hadoop中常见的问题
一.在root下进行格式化
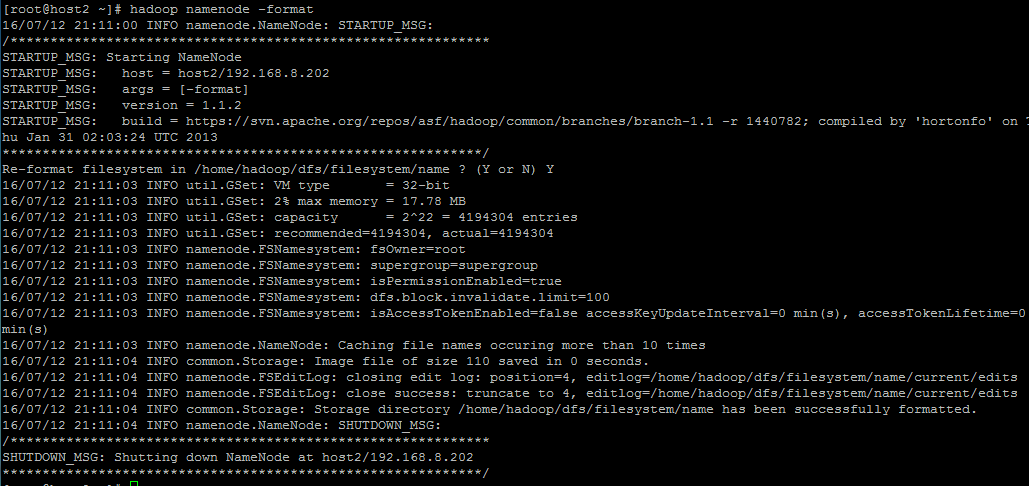
这样很糟糕
这样的话,若是第一次装的话,我的建议是将生成的文件都删掉,恢复到最开始的状态,
1. 首先你需要删除
vi conf/hdfs-site.xml 配置文件的dfs.name.dir和dfs.data.di的路径位置,我的是:/home/hadoop/dfs
故为:rm -rf /home/hadoop/dfs
2.其次你需要删除
vi conf/mapred-site.xml 文件中的mapred.system.dir 的文件位置:
<value>/home/hadoop/mapreduce/system</value>
故将其进行删除: rm -rf /home/hadoop/mapreduce
3.然后你的将tmp 下的hadoop文件删除
先转换为root下:
su root
输入密码
rm -rf /tmp/hadoop*
4. 重复上面的1、2、3 ,在你要配置的每个Linus的虚拟机上都执行一遍
5.完成后,回到master上,
切换为hadoop用户 : su hadoop
保证是hadoop用户,后
在执行格式化: hadoop namenode -format
执行启动集群: start-all.sh
完成后 查看进程:jps
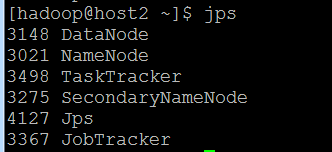
总共为6个,OK 你的集群配置就好了!
二.容易范的错误:
1. 在 root 用户下启动命令“ ./start-all.sh”,会造成文件权限被修改,需要重新设置权限:更改
被 root 用户变更权限的文件:
/opt/hadoop/name/current 所有文件改为 hadoop 用户
/opt/hadoop/hadoop-1.2.1/logs 所有文件权限改为 hadoop 用户
/opt/hadoop/name 下的 in_use.lock 文件删除掉
2. 在配置xml文件的时候,
<property>
<name>mapred.local.dir</name>
<value>/home/hadoop/mapreduce/local</value>
<value></value>之间中不能有空格,否则弄了半天,却不清楚是为啥,调试不通过,十分痛苦,
因而不能有空格
三.hadoop无法正常启动-localhost:50060无法打开localhost:50070无法打开
最近接触大数据,开始学习hadoop,在自己电脑上搭建了伪分布的环境之后,关机的时候没有关闭hadoop环境,再次开机重新启动服务的时候发现只有jobTracker可以启动,剩下的都启动不了了,在浏览器中打开localhost:50030/可以打开,但是localhost:50060/和localhost:50070无法打开,上网各种查,终于解决了问题,正好打算开始写自己的博客,就以这个问题开始吧。
其实这主要是因为多次个格式化namenode引起的
在/tmp/下生成了多个文件,并且在hsperfdata_hadoop文件夹下生成了多个ID,其中有一个是没用的(和上层目录下hadoop_namenode.pid不同的那个).赶紧删掉它吧,然后再次格式化,重启服务,一切OK~~
四. Browse the filesystem链接打不开
现象:在访问Master:50070之后,点击browse the filesystem后,该页无法显示。
原因:点击browse the filesystem后,网页转向的地址用的是hadoop集群的某一个datanode的主机名,由于客户端的浏览器无法解析这个主机名,因此该页无法显示。
解决:需要在客户端的hosts文件里加入hadoop集群的ip地址与对应的主机名,这样就能解决问题了。
五 解决"no datanode to stop"问题
当我停止Hadoop时发现如下信息:
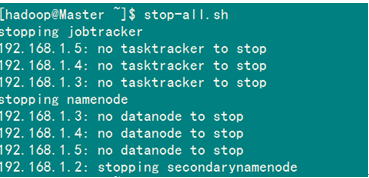
原因:每次namenode format会重新创建一个namenodeId,而tmp/dfs/data下包含了上次format下的id,namenode format清空了namenode下的数据,但是没有清空datanode下的数据,导致启动时失败,所要做的就是每次fotmat前,清空tmp一下的所有目录。
第一种解决方案如下:
1)先删除"/usr/hadoop/tmp"
rm -rf /usr/hadoop/tmp
2)创建"/usr/hadoop/tmp"文件夹
mkdir /usr/hadoop/tmp
3)删除"/tmp"下以"hadoop"开头文件
rm -rf /tmp/hadoop*
4)重新格式化hadoop
hadoop namenode -format
5)启动hadoop
start-all.sh
使用第一种方案,有种不好处就是原来集群上的重要数据全没有了。假如说Hadoop集群已经运行了一段时间。建议采用第二种。
第二种方案如下:
1)修改每个Slave的namespaceID使其与Master的namespaceID一致。
或者
2)修改Master的namespaceID使其与Slave的namespaceID一致。
该"namespaceID"位于"/usr/hadoop/tmp/dfs/data/current/VERSION"文件中,前面蓝色的可能根据实际情况变化,但后面红色是不变的。
例如:查看"Master"下的"VERSION"文件
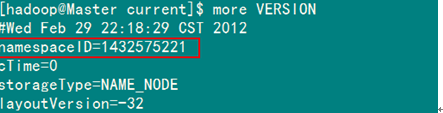
本人建议采用第二种,这样方便快捷,而且还能防止误删。
5.3 Slave服务器中datanode启动后又自动关闭
查看日志发下如下错误。
ERROR org.apache.hadoop.hdfs.server.datanode.DataNode: java.io.IOException: Call to ... failed on local exception: java.net.NoRouteToHostException: No route to host
解决方案是:关闭防火墙
service iptables stop
5.4 从本地往hdfs文件系统上传文件
出现如下错误:
INFO hdfs.DFSClient: Exception in createBlockOutputStream java.io.IOException:Bad connect ack with firstBadLink
INFO hdfs.DFSClient: Abandoning block blk_-1300529705803292651_37023
WARN hdfs.DFSClient: DataStreamer Exception: java.io.IOException: Unable to create new block.
解决方案是:
1)关闭防火墙
service iptables stop
2)禁用selinux
编辑 "/etc/selinux/config"文件,设置"SELINUX=disabled"
5.5 安全模式导致的错误
出现如下错误:
org.apache.hadoop.dfs.SafeModeException: Cannot delete ..., Name node is in safe mode
在分布式文件系统启动的时候,开始的时候会有安全模式,当分布式文件系统处于安全模式的情况下,文件系统中的内容不允许修改也不允许删除,直到安全模式结束。安全模式主要是为了系统启动的时候检查各个DataNode上数据块的有效性,同时根据策略必要的复制或者删除部分数据块。运行期通过命令也可以进入安全模式。在实践过程中,系统启动的时候去修改和删除文件也会有安全模式不允许修改的出错提示,只需要等待一会儿即可。
解决方案是:关闭安全模式
hadoop dfsadmin -safemode leave
5.6 解决Exceeded MAX_FAILED_UNIQUE_FETCHES
出现错误如下:
Shuffle Error: Exceeded MAX_FAILED_UNIQUE_FETCHES; bailing-out
程序里面需要打开多个文件,进行分析,系统一般默认数量是1024,(用ulimit -a可以看到)对于正常使用是够了,但是对于程序来讲,就太少了。
解决方案是:修改2个文件。
1)"/etc/security/limits.conf"
vim /etc/security/limits.conf
加上:
soft nofile 102400
hard nofile 409600
2)"/etc/pam.d/login"
vim /etc/pam.d/login
添加:
session required /lib/security/pam_limits.so
针对第一个问题我纠正下答案:
这是reduce预处理阶段shuffle时获取已完成的map的输出失败次数超过上限造成的,上限默认为5。引起此问题的方式可能会有很多种,比如网络连接不正常,连接超时,带宽较差以及端口阻塞等。通常框架内网络情况较好是不会出现此错误的。
5.7 解决"Too many fetch-failures"
出现这个问题主要是结点间的连通不够全面。
解决方案是:
1)检查"/etc/hosts"
要求本机ip 对应 服务器名
要求要包含所有的服务器ip +服务器名
2)检查".ssh/authorized_keys"
要求包含所有服务器(包括其自身)的public key
5.8 处理速度特别的慢
出现map很快,但是reduce很慢,而且反复出现"reduce=0%"。
解决方案如下:
结合解决方案5.7,然后修改"conf/hadoop-env.sh"中的"export HADOOP_HEAPSIZE=4000"
5.9解决hadoop OutOfMemoryError问题
出现这种异常,明显是jvm内存不够得原因。
解决方案如下:要修改所有的datanode的jvm内存大小。
Java –Xms 1024m -Xmx 4096m
一般jvm的最大内存使用应该为总内存大小的一半,我们使用的8G内存,所以设置为4096m,这一值可能依旧不是最优的值。
5.10 Namenode in safe mode
解决方案如下:
bin/hadoop dfsadmin -safemode leave
5.11 IO写操作出现问题
0-1246359584298, infoPort=50075, ipcPort=50020):Got exception while serving blk_-5911099437886836280_1292 to /172.16.100.165:
java.net.SocketTimeoutException: 480000 millis timeout while waiting for channel to be ready for write. ch : java.nio.channels.SocketChannel[connected local=/
172.16.100.165:50010 remote=/172.16.100.165:50930]
at org.apache.hadoop.net.SocketIOWithTimeout.waitForIO(SocketIOWithTimeout.java:185)
at org.apache.hadoop.net.SocketOutputStream.waitForWritable(SocketOutputStream.java:159)
……
It seems there are many reasons that it can timeout, the example given in HADOOP-3831 is a slow reading client.
解决方案如下:
在hadoop-site.xml中设置dfs.datanode.socket.write.timeout=0
5.12 status of 255 error
错误类型:
java.io.IOException: Task process exit with nonzero status of 255.
at org.apache.hadoop.mapred.TaskRunner.run(TaskRunner.java:424)
错误原因:
Set mapred.jobtracker.retirejob.interval and mapred.userlog.retain.hours to higher value. By default, their values are 24 hours. These might be the reason for failure, though I'm not sure restart.
解决方案如下:单个datanode
如果一个datanode 出现问题,解决之后需要重新加入cluster而不重启cluster,方法如下:
bin/hadoop-daemon.sh start datanode
bin/hadoop-daemon.sh start jobtracker

 浙公网安备 33010602011771号
浙公网安备 33010602011771号