AWK学习日记
AWK是一种处理文本文件的语言,是一个强大的文本分析工具。
工作流程:
AWK遵循一个简单的工作流程:读取-》执行-》重复。 ① awk从输入流(文件,管道,标准输入)读取一行,并将其存储在存储器(内存)中。 ② 所有的awk命令一次提交输入。默认情况下awk执行命令每一行,但我们可以通过提供的模式限制。 ③ 重复以上过程,一直到这个文件被处理完成。
程序结构:
BEGIN 块
以下是BEGIN块语法:
BEGIN {awk-commands}
在BEGIN块被在程序启动时执行,且只执行一次。这是一个很好的初始化变量的地方。 BEGIN是AWK关键字,因此它必须是大写。请注意,这个块是可选的。
Body块
以下是主体(Body)块的语法:
/pattern/ {awk-commands}
主体块适用于AWK的每个输入行命令。默认情况下AWK执行每一行命令,但可以通过提供的模式限制。请注意,没有主体块的关键字。
END 块
以下是END块的语法:
END {awk-commands}
END块被在程序结束时执行。END是AWK关键字,因此它必须是大写。请注意,此块也是可选的
基本语法:
awk [options] file .....
awk [oprions] -f file ....
file可以是一个包含awk命令的文件
例如:
awk '{print}' test.txt 命令为列出test.txt的内容
可以将{print}写入文件test.awk
执行 awk -f test.awk test.txt
效果相同。
AWK标准选项:
-v 选项
此选项分配一个只的变量,允许程序执行前分配。
awk -v name=ck 'BEGIN {printf "name=%s\n",name}'
得到结果 name=ck
--dump-variables[=file] 选项
它打印全局变量和最终值到文件的一个排序列表。默认的文件是awkvars.out。
awk -dump-variables '' cat awkvars.out
--help 选项
此选项将在标准输出的帮助信息。
下面开始实例操作:
以netstat命令中提取了如下信息作为用例:

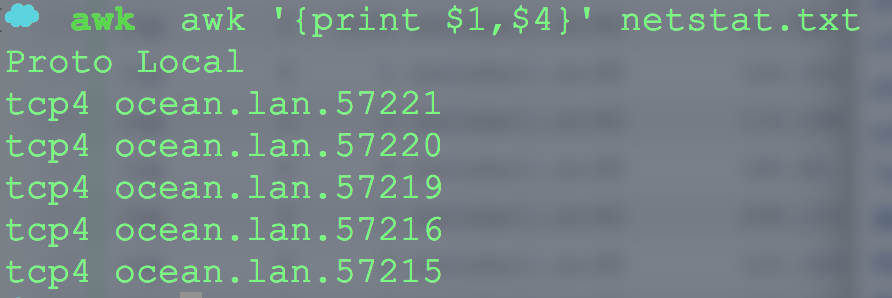
下面是最简单最常用的awk示例,其输出第一列和第四列,
其中单引号中的被大括号括着的就是awk的语句,注意,其职能被单引号包含。
其中$1...$n表示第几列。$0表示整个行
过滤记录
我们再来看看如何过滤记录(下面过滤条件为:第三列的值为0 && 第6列的值为LISTEN)

其中的“==”为比较运算符。其他比较运算符:!=, >, <, >=, <=

如果我们需要表头的话,我们可以引入内建变量NR:

内建变量
$0 当前记录(这个变量存放着整个行的内容)
$1~$n 当前记录得第n个字段,字段由FS分割
FS 输入字段分隔符 默认是空格或者Tab
NF 当前记录中的字段个数,就是有多少列
NR 记录读出的记录数,就是行号,从1开始如果有多个文件,这个值也不断累加。
FNR 当前记录数,与NR不同的是这个值会是各个文件自己的行号
RS 输入的记录分隔符,默认是换行符
OFS 输出字段分隔符,默认空格
ORS 输出记录分隔符,默认为换行符
FILENAME 当前输入文件的名字
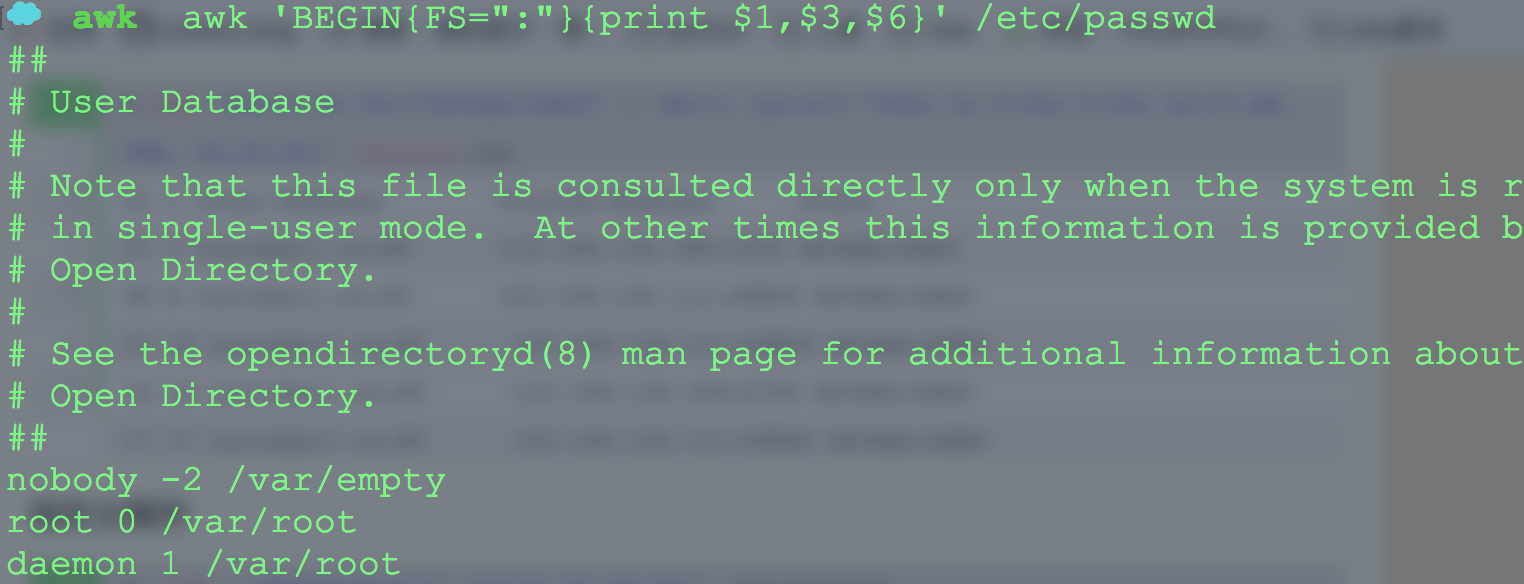
上面的命令等价于:awk -F: '{print $1,$3,$6}' /etc/passwd
如果要制定多个分隔符:awk -F '[;:]'
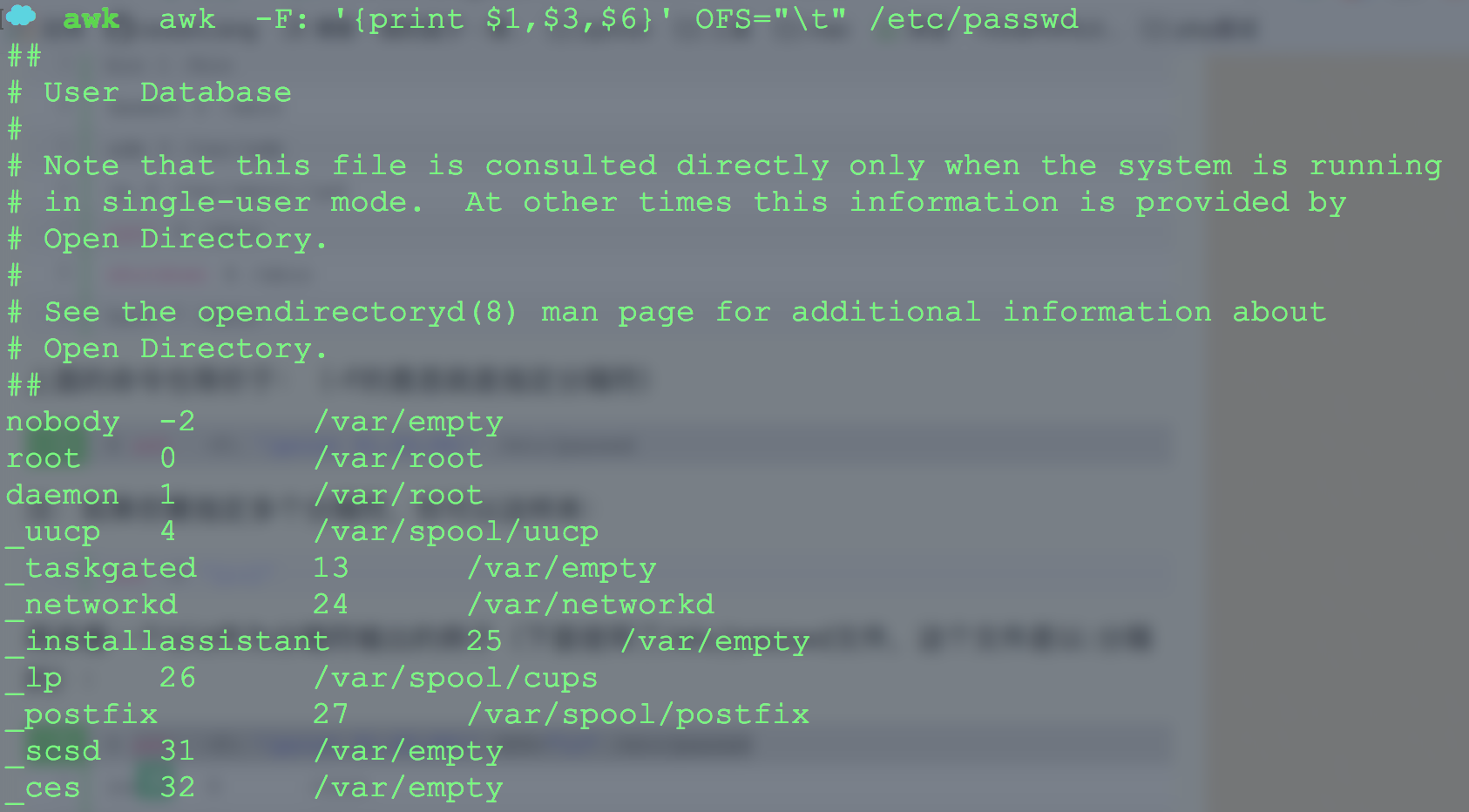
再来看一个以\t作为分隔符输出的例子(下面使用了/etc/passwd文件,这个文件是以:分隔的):
转自:https://www.cnblogs.com/chenshoubiao/p/4773808.html


 浙公网安备 33010602011771号
浙公网安备 33010602011771号