SECOND算法解析(2018)
在AVOD的论文解析中,我们提到了AVOD(2018)其实是MV3D(2017)论文的升级版。
相似地,本文要介绍的SECOND(2018)其实就是VoxelNet(2017)论文的升级版,本质是voxelnet+稀疏卷积。
SECOND的全称是Sparsely Embedded Convolutional Detection。
论文的地址为:https://www.mdpi.com/1424-8220/18/10/3337www.mdpi.com/1424-8220/18/10/3337
代码的地址为:github.com/traveller59/second.pytorch
论文提出的主要动机为:
(1)考虑到VoxelNet论文在运算过程中运算量较大,且速度不佳。作者引入了稀疏3D卷积去代替VoxelNet中的3D卷积层,提高了检测速度和内存使用;
(2)VoxelNet论文有个比较大的缺点就是在训练过程中,与真实的3D检测框相反方向的预测检测框会有较大的损失函数,从而造成训练过程不好收敛。
顺带着动机,作者又提出了一些其他的创新点:
(1)比如数据增强这块,作者使用了数据库采样的操作;
(2)对于正负样本数量的极度不平衡问题,作者借鉴了RetinaNet中采用的Focal Loss。
这篇文章有关稀疏卷积部分稍微有些难懂,我找遍了全网有关SECOND的解读,大家都跳过了稀疏卷积这块,这确实让人头大。
网络的结构
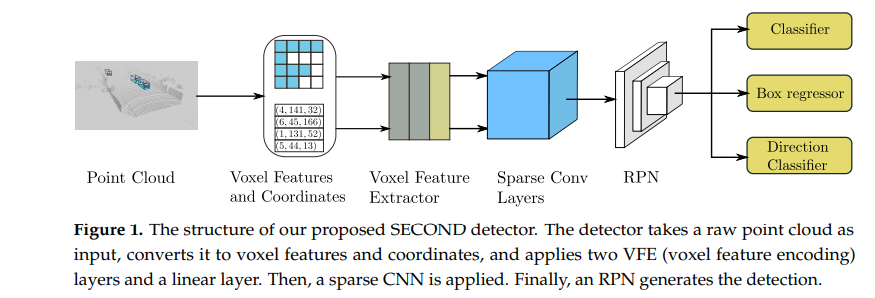
考虑到VoxelNet通过Feature Learning Network后获得了稀疏的四维张量,而采用3D卷积直接对这四维的张量做卷积运算的话,确实耗费运算资源。SECOND作为VoxelNet的升级版,用稀疏3D卷积替换了普通3D卷积。
这里我们直接给出VoxelNet的结构图,然后再此基础上进行修改,获得SECOND的网络结构图,分别如下两张图所示。
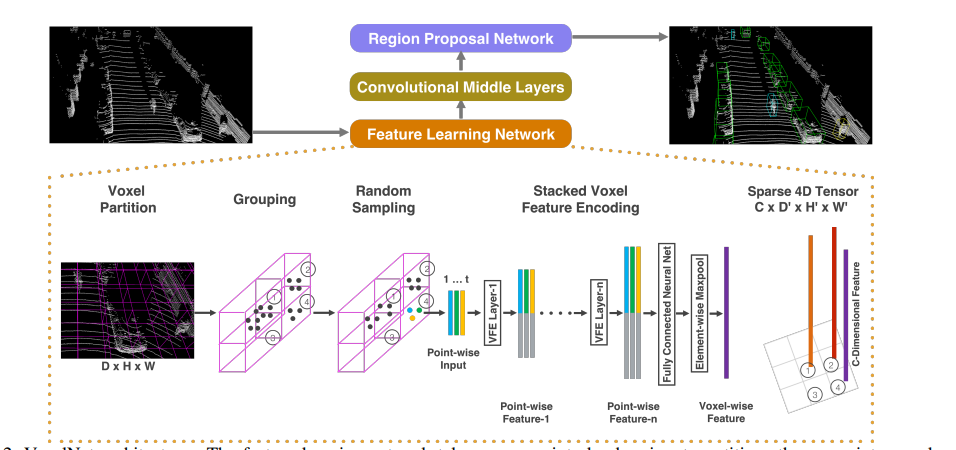
Voxel模型结构
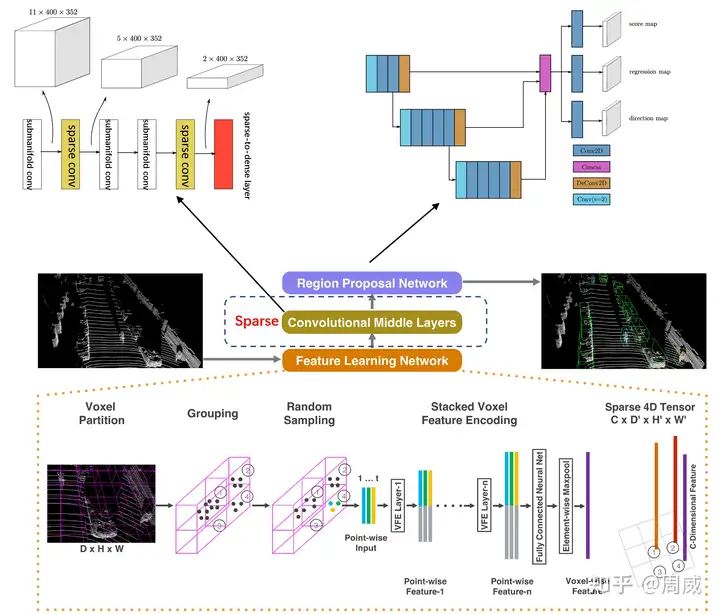
second 网络结构
这么一看,大家就很容易看的出来两者之间的共性和差异了。接下来以我自己不成文的见解,简单聊聊稀疏卷积。
(1)稀疏卷积
作者在VoxelNet的Convolutional Middle Layers的基础上引入了Sparse Convolutional Middle Layers,稀疏卷积就用在这个模块里面。
作者在论文中提到:
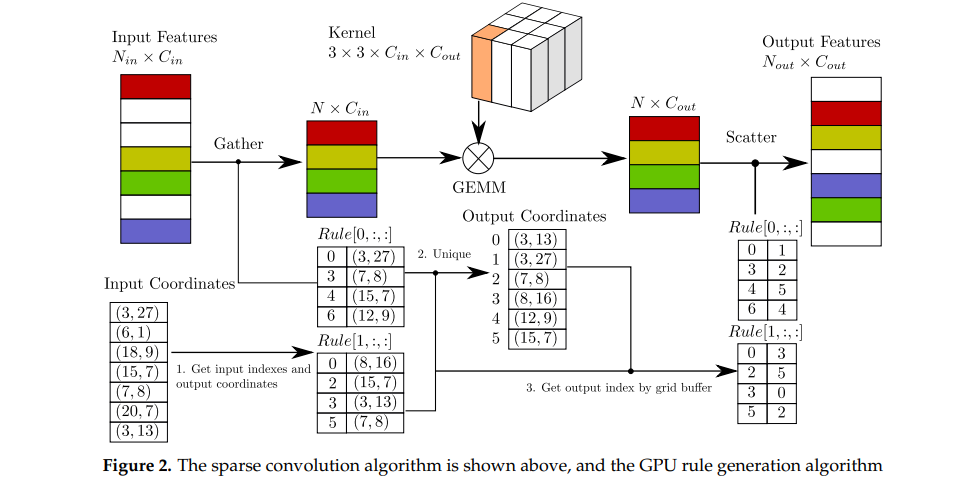
如下图3所示,可以归纳为:
- 将稀疏的输入特征通过gather操作获得密集的gather特征;
- 然后使用GEMM对密集的gather特征进行卷积操作,获得密集的输出特征;
- 通过预先构建的输入-输出索引规则矩阵,将密集的输出特征映射到稀疏的输出特征。
这个输入-输出索引规则矩阵很明显就是稀疏卷积的关键所在了。
这里简单说一下输入-输出索引规则矩阵的生成规则。作者在原文中提到:
A more direct approach to rule generation is to iterate over the input points to find the outputs related to each input point and store the corresponding indexes into the rules. During the iterative process, a table is needed to check the existence of each output location to decide whether to accumulate the data using a global output index counter.
大致的意思就是:
- 迭代输入点以获取每个输入点对应的输出,并将对应的索引存储到规则中
- 迭代过程中,建立一个表来检查每个输出位置是否真实存在
作者在SECOND中是这样实现的:
- 1. 收集输入索引(input indexes)和相关的空间索引(associated spatial indexes),并复制输出位置(Duplicate output locations);
- 2. 在空间索引上执行unique parallel算法,获得输出索引(output indexes)和对应的空间索引(associated spatial indexes)。
- 3. 生成一个与稀疏数据的相同空间维度的缓冲区,用于查找表
- 4. 最后,对规则进行迭代,并使用存储的空间索引来获得每个输入索引对应的输出索引。
具体的伪代码实现如下(我按照上面的步骤进行了一一对应):

至此,我对作者在原文中提到的稀疏卷积的解释就到此结束了。这个稀疏卷积结合submanifold convolutional layer实现了Sparse Convolutional Middle Layers,具体结果图如下:
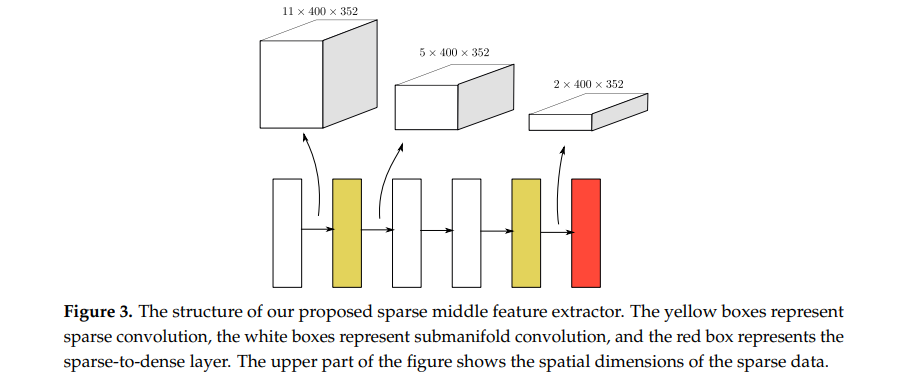
(2)方向回归
上面聊完了稀疏卷积后,SECOND中还有一个重要的创新,就是对物体方向估计进行了重新的建模。
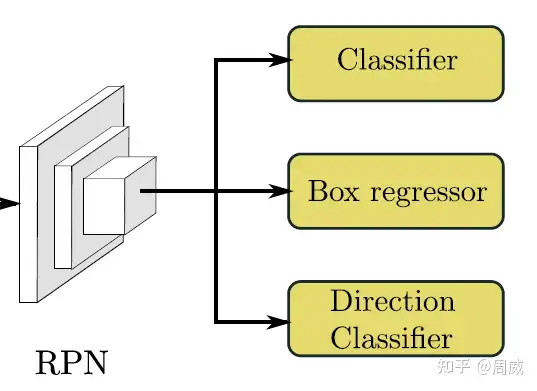
这里,作者在最后的RPN层(原来是两个分支,用来物体分类和位置回归)多引入了一个分支(如下图5所示),用来对物体方向进行分类。为什么是分类不是回归呢?

这时候大家可能会问了,那这样的话,模型预测方向很可能与真实方向相差180度呀。
这时候作者提出了另一种解决方法(也就是RPN中的direction classifer分支),作者将车头是否区分正确直接通过一个softmax loss来进行约束。如果theta>0则为正,theta<0则为负。那么这就是个简单的二分类问题了,也就是结构图中direction classifer。
3 总结
至此,有关SECOND的解析就结束了。说句老实话,我对稀疏卷积的一些实现细节可能还是不够清楚,所以希望有比较懂的大佬可以不吝指导,十分感谢!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号