

网页爬虫-全套皮肤图片爬取-Python项目
《英雄联盟》是一款火爆全网十几年的网络游戏,许多英雄原画和皮肤的图片非常的惊艳,拿来做壁纸或者宣传海报都十分的精美。因此我想设计个python脚本来爬取这些精美的皮肤图片。既增加了我对编程的兴趣,也可以掌握一门爬虫技能。
第一章 任务概述
首先,在《英雄联盟》官网找到资源库,在对应皮肤页面下右键查看页面源代码以及检查,进行页面分析。其次,在Pycharm里编码,将图片的url下载到本地。然后,在几个重要的js文件里利用正则表达式进行匹配,拼接得到正确的图片url,通过requests的get方法访问下载。最后,通过os新建文件夹,分类好保存图片。
值得注意的是,为了防止被网页检测到是爬虫,需要设置休眠时间,利用sleep()函数进行休眠控制。
第二章 算法设计思想
1.分析网站的方法: (1)静态网页; (2)动态网页(本实验爬取动态)
2.解析JS文件:
表1 JS文件返回的数据
|
纯JSON (形如{“key”:”value”}) |
jsonpath、dict、re |
|
纯JS+JSON |
str+jsonpath、re |
|
字符串 |
re |
3.可能遇到的问题:
·编码问题:\ud3e \\ud1a
·解决方案:str.encode().decode(‘unicode_escape’)
4.爬虫下载图片实际就是接收数据流:
·判断是否存在文件夹
os.path.exists(file_path)
·创建文件夹
os.mkdir(file_path)
·创建文件
open(file_path,’wb’)
5. 在《英雄联盟》官网找到资料库,打开该页面选择一个英雄。
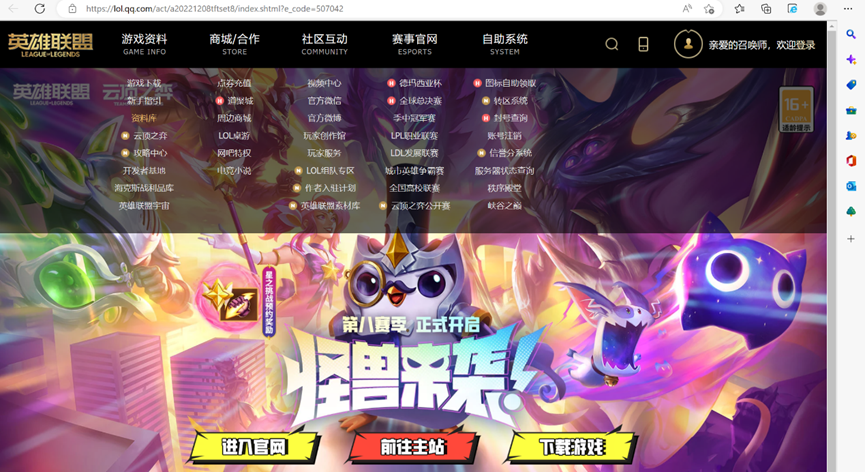
图1 《英雄联盟》官网资料库
6.右键点击检查,在Network里找到champion.js文件,可以看到里面有全部的英雄json信息,在Headers里记录下url: https://lol.qq.com/biz/hero/champion.js
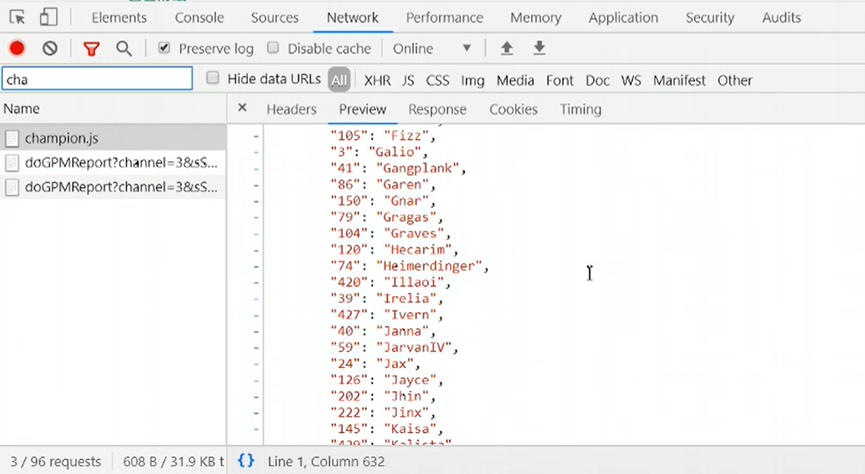
图2 所有英雄的json信息
7.查看某个英雄皮肤的json信息,分析其url,利用正则表达式拼接起来,形成完整图片的url,以下展示核心代码:
skin_ids = re.findall(r'"id":"(\d+?)"',hero_info_js)
for id,name in zip(skin_ids,skin_names):
img_url = f'https://game.gtimg.cn/images/lol/act/img/skin/big{id}.jpg'
8.解决一些皮肤名称出现‘\’而引起的错误,例如阿狸的K\DA 这款皮肤。
#解决皮肤名称里的‘\’引起的错误
name = name.replace('/','')
name = name.replace('\\','')
9.创建文件夹分类保存每个英雄的多个皮肤。
if not os.path.exists(f'./img/{n}'):
os.makedirs(f'./img/{n}')
with open(f'./img/{n}/{name}.jpg','wb') as
f:
f.write(img_resp.content)
sleep(1)
第三章 测试结果
1.设计了print函数打印输出当前正在爬取的图片,便于及时发现错误。
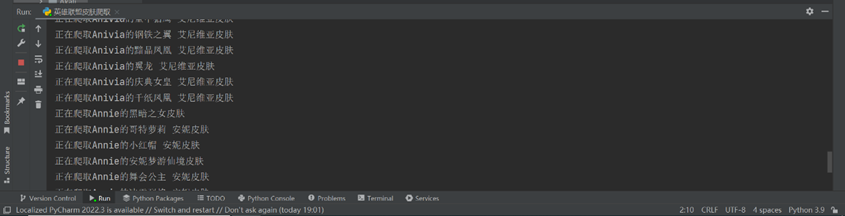
图3 print打印输出正在爬取的图片
2.在右侧指定文件夹内,便可以发现爬取到的英雄皮肤。
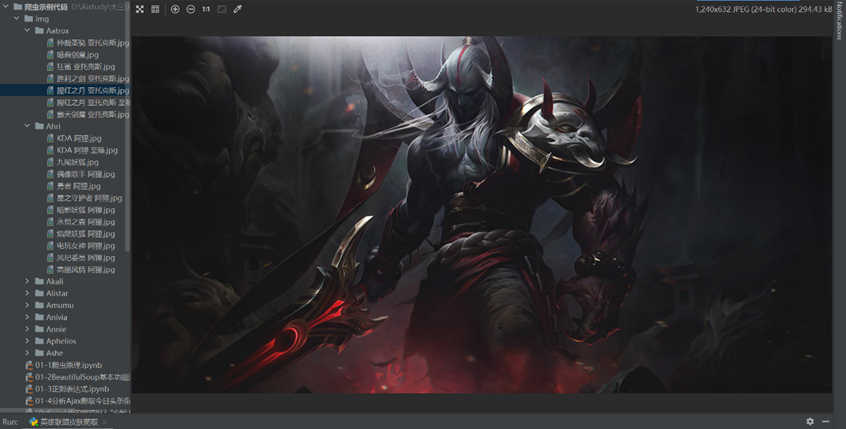
图4 爬取的英雄剑魔皮肤图片
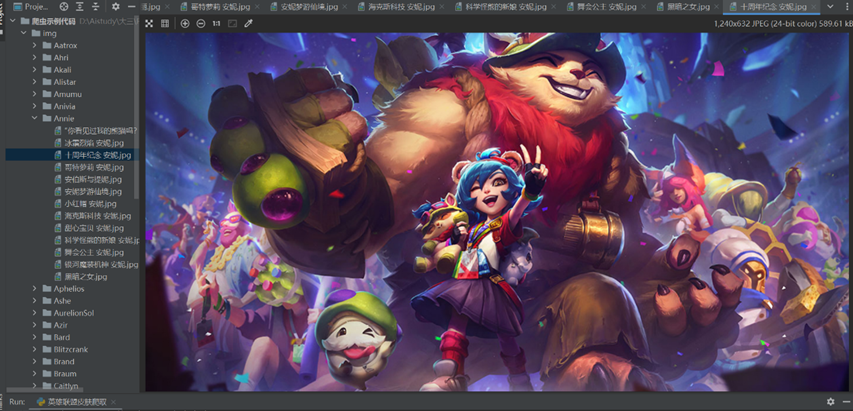
图5 爬取的英雄安妮皮肤图片
3.打开磁盘里的文件目录,可以发现皮肤被整齐的规划到不同英雄的文件夹内。
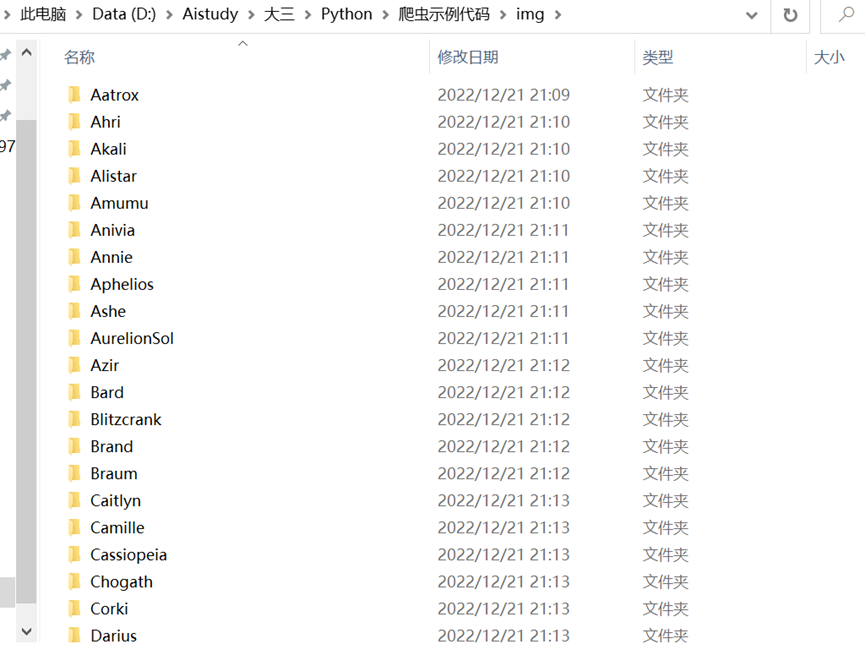
图6 划归整齐的皮肤文件夹

 浙公网安备 33010602011771号
浙公网安备 33010602011771号