MapReduce案例三:数据压缩
一、对数据流的压缩和解压缩
CompressionCodec有两个方法可以用于轻松地压缩或解压缩数据。要想对正在被写入一个输出流的数据进行压缩,我们可以使用createOutputStream(OutputStreamout)方法创建一个CompressionOutputStream,将其以压缩格式写入底层的流。相反,要想对从输入流读取而来的数据进行解压缩,则调用createInputStream(InputStreamin)函数,从而获得一个CompressionInputStream,从而从底层的流读取未压缩的数据。
- 一些压缩方式:
压缩方式 | 对应参数
-|-|-
DEFLATE | org.apache.hadoop.io.compress.DefaultCodec
gzip | org.apache.hadoop.io.compress.GzipCodec
bzip2 | org.apache.hadoop.io.compress.BZip2Codec
- 创建测试类TestCompress:
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.compress.CompressionCodec;
import org.apache.hadoop.io.compress.CompressionCodecFactory;
import org.apache.hadoop.io.compress.CompressionOutputStream;
import org.apache.hadoop.util.ReflectionUtils;
public class TestCompress {
public static void main(String[] args) throws Exception, IOException {
// compress("e:/test.txt","org.apache.hadoop.io.compress.BZip2Codec");
decompress("e:/test.txt.bz2");
}
/**
* 压缩
* filername:要压缩文件的路径
* method:欲使用的压缩的方法(org.apache.hadoop.io.compress.BZip2Codec)
*/
public static void compress(String filername, String method) throws ClassNotFoundException, IOException {
// 1 创建压缩文件路径的输入流
File fileIn = new File(filername);
InputStream in = new FileInputStream(fileIn);
// 2 获取压缩的方式的类
Class codecClass = Class.forName(method);
Configuration conf = new Configuration();
// 3 通过名称找到对应的编码/解码器
CompressionCodec codec = (CompressionCodec) ReflectionUtils.newInstance(codecClass, conf);
// 4 该压缩方法对应的文件扩展名
File fileOut = new File(filername + codec.getDefaultExtension());
OutputStream out = new FileOutputStream(fileOut);
CompressionOutputStream cout = codec.createOutputStream(out);
// 5 流对接
IOUtils.copyBytes(in, cout, 1024 * 1024 * 5, false); // 缓冲区设为5MB
// 6 关闭资源
in.close();
cout.close();
out.close();
}
/**
* 解压缩
* filename:希望解压的文件路径
*/
public static void decompres(String filename) throws FileNotFoundException, IOException {
Configuration conf = new Configuration();
CompressionCodecFactory factory = new CompressionCodecFactory(conf);
// 1 获取文件的压缩方法
CompressionCodec codec = factory.getCodec(new Path(filename));
// 2 判断该压缩方法是否存在
if (null == codec) {
System.out.println("Cannot find codec for file " + filename);
return;
}
// 3 创建压缩文件的输入流
InputStream cin = codec.createInputStream(new FileInputStream(filename));
// 4 创建解压缩文件的输出流
File fout = new File(filename + ".decoded");
OutputStream out = new FileOutputStream(fout);
// 5 流对接
IOUtils.copyBytes(cin, out, 1024 * 1024 * 5, false);
// 6 关闭资源
cin.close();
out.close();
}
}
二、在Map输出端采用压缩
即使你的MapReduce的输入输出文件都是未压缩的文件,你仍然可以对map任务的中间结果输出做压缩,因为它要写在硬盘并且通过网络传输到reduce节点,对其压缩可以提高很多性能。这里以wordcount为例,driver类只增加两个参数,mapper和reducer代码保持不变。
- WordCountDriver类代码:
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.compress.BZip2Codec;
import org.apache.hadoop.io.compress.CompressionCodec;
import org.apache.hadoop.io.compress.GzipCodec;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCountDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
args = new String[]{"D:\\大数据API\\aaa.txt","D:\\大数据API\\data"};
Configuration configuration = new Configuration();
// 开启map端输出压缩
configuration.setBoolean("mapreduce.map.output.compress", true);
// 设置map端输出压缩方式
configuration.setClass("mapreduce.map.output.compress.codec", BZip2Codec.class, CompressionCodec.class);
Job job = Job.getInstance(configuration);
job.setJarByClass(WordCountDriver.class);
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
boolean result = job.waitForCompletion(true);
System.exit(result ? 1 : 0);
}
}
- Mapper保持不变:
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable>{
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString();
String[] words = line.split(" ");
for(String word:words){
context.write(new Text(word), new IntWritable(1));
}
}
}
- Reducer保持不变:
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable>{
@Override
protected void reduce(Text key, Iterable<IntWritable> values,
Context context) throws IOException, InterruptedException {
int count = 0;
for(IntWritable value:values){
count += value.get();
}
context.write(key, new IntWritable(count));
}
}
三、在Reduce输出端采用压缩
这里仍以wordcount为例,driver类只增加两个参数,mapper和reducer代码保持不变,所以就省略不写了,详细参看上面。
- 修改driver类:
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.compress.BZip2Codec;
import org.apache.hadoop.io.compress.DefaultCodec;
import org.apache.hadoop.io.compress.GzipCodec;
import org.apache.hadoop.io.compress.Lz4Codec;
import org.apache.hadoop.io.compress.SnappyCodec;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCountDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
args = new String[]{"D:\\大数据API\\aaa.txt","D:\\大数据API\\data"};
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
job.setJarByClass(WordCountDriver.class);
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 设置reduce端输出压缩开启
FileOutputFormat.setCompressOutput(job, true);
// 设置压缩的方式
FileOutputFormat.setOutputCompressorClass(job, BZip2Codec.class);
// FileOutputFormat.setOutputCompressorClass(job, GzipCodec.class);
// FileOutputFormat.setOutputCompressorClass(job, DefaultCodec.class);
boolean result = job.waitForCompletion(true);
System.exit(result?1:0);
}
}
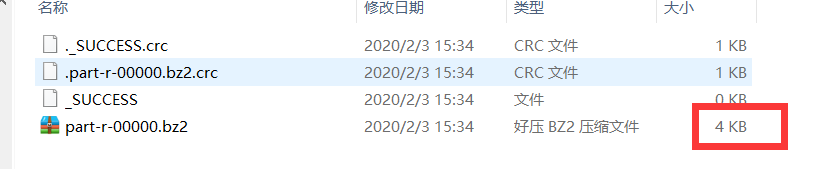
- Reduce压缩结果展示:
压缩前:

压缩后:
作者:落花桂
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号