要点:socket的数据传输,ssl的封装,Queue, Pool,Thread
数据展示:
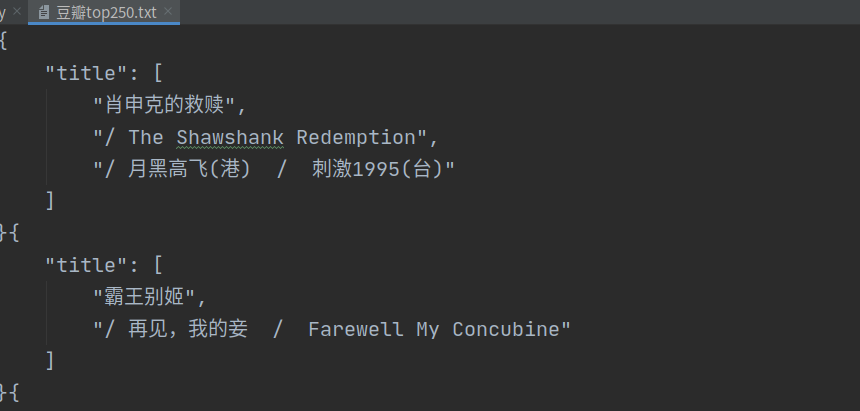
代码:
import socket
import ssl
from lxml import etree
from queue import Queue
import json
from threading import Thread
from multiprocessing.dummy import Pool
class DoubanTop250(object):
def __init__(self):
self.base_url = "https://movie.douban.com/top250?start={}&filter="
self.url_queue = Queue()
self.data_queue = Queue()
self.item_queue = Queue()
def construct_url(self):
for i in range(10):
url = self.base_url.format(i * 25)
self.url_queue.put(url)
def get_requests(self):
while self.url_queue.not_empty:
url = self.url_queue.get()
protocol = url.split("://")[0]
split_index = url.split("://")[1].find("/")
host = url.split('://')[1][:split_index]
path = url.split("://")[1][split_index:]
if protocol == "https":
client = ssl.wrap_socket(socket.socket())
port = 443
else:
client = socket.socket()
port = 80
# 连接服务器
client.connect((host, port))
# 发送请求
header = """GET {} HTTP/1.1\r\nhost:{}\r\n\r\n""".format(path, host)
client.send(header.encode('utf8'))
data = b''
while True:
recv_data = client.recv(1024)
data += recv_data
if len(recv_data) == 0:
break
self.data_queue.put(data.decode("utf8"))
self.url_queue.task_done()
def parse_data(self):
while self.data_queue.not_empty:
html_str = etree.HTML(self.data_queue.get())
li_list = html_str.xpath('//ol[contains(@class, "grid_view")]/li')
item_list = list()
for li in li_list:
item = dict()
title = li.xpath('.//div[contains(@class,"hd")]/a/span/text()')
item['title'] = [t.strip() for t in title] if title else None
self.item_queue.put(item)
self.data_queue.task_done()
def save_to_file(self):
while self.item_queue.not_empty:
item = self.item_queue.get()
with open("豆瓣top250.txt", 'a+', encoding='utf8') as f:
f.write(json.dumps(item, ensure_ascii=False, indent=4))
self.item_queue.task_done()
def run(self):
thread_list = list()
thread_list.append(Thread(target=self.construct_url))
thread_list.append(Thread(target=self.get_requests))
thread_list.append(Thread(target=self.parse_data))
thread_list.append(Thread(target=self.save_to_file))
def process_thread(t):
t.daemon = True
t.start()
pool = Pool(5)
pool.map(process_thread, thread_list)
self.url_queue.join()
self.data_queue.join()
self.item_queue.join()
if __name__ == "__main__":
obj = DoubanTop250()
obj.run()


 浙公网安备 33010602011771号
浙公网安备 33010602011771号