R之data.table -melt/dcast(数据合并和拆分)
R之data.table -melt/dcast(数据拆分和合并)
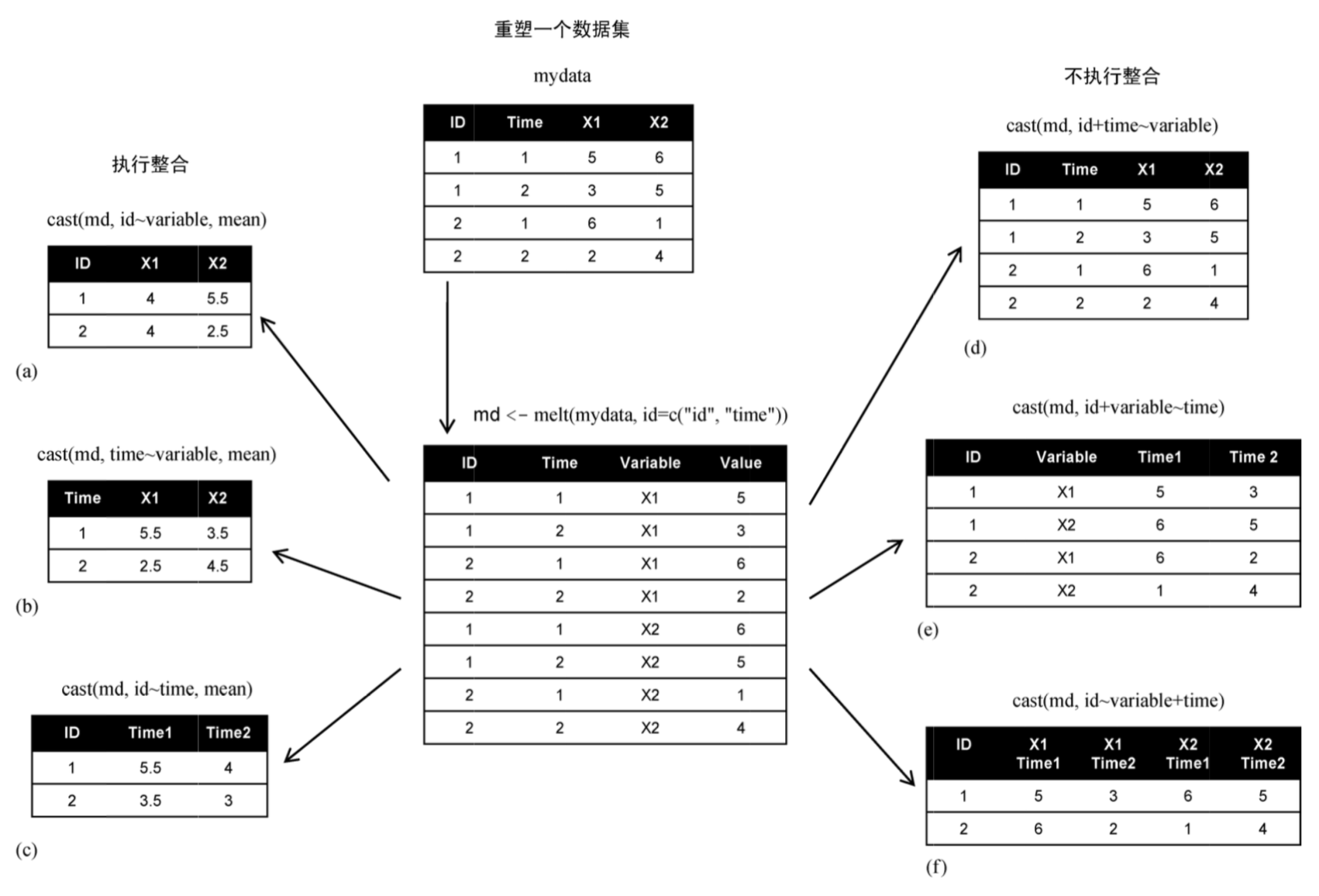
写在前面:数据整形的过程确实和揉面团有些类似,先将数据通过melt()函数将数据揉开,然后再通过dcast()函数将数据重塑成想要的形状
reshape2包:
melt-把宽格式数据转化成长格式。
cast-把长格式数据转化成宽格式。(dcast-输出时返回一个数据框。acast-输出时返回一个向量/矩阵/数组。)
注:melt是数据融合的意思,它做的工作其实就是把数据由“宽”转“长”。
cast 函数的作用除了还原数据外,还可以对数据进行整合。
dcast 输出数据框。公式的左边每个变量都会作为结果中的一列,而右边的变量被当成因子类型,每个水平都会在结果中产生一列。
tidyr包:
gather-把宽度较大的数据转换成一个更长的形式,它类比于从reshape2包中融合函数的功能
spread-把长的数据转换成一个更宽的形式,它类比于从reshape2包中铸造函数的功能。
data.table包:
data.table的函数melt 和dcast 是增强包reshape2里同名函数的扩展
library(data.table)
ID <- c(NA,1,2,2)
Time <- c(1,2,NA,1)
X1 <- c(5,3,NA,2)
X2 <- c(NA,5,1,4)
mydata <- data.table(ID,Time,X1,X2)
mydata
## ID Time X1 X2
## 1: NA 1 5 NA
## 2: 1 2 3 5
## 3: 2 NA NA 1
## 4: 2 1 2 4
md <- melt(mydata, id=c("ID","Time")) #or md <- melt(mydata, id=1:2)
#melt以使每一行都是一个唯一的标识符-变量组合
md #将第一列作为id列,其他列全部融合就可以了
## ID Time variable value
## 1: NA 1 X1 5
## 2: 1 2 X1 3
## 3: 2 NA X1 NA
## 4: 2 1 X1 2
## 5: NA 1 X2 NA
## 6: 1 2 X2 5
## 7: 2 NA X2 1
## 8: 2 1 X2 4
将变量"variable",和"value"揉合在一起,结果产生了新的两列,一列是变量variable,指代是哪个揉合变量,另外一列是取值value,即变量对应的值。我们也称这样逐行排列的方式称为长数据格式
melt:数据集的融合是将它重构为这样一种格式:每个测量变量独占一行,行中带有要唯一确定这个测量所需的标识符变量。
str(mydata)
## Classes 'data.table' and 'data.frame': 4 obs. of 4 variables:
## $ ID : num NA 1 2 2
## $ Time: num 1 2 NA 1
## $ X1 : num 5 3 NA 2
## $ X2 : num NA 5 1 4
## - attr(*, ".internal.selfref")=<externalptr>
str(md)
## Classes 'data.table' and 'data.frame': 8 obs. of 4 variables:
## $ ID : num NA 1 2 2 NA 1 2 2
## $ Time : num 1 2 NA 1 1 2 NA 1
## $ variable: Factor w/ 2 levels "X1","X2": 1 1 1 1 2 2 2 2
## $ value : num 5 3 NA 2 NA 5 1 4
## - attr(*, ".internal.selfref")=<externalptr>
setcolorder(md,c("ID","variable","Time","value")) ##setcolorder()可以用来修改列的顺序。
md
## ID variable Time value
## 1: NA X1 1 5
## 2: 1 X1 2 3
## 3: 2 X1 NA NA
## 4: 2 X1 1 2
## 5: NA X2 1 NA
## 6: 1 X2 2 5
## 7: 2 X2 NA 1
## 8: 2 X2 1 4
mdr <- melt(mydata, id=c("ID","Time"),variable.name="Xzl",value.name="Vzl",na.rm = TRUE) #variable.name定义变量名
mdr
## ID Time Xzl Vzl
## 1: NA 1 X1 5
## 2: 1 2 X1 3
## 3: 2 1 X1 2
## 4: 1 2 X2 5
## 5: 2 NA X2 1
## 6: 2 1 X2 4
mdr1 <- melt(mydata, id=c("ID","Time"),variable.name="Xzl",value.name="Vzl",measure.vars=c("X1"),na.rm = TRUE) #measure.vars筛选
mdr1
## ID Time Xzl Vzl
## 1: NA 1 X1 5
## 2: 1 2 X1 3
## 3: 2 1 X1 2
md[Time==1]
## ID variable Time value
## 1: NA X1 1 5
## 2: 2 X1 1 2
## 3: NA X2 1 NA
## 4: 2 X2 1 4
md[Time==2]
## ID variable Time value
## 1: 1 X1 2 3
## 2: 1 X2 2 5
#执行整合
# rowvar1 + rowvar2 + ... ~ colvar1 + colvar2 + ...
# 在这个公式中,rowvar1 + rowvar2 + ... 定义了要划掉的变量集合,以确定各行的内容,而colvar1 + colvar2 + ... 则定义了要划掉的、确定各列内容的变量集合。
newmd<- dcast(md, ID~variable, mean)
newmd
## ID X1 X2
## 1: 1 3 5.0
## 2: 2 NA 2.5
## 3: NA 5 NA
newmd2<- dcast(md, ID+variable~Time)
newmd2
## ID variable 1 2 NA
## 1: 1 X1 NA 3 NA
## 2: 1 X2 NA 5 NA
## 3: 2 X1 2 NA NA
## 4: 2 X2 4 NA 1
## 5: NA X1 5 NA NA
## 6: NA X2 NA NA NA
#ID+variable~Time 使用Time对(ID,variable)分组 Time:1,2,NA 类似excel的数据透析
newmd3<- dcast(md, ID~variable+Time)
newmd3 #variable:X1,X2 Time:1,2,NA 类似excel的数据透析
## ID X1_1 X1_2 X1_NA X2_1 X2_2 X2_NA
## 1: 1 NA 3 NA NA 5 NA
## 2: 2 2 NA NA 4 NA 1
## 3: NA 5 NA NA NA NA NA

 浙公网安备 33010602011771号
浙公网安备 33010602011771号