheloni),C. 丹尼尔·潘诺内(Daniele Pannone)和克劳迪奥·皮恰雷利(Claudio Piciarelli) 小型无人机的实时增量地理参考镶嵌。 收录于《图像分析与处理 - ICIAP 2017:第19届国际会议,第一部分》19。 意大利卡塔尼亚(Catania),2017年9月11 - 15日; 第694 - 705页。
-
Liu, Q.; Liu, W.; Zou, L.; Wang, J.; Liu, Y. A new approach to fast mosaic UAV images. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2011, 38, 271-276. [CrossRef]
-
刘(Liu),Q.;刘(Liu),W.;邹(Zou),L.;王(Wang),J.;刘(Liu),Y. 一种快速拼接无人机图像的新方法。 《国际摄影测量、遥感与空间信息科学档案》2011年,38卷,第271 - 276页。 [参考文献交叉引用]
-
Zhao, Y.; Cheng, Y.; Zhang, X.; Xu, S.; Bu, S.; Jiang, H.; Han, P.; Li, K.; Wan, G. Real-Time Orthophoto Mosaicing on Mobile Devices for Sequential Aerial Images with Low Overlap. Remote Sens. 2020, 12, 3739. [CrossRef]
-
赵(Zhao),Y.;程(Cheng),Y.;张(Zhang),X.;徐(Xu),S.;卜(Bu),S.;江(Jiang),H.;韩(Han),P.;李(Li),K.;万(Wan),G. 用于低重叠连续航空影像的移动设备实时正射影像镶嵌。 《遥感》2020年,12卷,第3739页。 [参考文献交叉引用]
-
Ren, X.; Sun, M.; Zhang, X.; Liu, L. A simplified method for UAV multispectral images mosaicking. Remote Sens. 2017, 9, 962. [CrossRef]
-
任(Ren),X.;孙(Sun),M.;张(Zhang),X.;刘(Liu),L. 一种无人机多光谱图像拼接的简化方法。《遥感》(Remote Sens.)2017年,第9卷,第962页。[CrossRef]
-
Ye, J.G.; Chen, H.T.; Tsai, W.J. Panorama generation based on aerial images. In Proceedings of the 2018 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), San Diego, CA, USA, 23-27 July 2018; pp. 1-6.
-
叶(Ye),J.G.;陈(Chen),H.T.;蔡(Tsai),W.J. 基于航空影像的全景图生成。见《2018年电气与电子工程师协会国际多媒体与博览会研讨会论文集》(Proceedings of the 2018 IEEE International Conference on Multimedia & Expo Workshops (ICMEW)),美国加利福尼亚州圣地亚哥(San Diego),2018年7月23 - 27日;第1 - 6页。
-
Chen, J.; Xu, Q.; Luo, L.; Wang, Y.; Wang, S. A robust method for automatic panoramic UAV image mosaic. Sensors 2019, 19, 1898. [CrossRef] [PubMed]
-
陈(Chen),J.;徐(Xu),Q.;罗(Luo),L.;王(Wang),Y.;王(Wang),S. 一种稳健的无人机全景图像自动拼接方法。《传感器》(Sensors)2019年,第19卷,第1898页。[CrossRef] [PubMed]
-
Bu, S.; Zhao, Y.; Wan, G.; Liu, Z. Map2DFusion: Real-time incremental UAV image mosaicing based on monocular SLAM. In Proceedings of the 2016 IEEE/RSJ Ineternational Conference on Intelligent Robots and Systems (IROS), Daejeon, Republic of Korea, 9-14 October 2016; pp. 4564-4571.
-
卜(Bu),S.;赵(Zhao),Y.;万(Wan),G.;刘(Liu),Z. Map2DFusion:基于单目同步定位与地图构建(SLAM)的无人机图像实时增量拼接。见《2016 年电气与电子工程师协会/日本机器人协会智能机器人与系统国际会议(IROS)论文集》,韩国大田,2016 年 10 月 9 - 14 日;第 4564 - 4571 页。
-
Zhang, F.; Yang, T.; Liu, L.F.; Liang, B.; Bai, Y.; Li, J. Image-only real-time incremental UAV image mosaic for multi-strip flight. IEEE Trans. Multimed. 2020, 23, 1410-1425. [CrossRef]
-
张(Zhang),F.;杨(Yang),T.;刘(Liu),L.F.;梁(Liang),B.;白(Bai),Y.;李(Li),J. 用于多航带飞行的仅图像实时增量无人机图像拼接。《电气与电子工程师协会多媒体汇刊》2020 年,23 卷,第 1410 - 1425 页。[参考文献交叉引用]
-
Ge, Y.; Wen, G.; Yang, X. A fast mosaicking method for small UAV image sequence using a small number of ground control points. In Proceedings of the 2016 8th International Conference on Intelligent Human-Machine Systems and Cybernetics (IHMSC), Hangzhou, China, 27-28 August 2016; Volume 2, pp. 90-94.
-
葛(Ge),Y.;文(Wen),G.;杨(Yang),X. 一种使用少量地面控制点的小型无人机图像序列快速拼接方法。见《2016 年第 8 届智能人机系统与控制论国际会议(IHMSC)论文集》,中国杭州,2016 年 8 月 27 - 28 日;第 2 卷,第 90 - 94 页。
-
Hartley, R.; Zisserman, A. Multiple View Geometry in Computer Vision 2; Cambridge University Press: New York, NY, USA, 2003.
-
哈特利(Hartley, R.);齐瑟曼(Zisserman, A.)。《计算机视觉中的多视图几何2》;剑桥大学出版社(Cambridge University Press):美国纽约,2003年。
-
Paul, J. Étude Comparative de la Distribution Florale dans une Portion des Alpes et du Jura. Bull. Société Vaud. Des Sci. Nat. 1901, XXXVII, 547-579. [CrossRef]
-
保罗(Paul, J.)。《阿尔卑斯山和汝拉山部分地区植物分布的比较研究》。《沃州自然科学学会公报》(Bull. Société Vaud. Des Sci. Nat.)1901年,第XXXVII卷,第547 - 579页。[参考文献交叉引用]
-
Li, C.; Xue, M.; Leng, X.; Lu, W. Analysis and Elimination on Aerial Recon Sequential Image Stitching Accumulative Error. J. Image Graph. 2008, 13, 814-819.
-
李(Li, C.);薛(Xue, M.);冷(Leng, X.);陆(Lu, W.)。《航空侦察序列图像拼接累积误差分析与消除》。《中国图象图形学报》(J. Image Graph.)2008年,第13卷,第814 - 819页。
-
Burt, P.J.; Adelson, E.H. A multiresolution spline with application to image mosaics. ACM Trans. Graph. (TOG) 1983, 2, 217-236. [CrossRef]
-
伯特(Burt, P.J.);阿德尔森(Adelson, E.H.)。《一种应用于图像拼接的多分辨率样条》。《ACM图形学汇刊》(ACM Trans. Graph. (TOG))1983年,第2卷,第217 - 236页。[参考文献交叉引用]
-
Burt, P.J.; Adelson, E.H. The Laplacian pyramid as a compact image code. In Readings in Computer Vision; Morgan Kaufmann: Burlington, MA, USA, 1987; pp. 671-679.
-
伯特(Burt, P.J.);阿德尔森(Adelson, E.H.)。《拉普拉斯金字塔作为一种紧凑的图像编码》。《计算机视觉读物》(Readings in Computer Vision);摩根·考夫曼出版社(Morgan Kaufmann):美国马萨诸塞州伯灵顿,1987年;第671 - 679页。
-
NPU Drone-Map Dataset. Available online: http://www.adv-ci.com/blog/source/npu-drone-map-dataset/ (accessed on 13 April 2023).
-
西北工业大学无人机地图数据集(NPU Drone-Map Dataset)。在线获取地址:http://www.adv-ci.com/blog/source/npu-drone-map-dataset/ (于2023年4月13日访问)。
-
Quickbird. Available online: http://ztmapper.com/nd.jsp?id=13#_jcp=1&_np=110_0 (accessed on 13 April 2023).
-
快鸟卫星影像(Quickbird)。在线获取地址:http://ztmapper.com/nd.jsp?id=13#_jcp=1&_np=110_0 (于2023年4月13日访问)。
-
Autopano. Available online: http://www.kolor.com/autopano-download/ (accessed on 13 April 2023).
-
自动全景拼接软件(Autopano)。在线获取地址:http://www.kolor.com/autopano-download/ (于2023年4月13日访问)。
-
Bradski, G. The openCV library. Dr. Dobb's J. Softw. Tools Prof. Program. 2000, 25, 120-123.
-
布拉德斯基(Bradski, G.)。OpenCV库。《Dr. Dobb's 软件工具与专业编程杂志》(Dr. Dobb's J. Softw. Tools Prof. Program)2000年,第25期,第120 - 123页。
Disclaimer/Publisher's Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content.
免责声明/出版商说明:所有出版物中包含的声明、观点和数据仅代表个别作者和贡献者的意见,而非MDPI和/或编辑的意见。MDPI和/或编辑对因内容中提及的任何想法、方法、说明或产品导致的人员伤害或财产损失不承担责任。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号