

3.1 Spark概述
一、Spark简介
1.Spark的特点



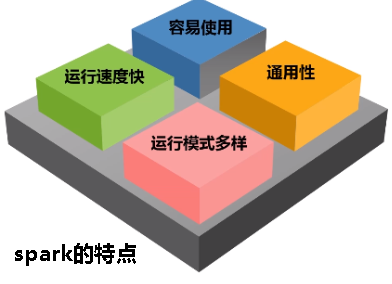
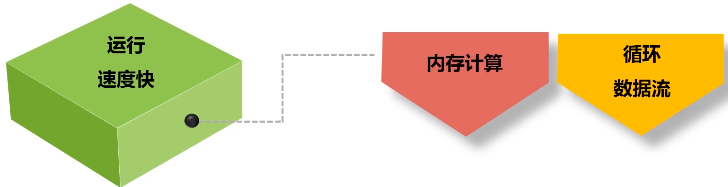
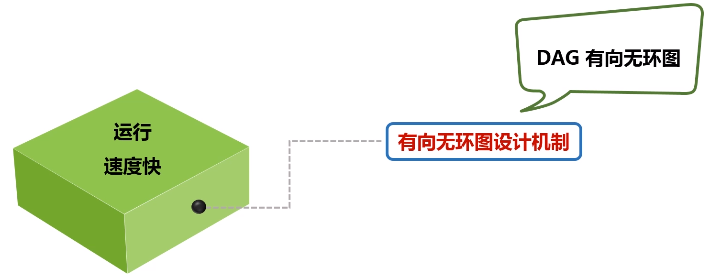
特点1:运行速度快(内存计算,循环数据流、有向无环图设计机制)
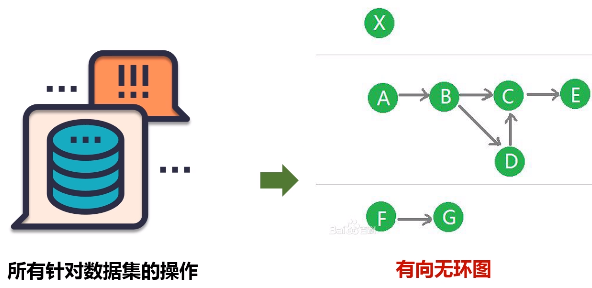
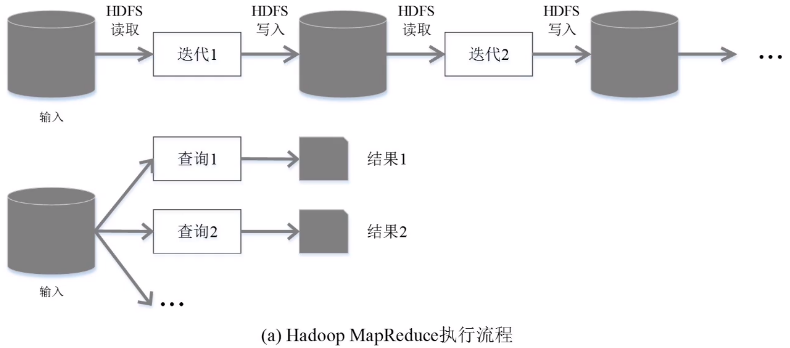
把所有针对数据集的操作转换成一张有向无环图,整个执行引擎调度都是基于这个有向无环图,对这个有向无环图的后期操作,会进行拆分,分成不同的阶段,每一阶段分成不同的任务,再去分发到不同的机器上去执行。


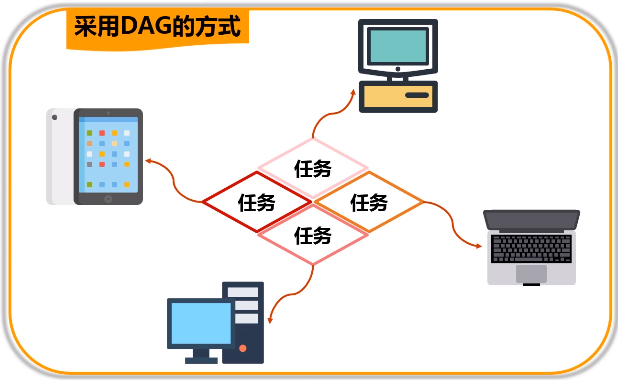
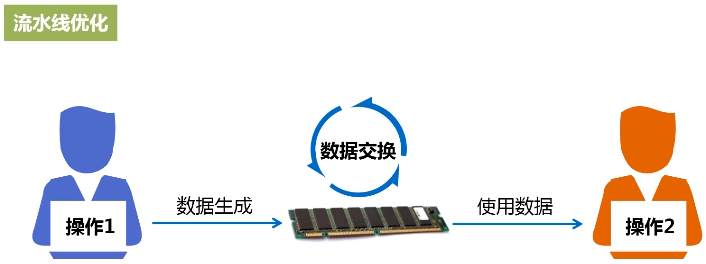
它可以采用特定的方式对它整个里面执行的过程进行优化,比如流水线优化
特点2:容易使用,Scala可通过spark Shell进行交互式编程


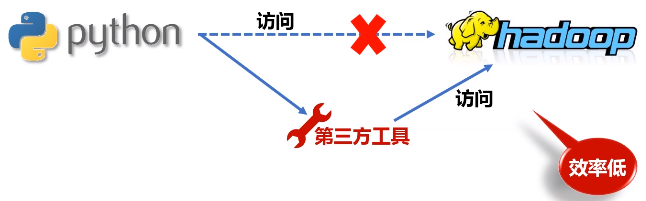
特点3:通用性(完整的解决方案,技术软件栈)

特点4:运行模式多样
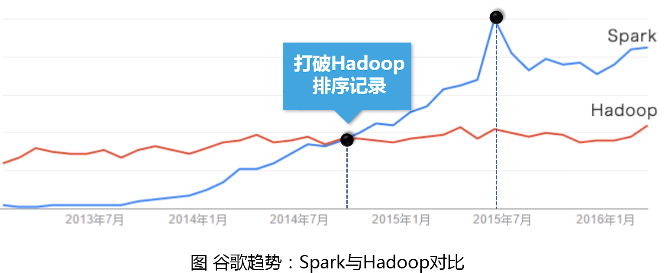

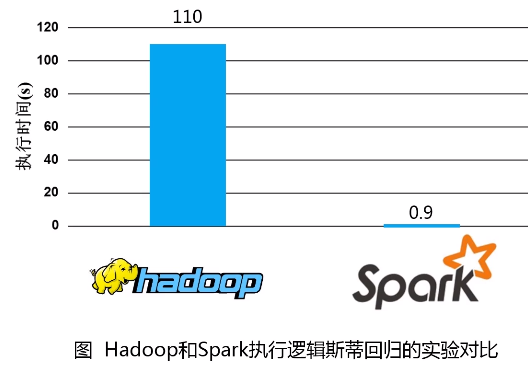
2.Spark与Hadoop的对比

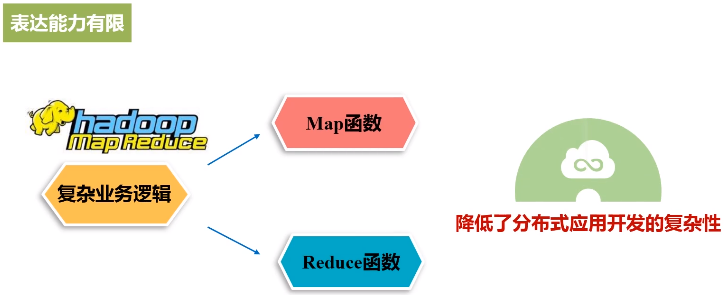
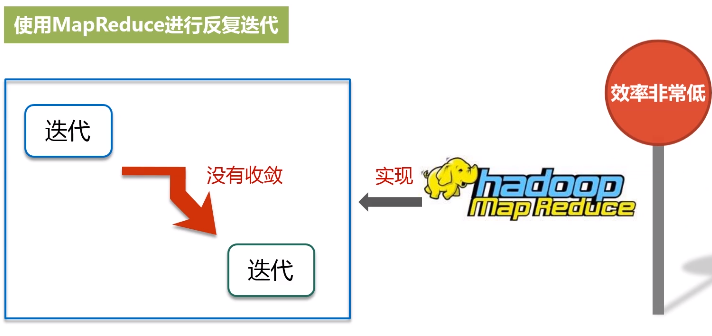
MapReduce的缺陷:
(1)表达能力有限
(2)磁盘开销大

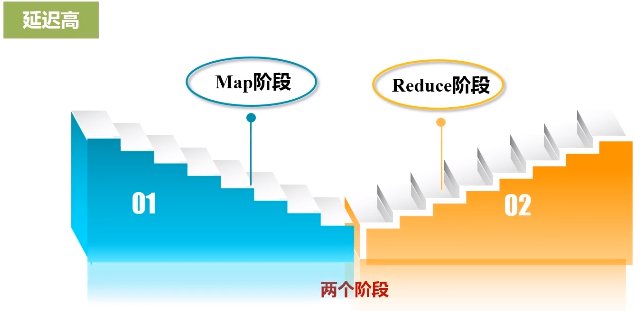
(3)延迟高
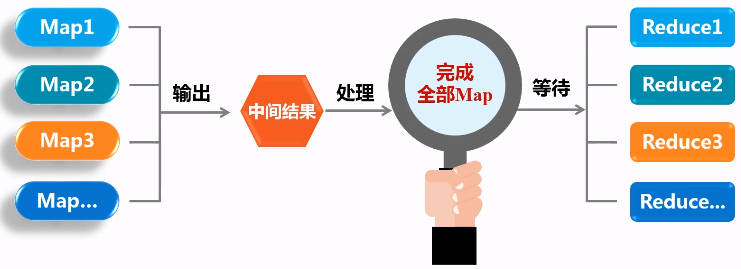
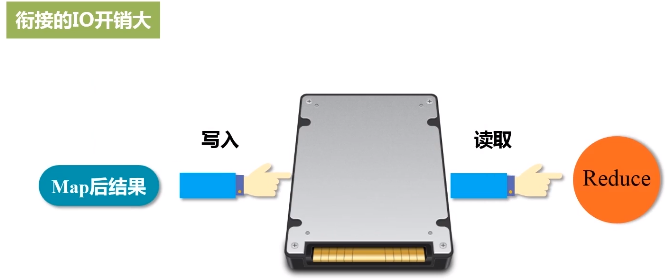
(4)衔接的IO开销大
3.Spark的优点
(1)操作类型更多(表达能力更强)

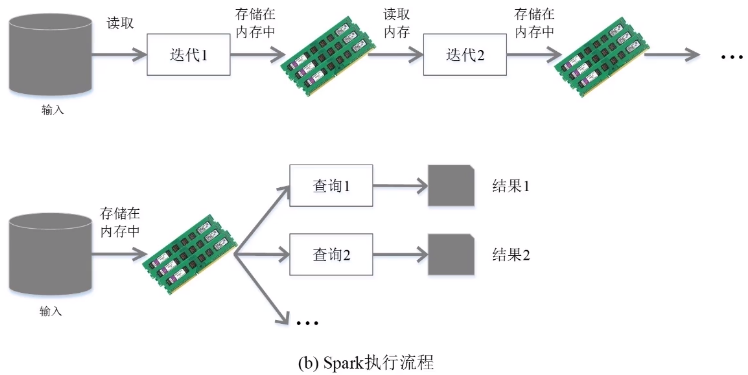
(2)内存计算(运行速率提升,高效提高迭代运算)


(3)避免数据落地
数据不写入磁盘;
形成一个有向无环图,让有向无环图当中的一些操作之间形成流水线优化
二、Spark生态系统
1.为什么Spark要建立生态系统?
三种应用场景需求







Spark2.0之后新增了Structured Streaming组件,
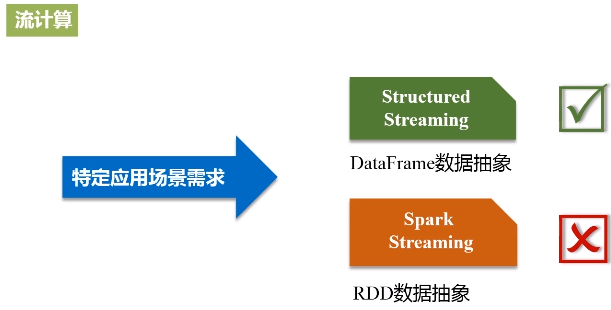




Mahout现在是基于Spark的机器学习算法库

 浙公网安备 33010602011771号
浙公网安备 33010602011771号