软考架构师(4)——数据库基础知识
友情链接:关系型数据库SQL语句操作
一:数据库模式与范式
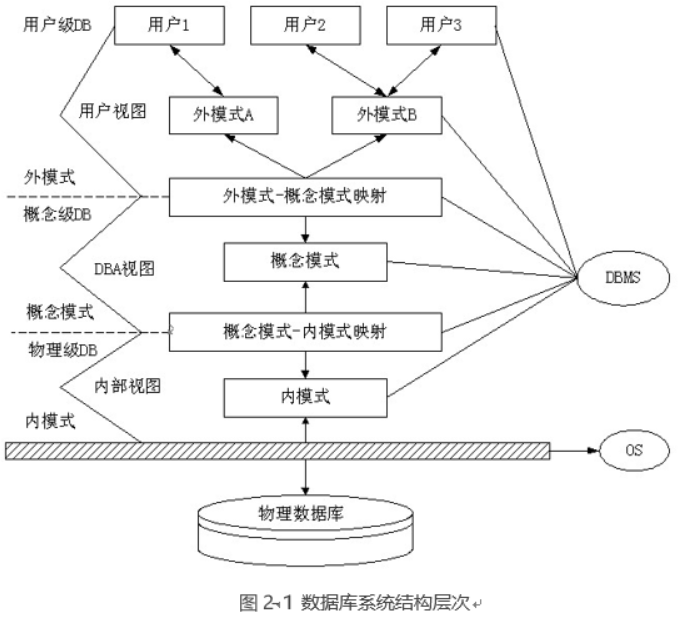
1)数据库结构与模式:
三层模式:概念模式(逻辑模式)、外模式、内模式。
两层映射
2)数据模型
数据模型主要有两大类,分别是概念数据模型(实体联系模型)和基本数据模型(结构数据模型)。
2.1:概念数据模型
按照用户的观点来对数据和信息建模,主要用于数据库设计。概念模型主要用
实体-联系方法(Entity-Relationship Approach)表示,所以也称E-R模型。:
2.2:基本数据模型
基本数据模型的组成要素是:数据结构,数据操作,完整性约束条件
常用的基本数据模型有
层次模型(只能表示1:n联系):
网状模型:
关系模型:
面向对象模型:
3)数据的规范化
函数依赖
1)部分依赖:
2)传递函数依赖:
范式:
1NF属性值都不可再分,范式逐步优化,已解决插入异常,删除异常,数据冗余

模式分解
如果某关系模式存在存储异常问题,则可通过分解该关系模式来解决问题。把一个关系模式分解成几个子关系模式,需要考虑的是该分解是否保持函数依赖,是否是无损联接。
4)事务
性质:原子性,一致性,隔离性,持久性
隔离级别:读未提交,读提交,可重复读,序列化
二:数据库设计
1)设计过程
规划
需求分析
概念结构设计
需求说明书提供的所有数据和处理要求进行抽象与综合处理,按一定的方法构造反映用户环境的数据及其相互联系的概念模型,即用户的数据模型或企业数据模型。这种概念数据模型与DBMS无关,是面向现实世界的、极易为用户所理解的数据模型
设计策略主要有自底向上,自顶向下,有里向外和混合策略
逻辑结构设计
逻辑设计的目的是把概念设计阶段设计好的基本E-R图转换为与选用的具体机器上的DBMS所支持的数据模型相符合的逻辑结构,包括数据库模式和外模式。
ER图:
三类冲突:属性冲突,命名冲突,结构冲突
数据库物理设计
三:事务管理
事物特性:原子性,一致性,隔离性,持续性
1)并发控制:
2)故障与恢复:
两阶段提交协议是协调所有分布式原子事务参与者,并决定提交或取消(回滚)的分布式算法。
二阶段提交(Two-phaseCommit)是指,在计算机网络以及数据库领域内,为了使基于分布式系统架构下的所有节点在进行事务提交时保持一致性而设计的一种算法(Algorithm)。通常,二阶段提交也被称为是一种协议(Protocol))。在分布式系统中,每个节点虽然可以知晓自己的操作时成功或者失败,却无法知道其他节点的操作的成功或失败。当一个事务跨越多个节点时,为了保持事务的ACID特性,需要引入一个作为协调者的组件来统一掌控所有节点(称作参与者)的操作结果并最终指示这些节点是否要把操作结果进行真正的提交(比如将更新后的数据写入磁盘等等)。因此,二阶段提交的算法思路可以概括为:参与者将操作成败通知协调者,再由协调者根据所有参与者的反馈情报决定各参与者是否要提交操作还是中止操作。
三阶段提交协议在协调者和参与者中都引入超时机制,并且把两阶段提交协议的第一个阶段拆分成了两步:询问,然后再锁资源,最后真正提交。
四:分布式数据库系统
1:特点
数据的分布性:
统一性:
透明性:
1)分片透明性是指用户不必关系数据是如何分片的,它们对数据的操作在全局关系上进行,即关系如何分片对用户是透明的,因此,当分片改变时应用程序可以不变。分片透明性是最高层次的透明性,如果用户能在全局关系一级操作,则数据如何分布,如何存储等细节自不必关系,其应用程序的编写与集中式数据库相同。
2)位置透明性是指用户不必知道所操作的数据放在何处,即数据分配到哪个或哪些站点存储对用户是透明的。因此,数据分片模式的改变,如把数据从一个站点转移到另一个站点将不会影响应用程序,因而应用程序不必改写。
3)局部映像透明性(逻辑透明)是最低层次的透明性,该透明性提供数据到局部数据库的映像,即用户不必关系局部 DBMS 支持哪种数据模型、使用哪种数据操纵语言,数据模型和操纵语言的转换是由系统完成的。因此,局部映像透明性对异构型和同构异质的分布式数据库系统是非常重要的。
4).复制透明性:用户不用关心数据库在网络中的各个节点的复制情况,被复制的数据的更新都由系统自动完成。在分布式数据库系统中,可以把一个场地的数据复制到其他场地存放,应用程序可以使用复制到本地的数据在本地完成分布式操作,避免通过网络传输数据,提高了系统的运行和查询效率。但是对于复制数据的更新操作,就要涉及到对所有复制数据的更新。
2:目标
局部结点自治性,不依赖中心结点,能连续操作,具有位置独立性,分片独立性 数据复制独立性,支持分布式查询处理,支持分布式事物管理,具有硬件独立性,具有DBMS独立性
3:CAP理论
一致性(C)。分布式系统中所有数据备份在同一时刻的值是否相同。
可用性(A)。当集群中一部分节点故障后,集群整体是否还能响应客户端的读写请求(可用性不仅包括读,还有写)。
分区容忍性(P)。集群中的某些节点无法联系后,集群整体是否还能继续进行服务。
4:分库分表
排序,分页,分组,实现
五:数据仓库
数据仓库(Data Warehouse)是一个面向主题的、集成的、相对稳定的、且随时间变化的的数据集合,用于支持管理决策。
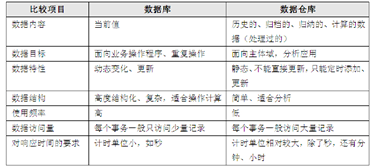
1:传统数据库与数据仓库的区别
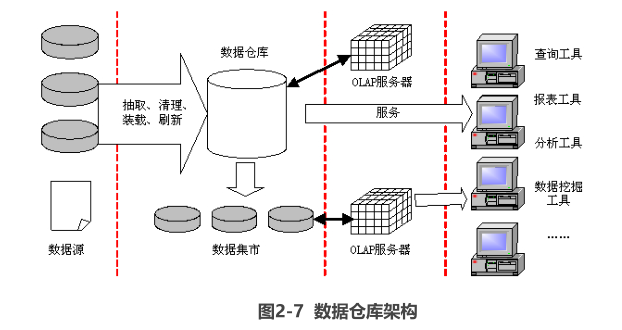
2:数据仓库的架构
六:数据挖掘
1:概念
数据挖掘一般是指从大量的数据中通过算法搜索隐藏于其中信息的过程。数据挖掘通常与计算机科学有关,并通过统计、在线分析处理、情报检索、机器学习、专家系统(依靠过去的经验法则)和模式识别等诸多方法来实现上述目标。数据挖掘是通过分析每个数据,从大量数据中寻找其规律的技术,主要有数据准备、规律寻找和规律表示3个步骤。数据准备是从相关的数据源中选取所需的数据并整合成用于数据挖掘的数据集;规律寻找是用某种方法将数据集所含的规律找出来;规律表示是尽可能以用户可理解的方式(如可视化)将找出的规律表示出来
数据挖掘的任务有 关联分析、聚类分析、分类分析、异常分析、特异群组分析和演变分析等等。
决策树
神经网络
遗传算法
关联规则挖掘算法
七:NOSQL
NoSQL 数据存储不需要固定的表结构,通常也不存在连接操作。在大数据存取上具备关系型数据库无法比拟的性能优
八:大数据
大数据(Big Data),指的是所涉及的数据量规模巨大到无法通过目前主流软件工具,在合理时间内达到获取、管理、处理、并整理成为帮助企业经营决策目的的信息。
1:关键技术
大数据处理关键技术一般包括:大数据采集、大数据预处理、大数据存储及管理、大数据分析及挖掘、大数据展现和应用(大数据检索、大数据可视化、大数据应用、大数据安全等)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号