kettle实现oracle迁移至mysql
公司有需求将两张业务表从oracle迁移至mysql,表的数据量大概3000W左右,在对比了各种迁移方法后,决定使用kettle。
Kettle是一款国外开源的ETL工具,纯java编写,可以在Window、Linux、Unix上运行,绿色无需安装,数据抽取高效稳定。kettle的数据抽取主要在于抽取数据,而没有考虑数据库的函数、存储过程、视图、表结构以及索引、约束等等,如果想对这些内容进行迁移,就需要通过写脚本或者更改kettle源码的方式实现了。
一、安装java 环境
参考:https://www.cnblogs.com/nothingonyou/p/11936850.html
二、部署kettle
官网下载较慢,这里选择国内镜像下载,使用的是pdi-ce-7.1.0.0-12.zip 版本。
官网地址:https://community.hitachivantara.com/s/article/data-integration-kettle
下载地址:http://mirror.bit.edu.cn/pentaho/Data%20Integration/7.1/
解压后进入到Kettle目录,双击运行spoon.bat文件,出现如下界面及说明kettle成功部署。

1. 数据库连接驱动
在运行之前,我们需要下载对应数据库的jar包导入到Kettle的lib目录下,比如我们需要把oracle迁移到mysql,那就需要oracle和mysql两个jar包:

2. 配置kettle转换
双击打开spoon.bat,在左侧主对象菜单栏,新建一个转换,命名为o2m,如下图:

2.1配置oracle和mysql连接
在DB连接一栏,右击新建连接,配置oracle连接:
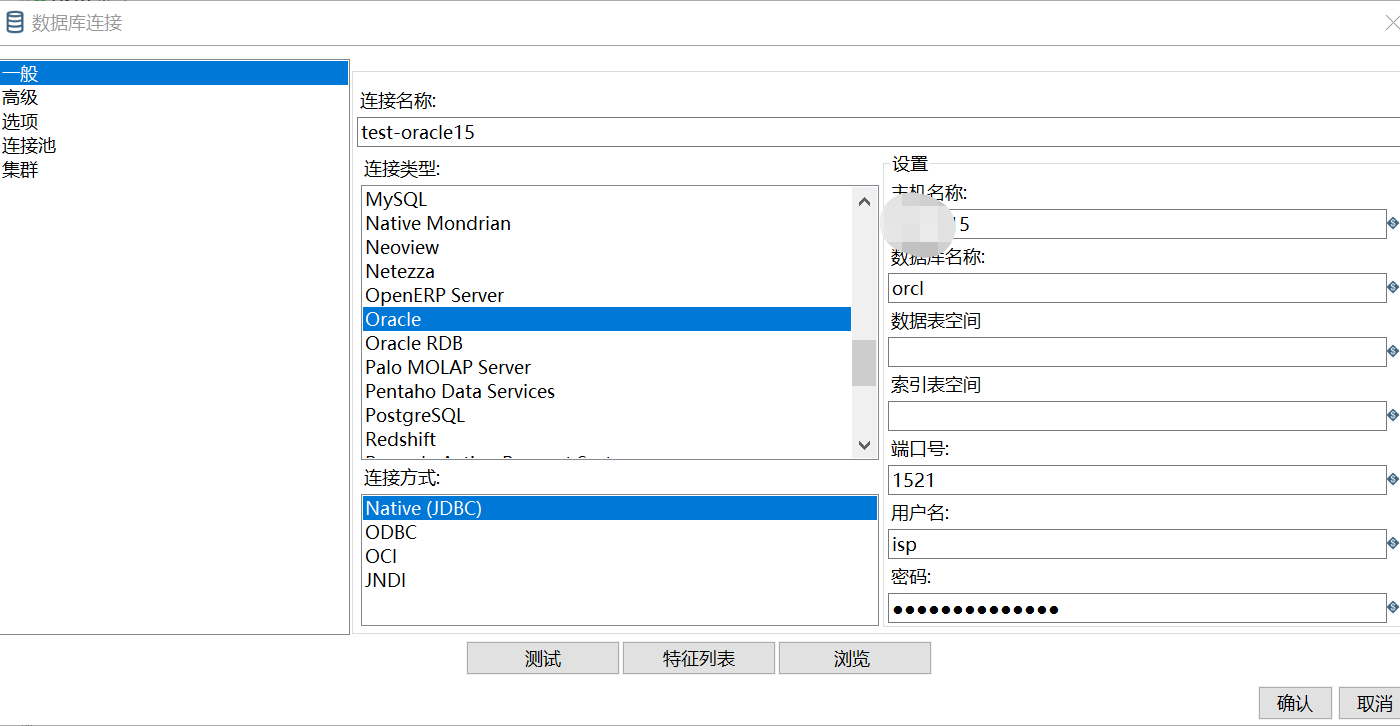
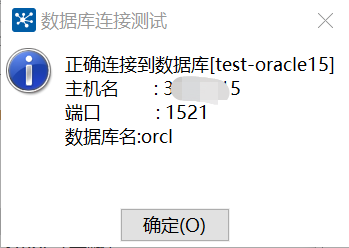
点击测试,显示成功即为配置完成
配置mysql连接:
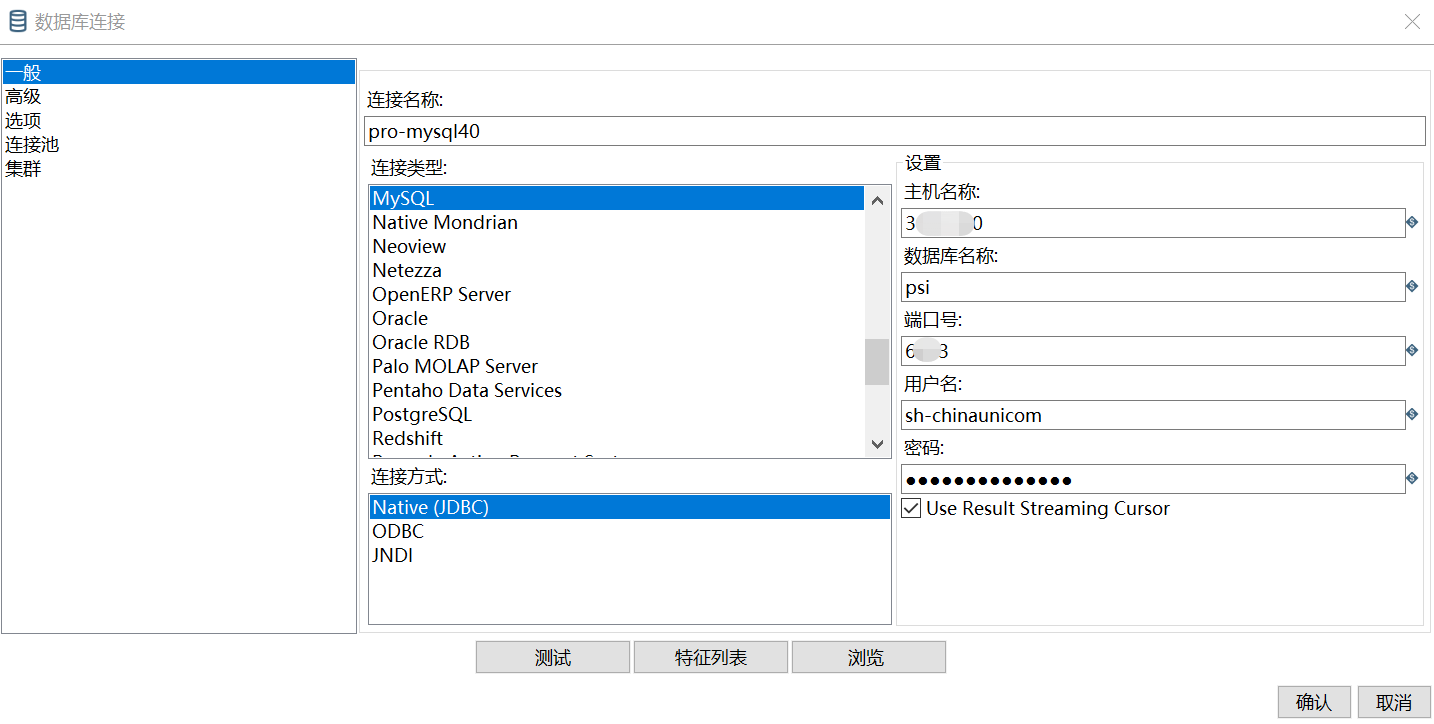
点击测试,显示成功即为配置完成

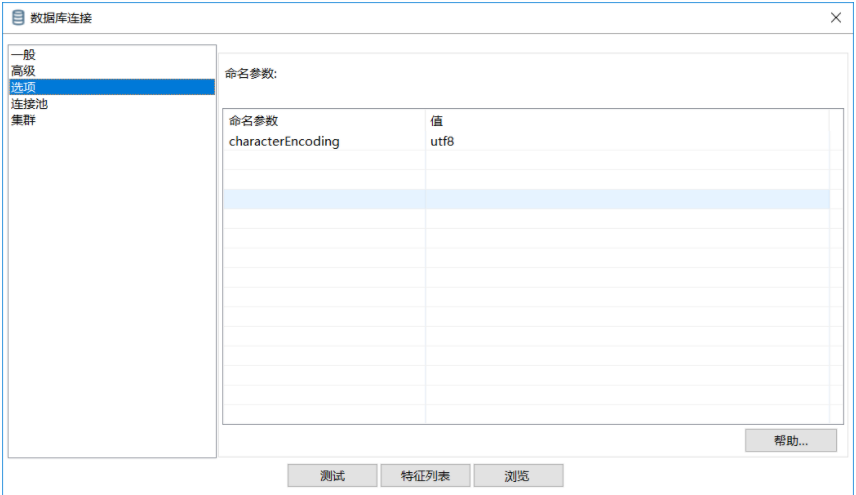
2.2 配置字符集
迁移时要确认两边数据库使用的是哪种字符集,不然可能会出现迁移后出现乱码的问题,我这里oracle是16GBK,mysql是UTF-8,UTF-8兼容16GBK,故没有配置。
2.3 配置迁移步骤
在左侧菜单栏【转换】里面,选择【核心对象】,【输入】一栏接着双击【表输入】,或者选中将【表输入】拖拽到右侧空白区域。
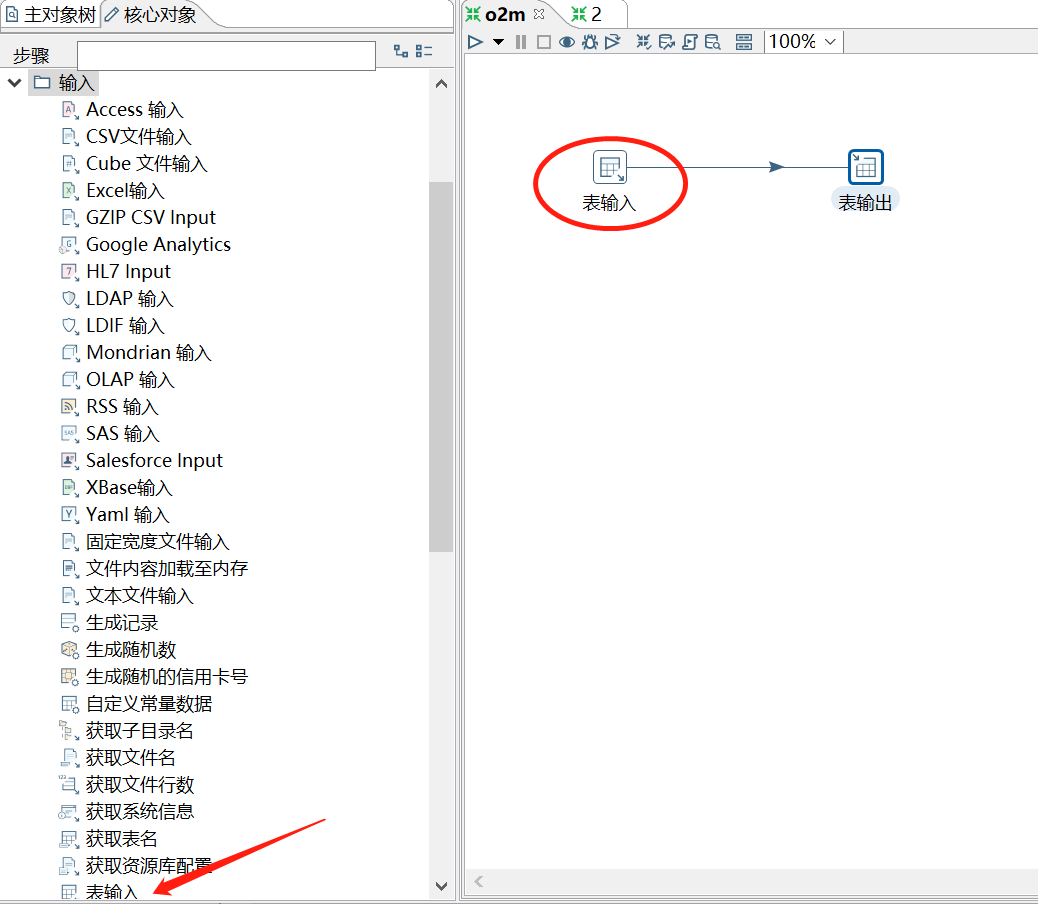
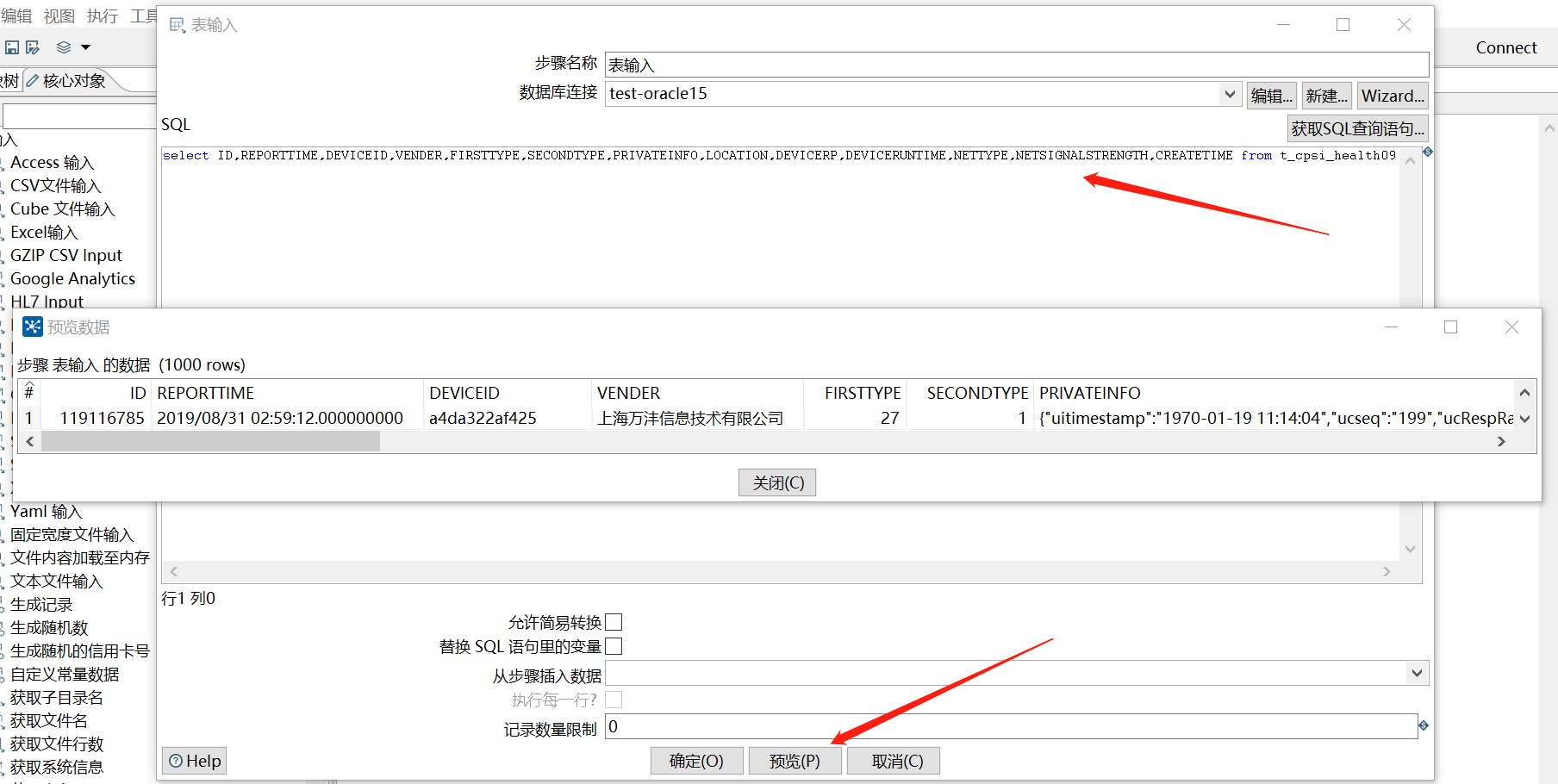
双击你拖进来的【表输入】,修改“步骤名称”,选择源数据,点击获取【获取SQL查询语句】,选择你想同步的表,点击确定后就可以了。当然也可以自己写sql语句,我这里是自己写的sql,点击【预览】可以查看要迁移的数据。
接下来配置表输出,在左侧菜单栏【转换】里面,选择【核心对象】,【输出】一栏接着双击【表输出】,或者选中将【表输出】拖拽到右侧空白区域。
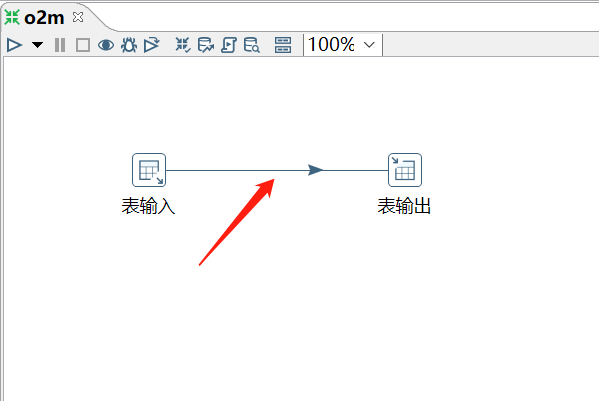
单击【表输入】,按shift键连接【表输入】,建立起【表输入】和【表输出】的连接,如图:
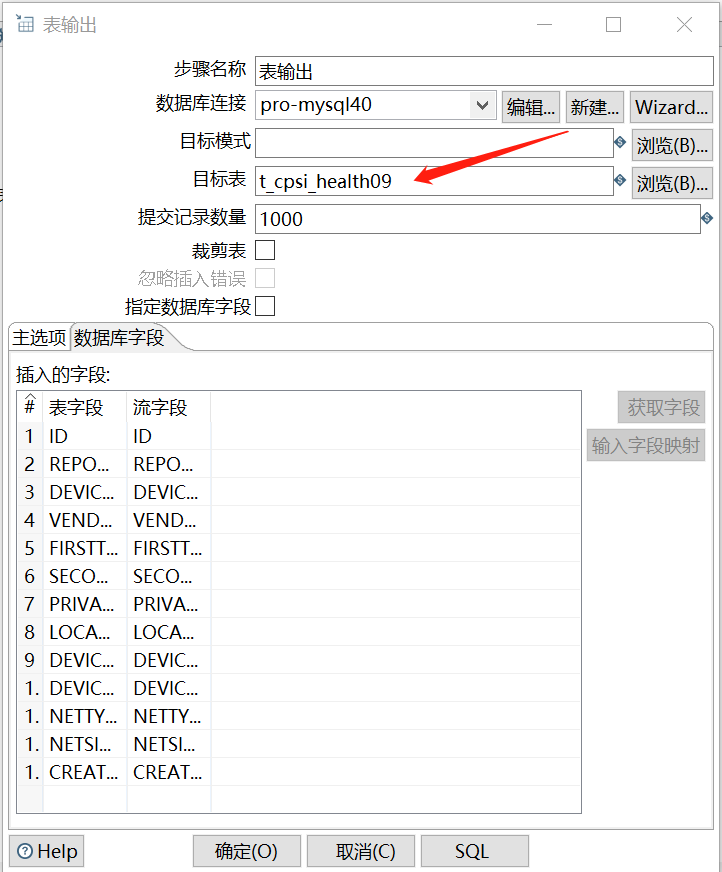
双击【表输出】,配置要迁移的目标表,我这里两边数据库字段一样,故而可以不用修改,如图:
ctrl+s保存为o2m.ktr文件,到这里一个简单的转换就配置完成了。
2.4 运行转换
手工运行作业,点击下图红色圈圈里面的按钮。
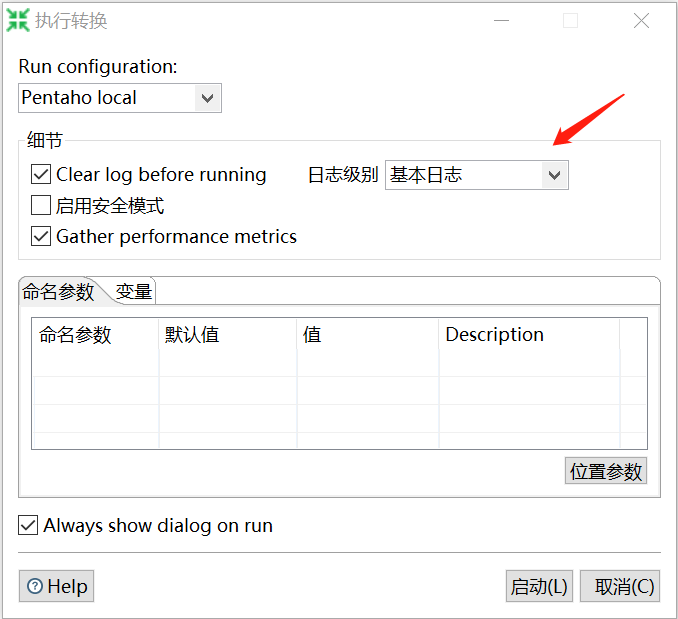
点击启动,日志级别这里可以选择错误日志,这样只记录错误信息
转换输出栏如下图:

最后检测两边表,如记录数count(*)、表中数据对比等没问题的话表示转换完成。
2.5 kettle运行的一些优化
本地跑kettle速度不是很给力,查了资料做了些优化。
2.5.1 修改JVM内存大小
JVM初始分配的内存由-Xms指定,默认是物理内存的1/64;JVM最大分配的内存由-Xmx指 定,默认是物理内存的1/4。默认空余堆内存小于 40%时,JVM就会增大堆直到-Xmx的最大限制;空余堆内存大于70%时,JVM会减少堆直到-Xms的最小限制。因此服务器一般设置-Xms、 -Xmx相等以避免在每次GC 后调整堆的大小。可以利用JVM提供的-Xmn -Xms -Xmx等选项可进行堆内存设置,一般的要将-Xms和-Xmx选项设置为相同,而-Xmn为1/4的-Xmx值,建议堆的最大值设置为可用内存的最大值的80%。
本机内存8G,修改spoon.bat 相关参数如下:
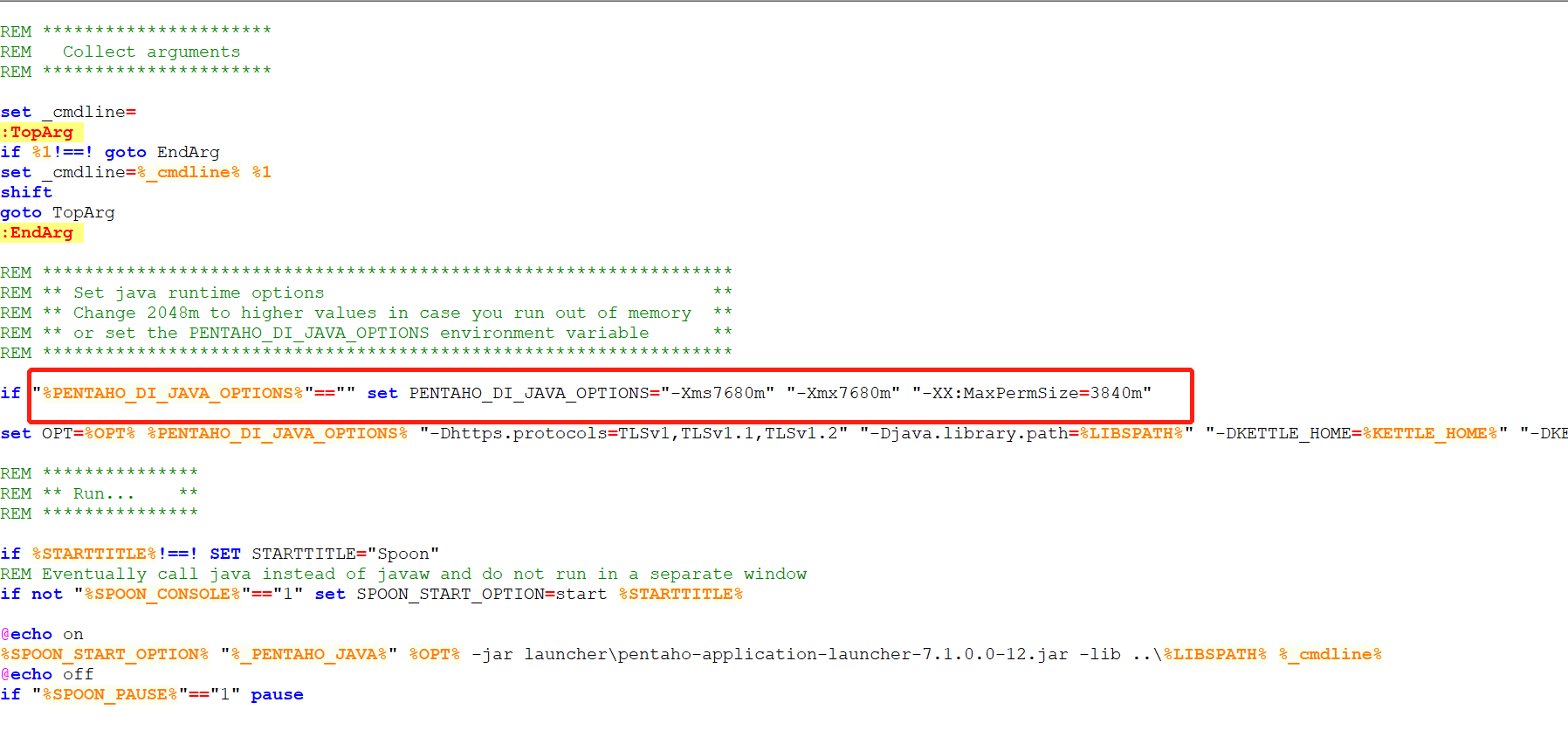
修改完效率不是很高,但是略微能提升一点读写性能。
2.5.2 表输出设置多线程
表输入和表输出都可以设置多线程,但是【表输入】开启多线程容易造成数据重复,比如select * from table设置为3,就会迁移3份重复数据,故只设置表输出:


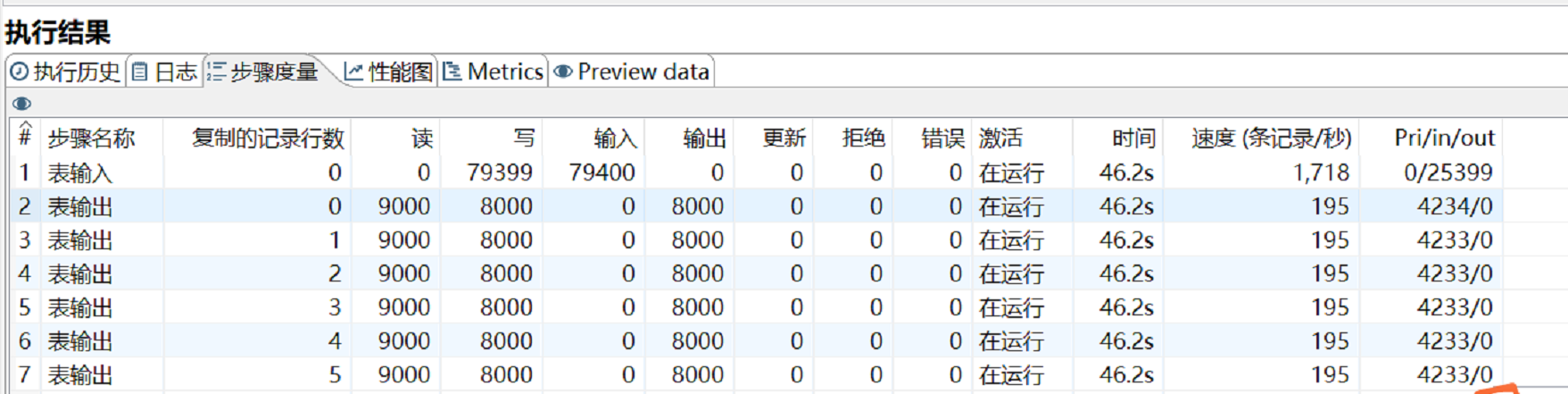
数字8就代表开启了8个输出线程,开启后速度明显提升不少。
2.5.3 修改输出参数
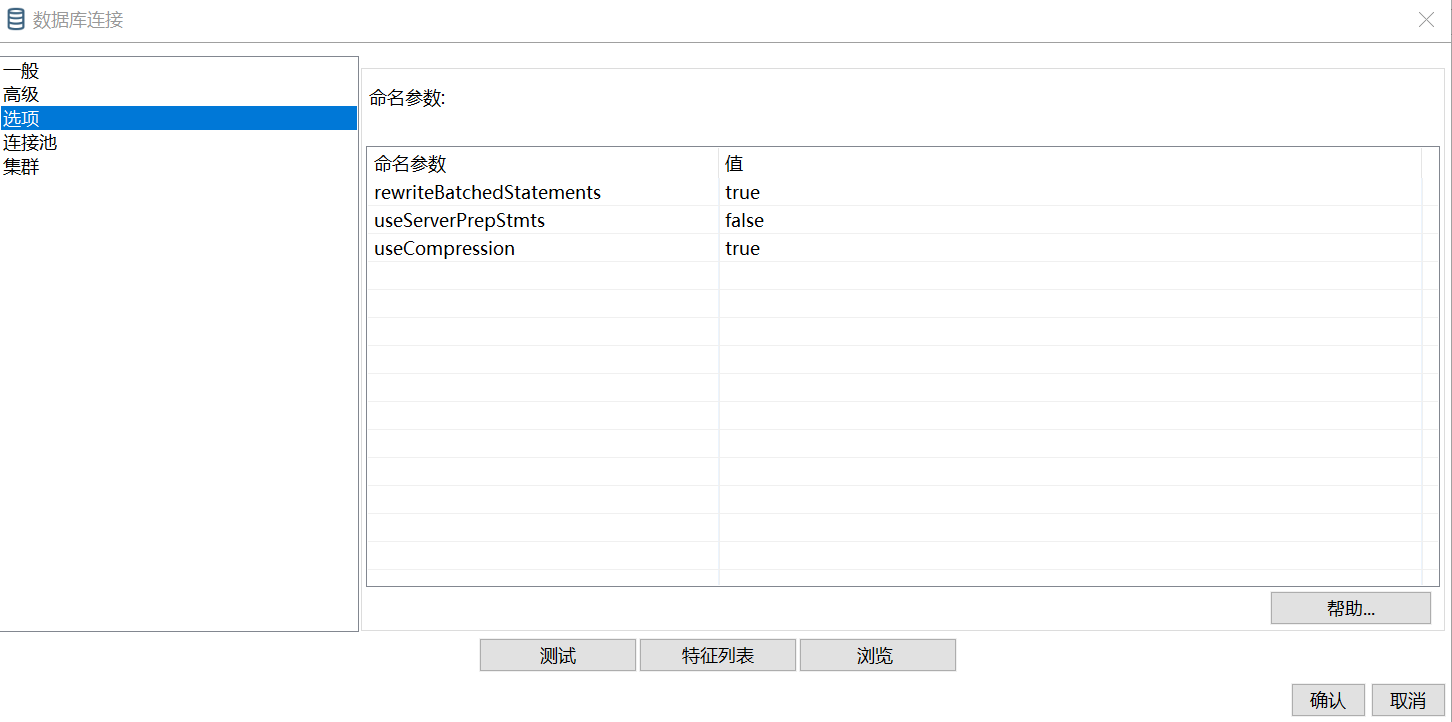
mysql表输出的时候出现减速的原因可能是因为网络链接的属性设置
在此处添加参数:
useServerPrepStmts=false
rewriteBatchedStatements=true
useCompression=true
如图:
以上就是在windows上使用kettle的一些心得,但是考虑到表数据量太大,故而后续把kettle转换配置放在linux 服务器跑了,速度得到大大提升,将在下一篇说明。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号