机器学习分类模型评价指标之ROC 曲线、 ROC 的 AUC 、 ROI 和 KS
前文回顾:
1. 基本指标
1.1 True Positive Rate(TPR)
\(TPR = \frac{TP}{TP+FN}\)
中文:真正率、灵敏度、召回率、查全率。显然这个就是查准率。
TPR 表示 “实际为正的样本”中,有多少预测是正确的。
TPR 越高越好,越高意味着模型对“正样本”的误判越少。
1.2 False Negative Rate(FNR)
\(FNR = \frac{FN}{TP+FN}\)
中文:假负率。
1.3 False Positive Rate(FPR)
\(FPR = \frac{FP}{TN+FP}\)
中文:假正率。
FPR 表示 “实际为负的样本”中,有多少预测是错误的。
FPR 越低越好,越低意味着模型对“负样本”的误判越少。
1.4 True Negative Rate(TNR)
\(FPR = \frac{TN}{TN+FP}\)
中文:真负率、特异度。
灵敏度(真正率)TPR 是正样本的召回率,特异度(真负率)TNR是负样本的召回率,而 假负率 \(FNR = 1−TPR\)、假正率 \(FPR = 1−TNR\),上述四个量都是针对单一类别的预测结果而言的,所以对整体样本是否均衡并不敏感。举个例子:
假设总样本中,90% 是正样本,10% 是负样本。在这种情况下我们如果使用 Accuracy 进行评价是不科学的,但是用 TPR 和 TNR 却是可以的,因为 TPR 只关注 90% 正样本中有多少是被预测正确的,而与那 10% 负样本毫无关系,同理,FPR 只关注 10% 负样本中有多少是被预测错误的,也与那 90% 正样本毫无关系。这样就避免了样本不平衡的问题。
2. Receiver Operating Characteristic Curve ( ROC 曲线)
中文:接受者操作特性曲线。
问题:前文的评价体系当中,并没有用上所有的可用信息;P 和 R ,都没有考虑 真负(TN)样本的影响。
假设现有模型对“深圳市孕产妇是否参与医疗保健”进行预测,预测的 P 为 98%,R 为100%。请问这个模型效果如何?是否可用?
答:很难说。因为仅通过 P 和 R ,我们不知道 假正(FP)和真负(TN)的样本量有多少,以及占比如何。实际上,2020年,深圳市的孕产妇保健覆盖率已经达到了98.44%。模型只要推测所有的孕妇都参加了医疗保健,就可以达到 98% 的 P,与 100% 的 R。但这个预测,对于我们而言,并没有带来任何的增量信息。
解决方案:同时使用 真正率(True Positive Rate)和假正率(False Positive Rate)两个指标,那么有什么好处?
- 可以考虑到整个混淆矩阵的信息。
- 不会受样本的不平衡程度的影响
条件概率来重写一下 TPR 和 FPR。假设 \(Y\) 为真实情况, \(\hat{Y}\) 为预测情况,则有:
\(TPR=\operatorname{Prob}(\hat{Y}=1 \mid Y=1)\)
\(FPR=\operatorname{Prob}(\hat{Y}=1 \mid Y=0)\)
TPR 和 FPR 的条件概率都是基于真实样本的,而且 TPR 只基于正样本,而 FPR 只基于负样本。这就使得 TPR 和 FPR 不会受 样本不平衡(Class Imbalance) 问题(即 负样本比正样本多很多(或者相反))的影响。
\(\text { Precision } = \operatorname{Prob}(Y = 1 \mid \hat{Y} = 1)\)
而 Precision 的条件概率是基于模型的预测结果,而不是基于真实样本。预测结果中\(\hat{Y}=1\) 混杂了正、负两种样本。
什么是 ROC 曲线?
ROC曲线是由 FPR 与 TPR 构成的曲线。该曲线最早应用于雷达信号检测领域,用于区分信号与噪声。后来人们将其用于评价模型的预测能力。与 P-R 曲线类似,通过设定不同的模型参数,模型的预测结果会对应不同 TPR 与 FPR。将不同的(FPR,TPR)构成的点绘制成曲线,就得到了 ROC 曲线。
优点:
- 不受样本类别不平衡问题的影响
- 与 P-R 曲线一样,不依赖阈值。如果仅使用ACC、P、R 作为评价指标进行模型对比时,都必须时基于某一个给定阈值的,对于不同的阈值,各模型的指标结果也会有所不同,这样就很难得出一个很置信的结果。
ROC 曲线的 横坐标为假正率(FPR),纵坐标为真正率(TPR)。如下图:
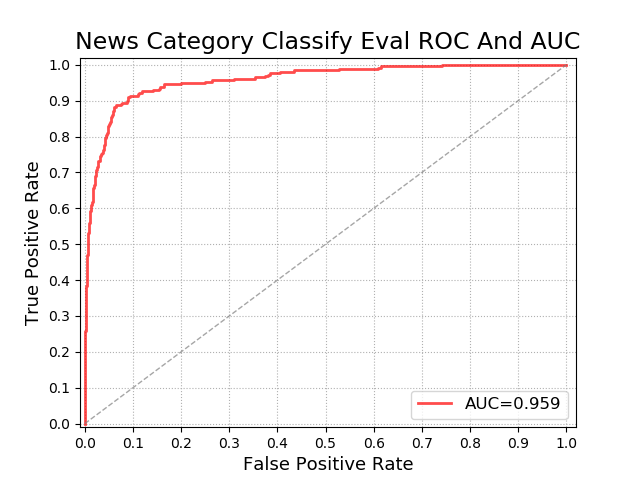
怎么生成一个给定模型的 ROC 曲线?
与 P-R 曲线一样,训练好一个模型后,给定不同的阈值生成 每个 阈值下的 假正率(FPR)和 真正率(TPR)。如下图:
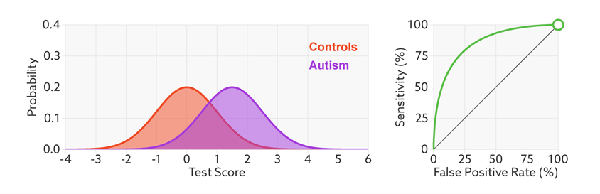
这里的 横坐标是表示不同阈值,纵坐标表示概率,左边的曲线是正负样本的概率密度函数。该图来自自闭症的研究,Controis 表示正常人,Autism 表示自闭症,其实就是正负样本的两个分布(橙色和紫色)。
灵敏度(TPR)和 FPR 都取决于所选的阈值。如果我们降低自闭症的阈值,就会有更多的自闭症患者检测呈阳性,敏感性也会增加。但这也意味着要抓住更多没有自闭症的人,从而增加误报率。
如何根据 ROC 判断不同模型的性能?
TPR 越高越好,FPR 越低越好。进行模型的性能比较时,与 P-R 曲线类似,若一个模型 A 的 ROC 曲线被另一个模型 B 的 ROC 曲线完全包住,则称B的性能优于A。若A和B的曲线发生了交叉,则谁的曲线下的面积大,谁的性能更优。曲线下的面积叫做 AUC。
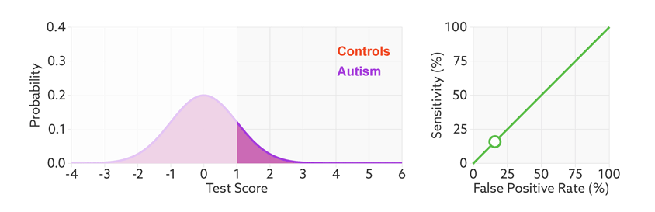
上图表示,在给定阈值下,不同的模型对于正负样本的分类情况,分类效果越好,那么 TPR 越高, FPR 越低,因此该 点 越靠近 (0,1) 坐标。
为什么样本不平衡问题不影响 ROC 曲线?
上文已经解释了 样本不平衡问题 不影响 TPR 和 FPR,那么也就不会影响 ROC 曲线。
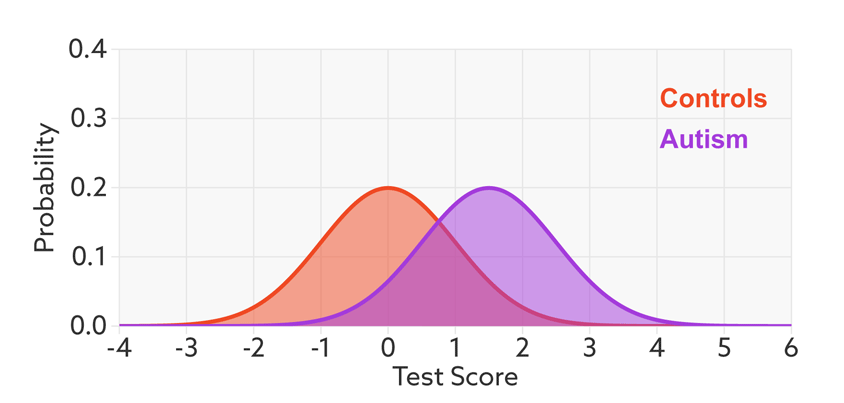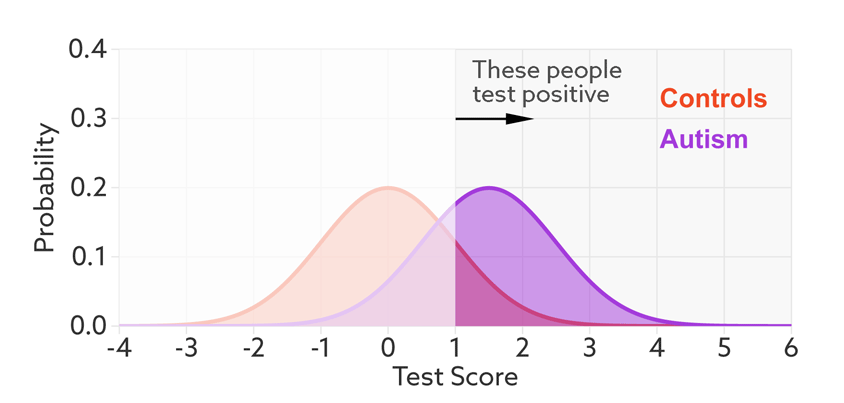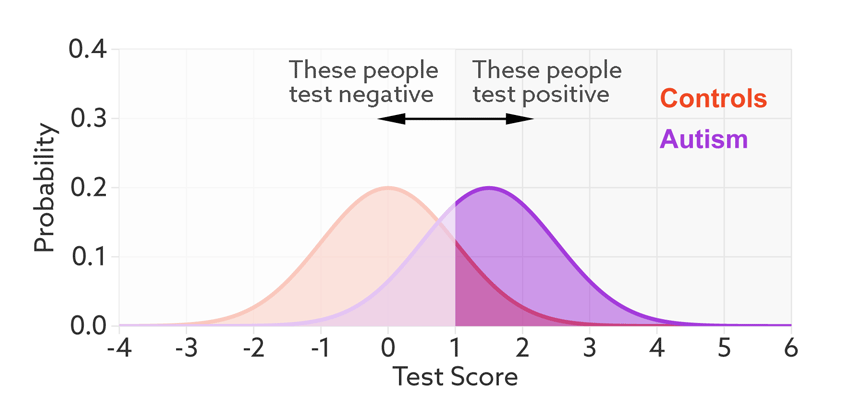
碰撞曲线: 在假设测试中,自闭症患者(紫色)和正常人(橙色)的分数分布重叠。
该文章是说明对人进行分类是否有自闭症。下面就是模型输出的 Test Score,橙色分布是 正常人概率密度函数,紫色是 自闭症的概率密度函数。二者是有一定重合的。我们给定一个阈值,大于该阈值的是自闭症患者(positive),小于的是正常人(Negative)。
给定了阈值我们就可以得到 TPR 和 FPR。
然而,问题是,TPR 和 FPR 只有在我们一开始就知道谁患有自闭症谁没有的情况下才有意义。例如,TPR 告诉我们,模型在多大程度上识别出我们已知的自闭症患者。
在现实生活中,我们通常事先不知道病人的真实诊断——这就是需要进行检测是否是自闭症的原因。
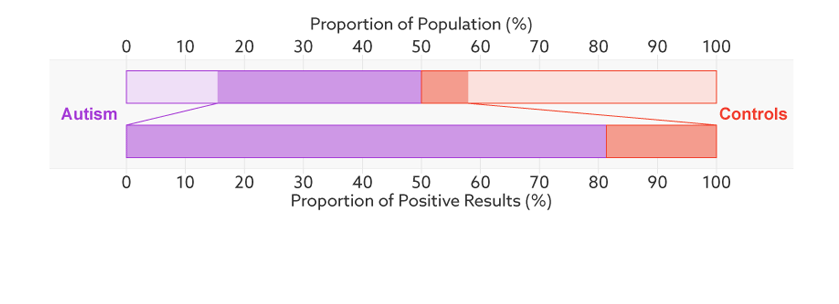
上面的条表示,总的样本中,模型预测的自闭症占样本总数的百分比。
下面的条表示,模型预测为自闭症的样本中,多少是真的有自闭症(这里是 81%),其实就是 Precision。
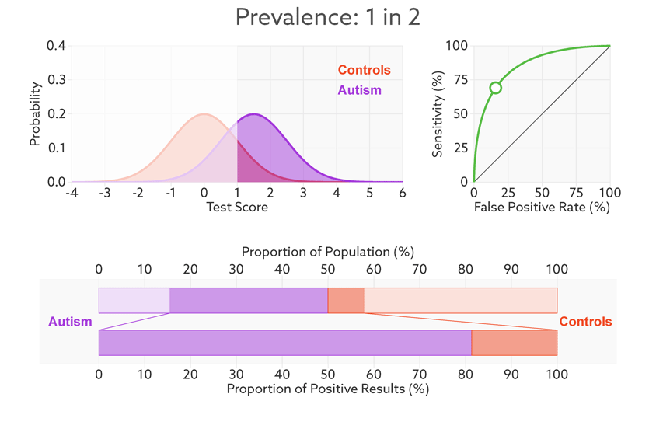
上图的意思是,实验时候测试集一半的人实际都是自闭症(1 in 2),那么这时候 这些检测为自闭症阳性的人中有 81% 确实有自闭症(TP),19% 的人被误分类为 自闭症(FP)。而当测试机变为 68 个人中有一个自闭症时,模型预测为自闭症阳性的人中有 6% 的人确实有自闭症,那么 94% 的人就被误分类为 自闭症(FP)。下面的条其实就表示 Precision 由 81% 变成了 6%。
3. ROC 的 AUC
ROC 的 AUC 就是它曲线下面的面积。
AUC的值介于0.5到1.0之间。当AUC等于0.5时(连接对角线,它的面积正好是0.5),整个模型等价于一个随机分类器。AUC的面积越大,模型的整体表现越好。
另一种解读
AUC 对所有可能的分类阈值的效果进行综合衡量。首先AUC值是一个概率值,可以理解为随机挑选一个正样本以及一个负样本,分类器判定正样本分值高于负样本分值的概率就是AUC值。简言之,AUC 值越大,当前的分类算法越有可能将正样本分值高于负样本分值,即能够更好的分类。

图 . 预测按逻辑回归分数以升序排列。
ROC 的 AUC 的优点
- AUC是尺度不变的。它衡量的是预测的排名,而不是预测的绝对值。
- AUC是分类阈值不变的。它衡量模型预测的质量,而不考虑选择什么分类阈值。
ROC 的 AUC 的局限
然而,这两个原因都有需要注意的地方,这可能会限制AUC在某些用例中的作用:
- 尺度不变性并不总是我们想要的。例如,有时我们确实需要良好 校准(calibrated) 概率输出,而 AUC 不会告诉我们这一点。
- 分类阈值不变性并不总是理想的。在 false negatives vs. false positives 的代价存在很大差异的情况下,最小化一种分类错误可能至关重要。例如,在进行垃圾邮件检测时,你可能希望优先最小化 false positives (即使这会导致 false negatives 的显著增加)。对于这种类型的优化,AUC 不是一个有用的指标。
4. P-R 曲线和 ROC 曲线的关系及如何选择?
PR 和 ROC 可以相互转换: 参考
Theorem 3.1. For a given dataset of positive and negative examples, there exists a one-to-one correspon- dence between a curve in ROC space and a curve in PR space, such that the curves contain exactly the same confusion matrices, if Recall != 0
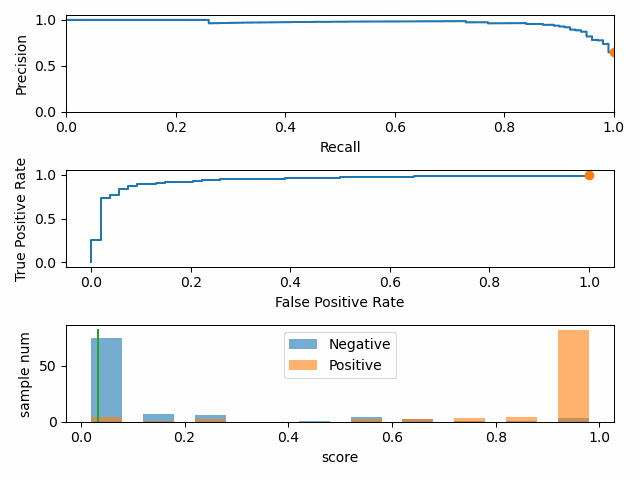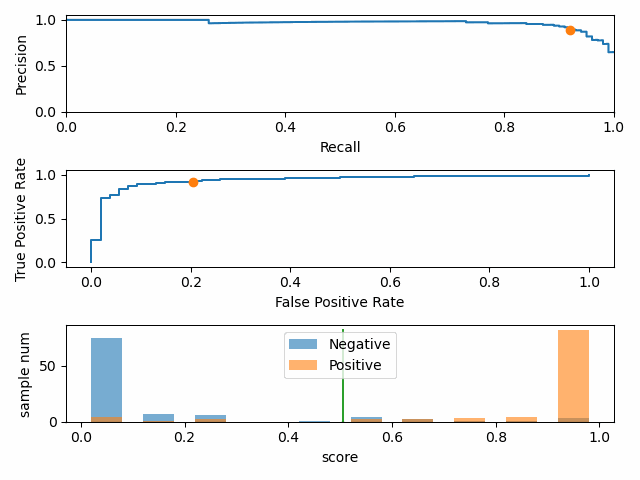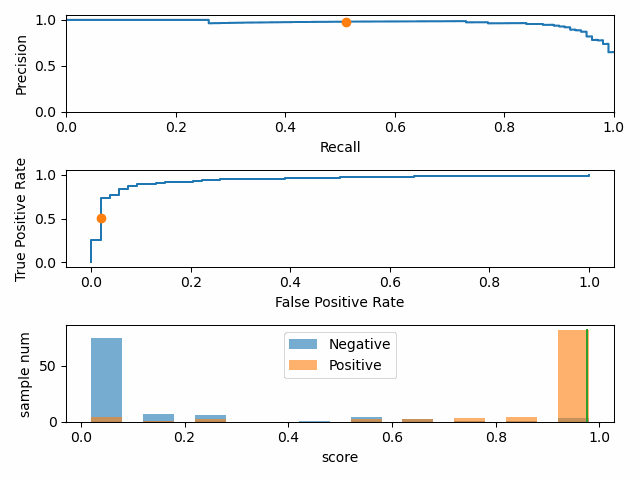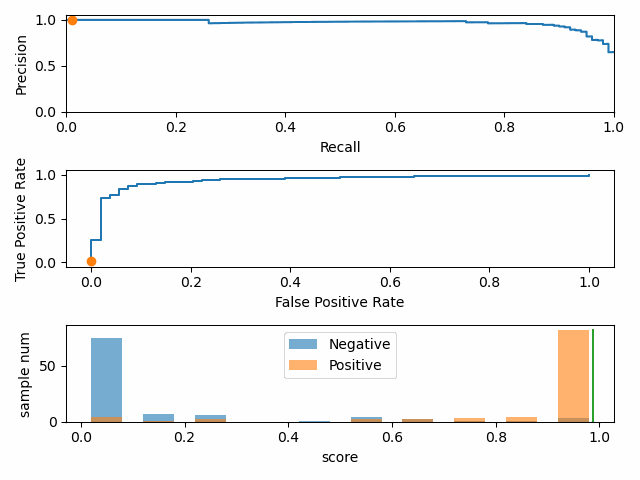
正负样本比例变化时,P-R 曲线变化剧烈,而 ROC 曲线变化很小。
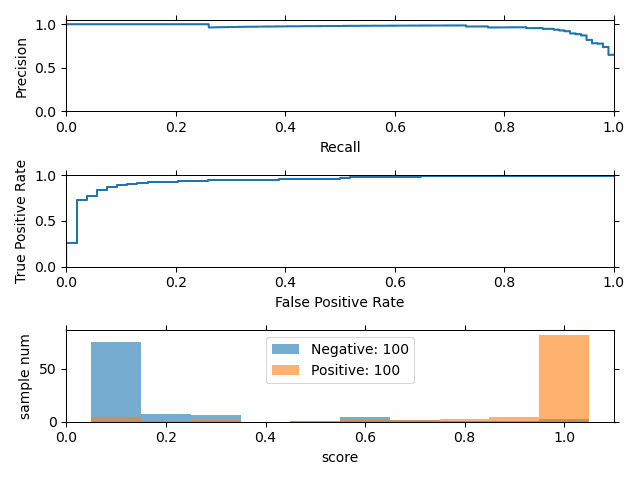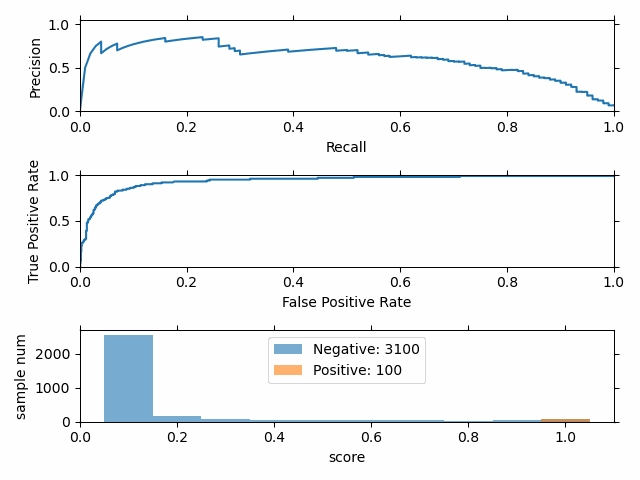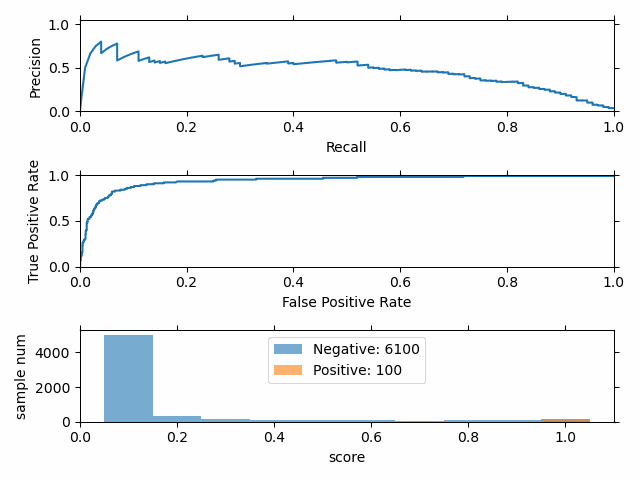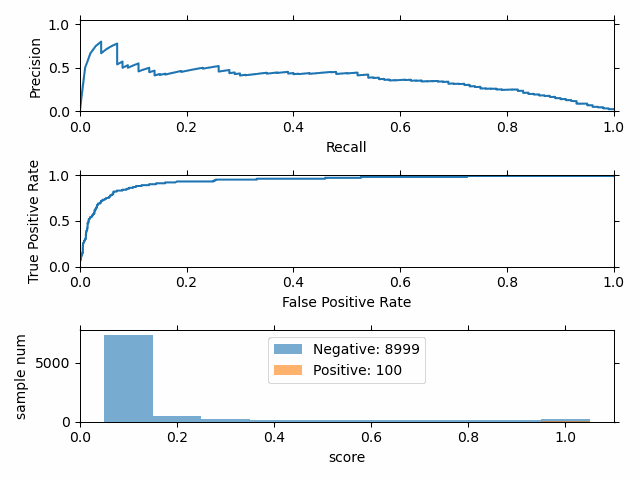
选择 P-R 曲线 还是 ROC 曲线?
- ROC曲线由于兼顾正例与负例,所以适用于评估分类器的整体性能,相比而言PR曲线完全聚焦于正例。
- 如果有多份数据且存在不同的类别分布,比如信用卡欺诈问题中每个月正例和负例的比例可能都不相同,这时候如果只想单纯地比较分类器的性能且剔除类别分布改变的影响,则ROC曲线比较适合,因为类别分布改变可能使得PR曲线发生变化时好时坏,这种时候难以进行模型比较;反之,如果想测试不同类别分布下对分类器的性能的影响,则PR曲线比较适合。
- 如果想要评估在相同的类别分布下正例的预测情况,则宜选PR曲线。
- 类别不平衡问题中,ROC曲线通常会给出一个乐观的效果估计,所以大部分时候还是PR曲线更好。
- 最后可以根据具体的应用,在曲线上找到最优的点,得到相对应的precision,recall,f1 score等指标,去调整模型的阈值,从而得到一个符合具体应用的模型。
目标检测的模型评估中为什么不使用 ROC 曲线,而是使用的 P-R 曲线?
首先如果想要画一条ROC曲线,我们必须要计算True Positive Rate(TPR)和False Positive Rate(FPR),其中FPR=FP/(FP+TN),问题就出在其中的TN上,TN 表示的是一次正确的误测,在目标检测中,每一个图像里面都有无数的检测框,其中很多检测框本就不应该被检测出来,因此 TN 就是所有没有检测出目标的检测框,这不可能算的出来的,所以算不出来 TN就算不出FPR也就没有ROC曲线。
True Negative (TN): Does not apply. It would represent a corrected misdetection. In the object detection task there are many possible bounding boxes that should not be detected within an image. Thus, TN would be all possible bounding boxes that were corrrectly not detected (so many possible boxes within an image). That's why it is not used by the metrics.
no TN, no FPR, no ROC curve!
参考:
- https://stats.stackexchange.com/questions/440776/how-to-calculate-tpr-and-fpr-and-plot-roc-curves-for-object-detection
- https://blog.csdn.net/qq_38216057/article/details/125539083?spm=1001.2014.3001.5502
5. Return on Investment(ROI)
中文:投资回报率
假设现有模型C对某生产线生产的产品是否故障(如果故障则为P)进行预估:
● 在参数组设定为 i 时,模型的TPR为40%,FPR为2%,(0.4,0.2)和(0,1)间的距离为0.36。
● 在参数组设定为 j 时,模型的TPR为50%,FPR为4%,(0.4,0.2)和(0,1)间的距离为0.25。请问哪组参数的表现更好,应该采用哪组参数?
答:很难说。因为我们不知道FN和FP对于我们而言意味着什么。实际上对于该类的产品故障而言,如果漏检(FN),产品上市则某次故障会给公司带来的损失是5000元;而如果对负样本错检(FP),只需要二次重检查,成本是5元。PS:产品的平均故障率大约在百万分之十二左右。
那么如何综合考虑混沌矩阵中4类样本对应的影响,进而对模型的参数进行选择呢?
在此引入 ROI 的概念来解决这个问题。
投资回报率(ROI)是指通过模型应用成本与收益的比值;形式化而言: \(ROI = \frac {Profit} {Cost}\) 。
我们可以通过比较不同参数对应模型的 ROI,来确定最优的参数。以上述的故障率检测为例:
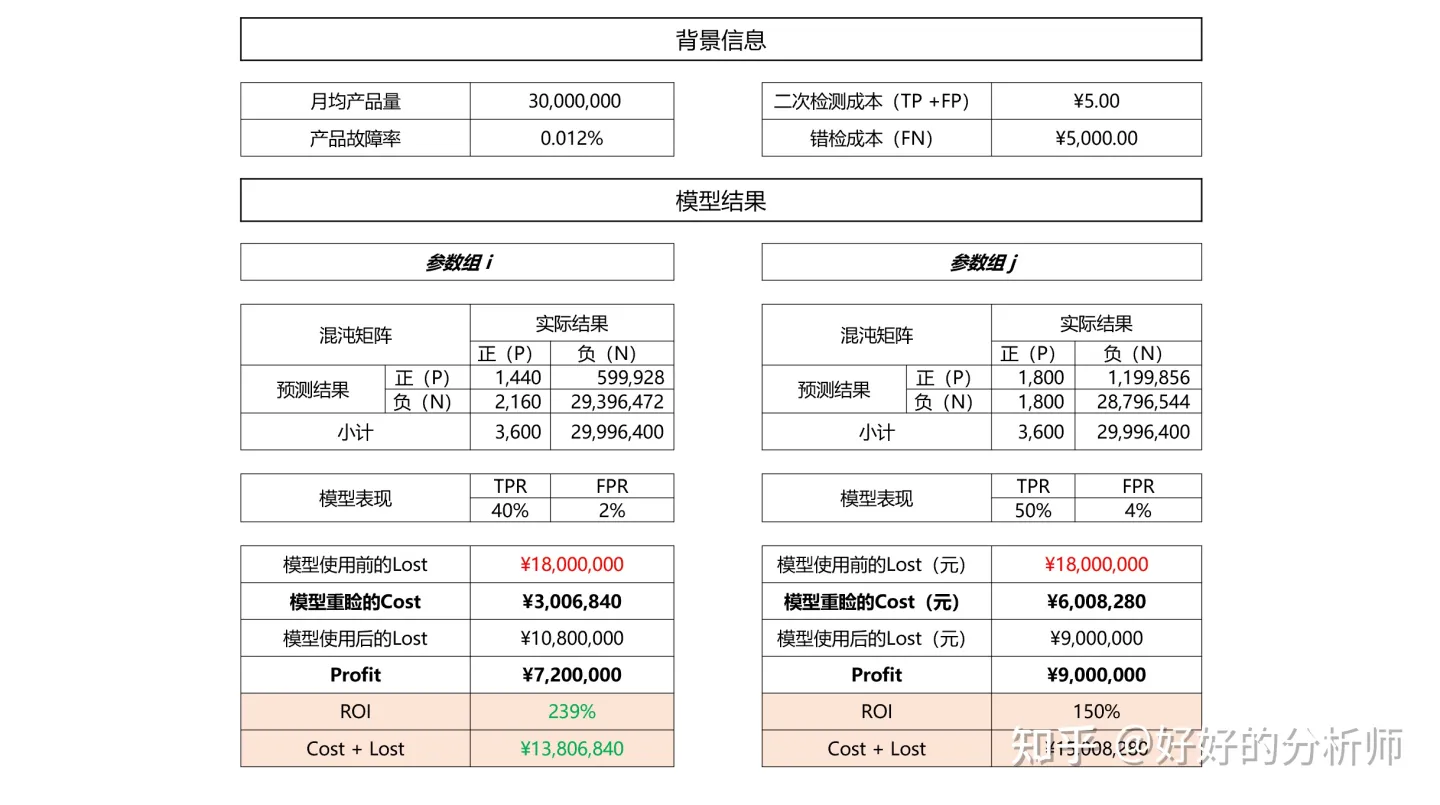
根据图9的推演可得,从ROI的视角出发,参数组 i 要优于参数组 j 。
所以说在某些情况下,即使我们预测出1个正样本的代价,是要误测416个负样本,每个月的花费超过300万,我们依旧认为这是一个好模型。
6. Kolmogorov-Smirnov(KS)
KS 曲线是两条线,其横轴是 “阈值”(区间序号,按概率排序的等份),纵轴是 TPR(上面那条)与 FPR(下面那条)的值,值范围[0,1] 。两条曲线之间之间相距最远的地方对应的阈值,就是最能划分模型的阈值。
KS 取的是TPR和FPR差值的最大值,能够找到一个最优的阈值。
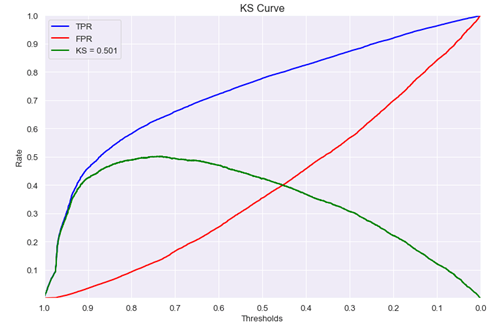
- KS值<0.2,一般认为模型没有区分能力。
- KS值[0.2,0.3],模型具有一定区分能力,勉强可以接受
- KS值[0.3,0.5],模型具有较强的区分能力。
- KS值大于0.75,往往表示模型有异常。
KS 曲线表示模型将正负样本区分开的能力,一般应用于金融风控领域。
随着阈值从大逐渐的变小,TPR的提升速度高于FPR的提升速度,直到一个临界阈值threshold,之后TPR提升速度低于FPR,这个临界threshold便是最佳阈值。在前期TPR越快提升,模型效果越好;反之,FPR越快提升,模型效果就越差。
参考
- https://www.zhihu.com/question/321998017/answer/2303096310
- https://laurenoakdenrayner.com/2018/01/07/the-philosophical-argument-for-using-roc-curves/
- https://www.spectrumnews.org/opinion/viewpoint/quest-autism-biomarkers-faces-steep-statistical-challenges/
- https://machinelearningmastery.com/roc-curves-and-precision-recall-curves-for-imbalanced-classification/
- https://developers.google.com/machine-learning/crash-course/classification/roc-and-auc
- https://zhuanlan.zhihu.com/p/36305931
- https://www.cnblogs.com/gczr/p/10354646.html
- https://www.cnblogs.com/eilearn/p/9071440.html
新知识:如何校准概率?
https://machinelearningmastery.com/probability-calibration-for-imbalanced-classification/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号