
20145211 《信息安全系统设计基础》第十三周学习总结
20145211《信息安全系统设计基础》第十三周学习总结——让岩石泉涌,让沙漠开花
教材学习内容总结
网络编程
客户端-服务器编程模型
- 一个应用是由一个服务器进程和一个或多个客户端进程组成
- 服务器进程 -> 管理某种资源 -> 通过操作这种资源来为它的客户端提供某种服务
- 基本操作:事务
- 一个客户端-服务器事务由四步组成:
- 当一个客户端需要服务时,向服务器发送一个请求,发起一个事务。
- 服务器收到请求后,解释它,并以适当的方式操作它的资源。
- 服务器给客户端发送一个相应,并等待下一个请求。
- 客户端收到响应并处理它。

- 客户端和服务器都是进程
网络
- 对主机而言,网络是一种I/O设备:从网络上接收到的数据从适配器经过I/O和存储器总线拷贝到存储器,典型地是通过DMA(直接存储器存取方式)传送。
- 物理上,网络是一个按照地理远近组成的层次系统:最低层是LAN(局域网),最流行的局域网技术是以太网。
- 以太网段
- 包括一些电缆和集线器。每根电缆都有相同的最大位带宽,集线器不加分辩地将一个端口上收到的每个位复制到其他所有的端口上,因此每台主机都能看到每个位。
- 每个以太网适配器都有一个全球唯一的48位地址,存储在适配器的非易失性存储器上。
- 一台主机可以发送一段位:帧,到这个网段内其它任何主机。每个帧包括一些固定数量的头部位(标识此帧的源和目的地址及帧长)和数据位(有效载荷)。每个主机都能看到这个帧,但是只有目的主机能读取。
- 使用电缆和网桥,多个以太网段可以连接成较大的局域网,称为桥接以太网。这些电缆的带宽可以是不同的。
- 多个不兼容的局域网可以通过叫做路由器的特殊计算机连接起来,组成一个internet互联网络。
- 互联网重要特性:由采用不同技术,互不兼容的局域网和广域网组成,并能使其相互通信。其中不同网络相互通信的解决办法是一层运行在每台主机和路由器上的协议软件,消除不同网络的差异。
- 协议提供的两种基本能力
- 命名机制:唯一的标示一台主机
- 传送机制:定义一种把数据位捆扎成不连续的片的同一方式
全球IP因特网
- TCP/IP协议族
- 因特网的客户端和服务器混合使用套接字接口函数和UnixI/O函数进行通信
- 把因特网看做一个世界范围的主机集合,满足以下特性:
- 主机集合被映射为一组32位的IP地址
- 这组IP地址被映射为一组称为因特网域名的标识符
- 因特网主机上的进程能够通过连接和任何其他主机上的进程
- 检索并打印一个DNS主机条目:
#include "csapp.h"
int main(int argc, char **argv)
{
char **pp;
struct in_addr addr;
struct hostent *hostp;
if (argc != 2) {
fprintf(stderr, "usage: %s <domain name or dotted-decimal>\n",
argv[0]);
exit(0);
}
if (inet_aton(argv[1], &addr) != 0)
hostp = Gethostbyaddr((const char *)&addr, sizeof(addr), AF_INET);
else
hostp = Gethostbyname(argv[1]);
printf("official hostname: %s\n", hostp->h_name);
for (pp = hostp->h_aliases; *pp != NULL; pp++)
printf("alias: %s\n", *pp);
for (pp = hostp->h_addr_list; *pp != NULL; pp++) {
addr.s_addr = ((struct in_addr *)*pp)->s_addr;
printf("address: %s\n", inet_ntoa(addr));
}
exit(0);
}
套接字接口
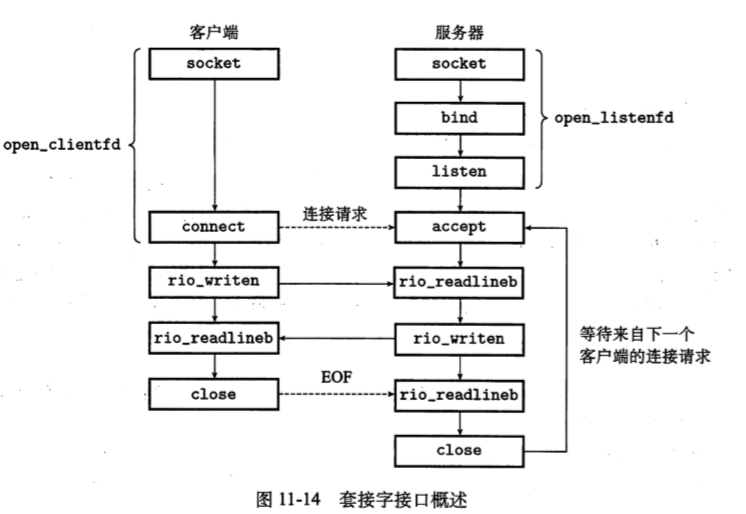
- 函数:
- socket函数
- connect函数
- open_clientfd函数
- bind函数
- listen函数
- open_listenfd函数
- accept函数
Web服务器
- Web客户端和服务器之间的交互用的是一个基于文本的应用级协议,叫做 HTTP (Hypertext Transfer Protocol,超文本传输协议). HTTP 是一个简单的协议。一个 Web 客户端(即浏览器) 打开一个到服务器的因特网连接,并且请求某些内容。服务器响应所请求的内容,然后关闭连接。浏览器读取这些内容,并把它显示在屏幕上。
- Web内容可以用一种叫做 HTML(Hypertext Markup Language,超文本标记语言)的语言来编写。一个 HTML 程序(页)包含指令(标记),它们告诉浏览器如何显示这页中的各种文本和图形对象。
- Web 服务器以两种不同的方式向客户端提供内容:
- 取一个磁盘文件,并将它的内容返回给客户端。磁盘文件称为静态内容 (static content), 而返回文件给客户端的过程称为服务静态内容 (serving static content)。
- 运行一个可执行文件,并将它的输出返回给客户端。运行时可执行文件产生的输出称为态内容 (dynamic content),而运行程序并返回它的输出到客户端的过程称为服务动态内容 (serving dynamic content)。
并发编程
- 并发:逻辑控制流在时间上重叠
- 并发程序:使用应用级并发的应用程序称为并发程序。
- 三种基本的构造并发程序的方法:
- 进程,用内核来调用和维护,有独立的虚拟地址空间,显式的进程间通信机制。
- I/O多路复用,应用程序在一个进程的上下文中显式的调度控制流。逻辑流被模型化为状态机。
- 线程,运行在一个单一进程上下文中的逻辑流。由内核进行调度,共享同一个虚拟地址空间。
基于进程的并发编程
- 构造并发服务器的自然方法就是,在父进程中接受客户端连接请求,然后创建一个新的子进程来为每个新客户端提供服务。
- 因为父子进程中的已连接描述符都指向同一个文件表表项,所以父进程关闭它的已连接描述符的拷贝是至关重要的,而且由此引起的存储器泄露将最终消耗尽可用的存储器,使系统崩溃。
- 基于进程的并发echo服务器的重点内容:
- 需要一个SIGCHLD处理程序,来回收僵死子进程的资源。
- 父子进程必须关闭各自的connfd拷贝。对父进程尤为重要,以避免存储器泄露。
- 套接字的文件表表项中的引用计数,直到父子进程的connfd都关闭了,到客户端的连接才会终止。
- 进程的模型:共享文件表,但不是共享用户地址空间。
- 关于进程的优劣:
- 优点:一个进程不可能不小心覆盖两一个进程的虚拟存储器。
- 缺点:独立的地址空间使得进程共享状态信息变得更加困难。进程控制和IPC的开销很高。
- Unix IPC是指所有允许进程和同一台主机上其他进程进行通信的技术,包括管道、先进先出(FIFO)、系统V共享存储器,以及系统V信号量。
基于I/O多路复用的并发编程
- echo服务器必须响应两个相互独立的I/O时间:
- 网络客户端发起连接请求
- 用户在键盘上键入命令行
- I/O多路复用技术的基本思路:使用select函数,要求内核挂起进程,只有在一个或多个I/O事件发生后,才将控制返回给应用程序。
- 将描述符集合看成是n位位向量:b(n-1),……b1,b0 ,每个位bk对应于描述符k,当且仅当bk=1,描述符k才表明是描述符集合的一个元素。可以做以下三件事:
- 分配它们;
- 将一个此种类型的变量赋值给另一个变量;
- 用FDZERO、FDSET、FDCLR和FDISSET宏指令来修改和检查它们。
-
echo函数:将来自科幻段的每一行回送回去,直到客户端关闭这个链接。
- 状态机就是一组状态、输入事件和转移,转移就是将状态和输入时间映射到状态,自循环是同一输入和输出状态之间的转移。
- 事件驱动器的设计优点:
- 比基于进程的设计给了程序员更多的对程序行为的控制
- 运行在单一进程上下文中,因此,每个逻辑流都能访问该进程的全部地址空间,使得流之间共享数据变得很容易。
- 不需要进程上下文切换来调度新的流。
- 缺点:
- 编码复杂
- 不能充分利用多核处理器
-
粒度:每个逻辑流每个时间片执行的指令数量。并发粒度就是读一个完整的文本行所需要的指令数量。
基于线程的并发编程
- 线程:运行在进程上下文中的逻辑流。
-
线程有自己的线程上下文,包括一个唯一的整数线程ID、栈、栈指针、程序计数器、通用目的寄存器和条件码。所有运行在一个进程里的线程共享该进程的整个虚拟地址空间。
线程执行模型
- 主线程:每个进程开始生命周期时都是单一线程。
- 对等线程:某一时刻,主线程创建的对等线程 。
- 线程与进程的不同:
- 线程的上下文切换要比进程的上下文切换快得多;
- 和一个进程相关的线程组成一个对等池,独立于其他线程创建的线程。
- 主线程和其他线程的区别仅在于它总是进程中第一个运行的线程。
- 对等池的影响
- 一个线程可以杀死它的任何对等线程;
- 等待它的任意对等线程终止;
-
每个对等线程都能读写相同的共享资源。
Posix线程
-
线程例程:线程的代码和本地数据被封装在一个线程例程中。每一个线程例程都以一个通用指针作为输入,并返回一个通用指针。
创建线程
-
pthread create函数创建一个新的线程,并带着一个输入变量arg,在新线程的上下文中运行线程例程f。新线程可以通过调用pthread _self函数来获得自己的线程ID。
终止线程
- 一个线程的终止方式:
- 当顶层的线程例程返回时,线程会隐式的终止;
-
通过调用pthread _exit函数,线程会显示地终止。如果主线程调用pthread _exit,它会等待所有其他对等线程终止,然后再终止主线程和整个进程。
回收已终止线程的资源
-
pthread _join函数会阻塞,直到线程tid终止,回收已终止线程占用的所有存储器资源。pthread _join函数只能等待一个指定的线程终止。
分离线程
- 在任何一个时间点上,线程是可结合的或者是分离的。一个可结合的线程能够被其他线程收回其资源和杀死;一个可分离的线程是不能被其他线程回收或杀死的。它的存储器资源在它终止时有系统自动释放。
- 默认情况下,线程被创建成可结合的,为了避免存储器漏洞,每个可集合的线程都应该要么被其他进程显式的回收,要么通过调用pthread _detach函数被分离。
初始化线程
- pthread _once函数允许初始化与线程例程相关的状态。
- once _control变量是一个全局或者静态变量,总是被初始化为PTHREAD _ONCE _INIT.
一个基于线程的并发服务器
- 对等线程的赋值语句和主线程的accept语句之间引入了竞争。
多线程程序中的变量共享
线程存储器模型
- 每个线程和其他线程一起共享进程上下文的剩余部分。包括整个用户虚拟地址空间,是由只读文本、读/写数据、堆以及所有的共享库代码和数据区域组成的。线程也共享同样的打开文件的集合。
-
任何线程都可以访问共享虚拟存储器的任意位置。寄存器是从不共享的,而虚拟存储器总是共享的。
将变量映射到存储器
- 全局变量:虚拟存储器的读/写区域只会包含每个全局变量的一个实例。
- 本地自动变量:定义在函数内部但没有static属性的变量。
-
本地静态变量:定义在函数内部并有static属性的变量。
共享变量
-
变量v是共享的,当且仅当它的一个实例被一个以上的线程引用。
用信号量同步线程
- 共享变量引入了同步错误的可能性。
- 线程i的循环代码分解为五部分:
- Hi:在循环头部的指令块
- Li:加载共享变量cnt到寄存器%eax的指令,%eax表示线程i中的寄存器%eax的值
- Ui:更新(增加)%eax的指令
- Si:将%eaxi的更新值存回到共享变量cnt的指令
- Ti:循环尾部的指令块。
进度图
- 进度图将指令执行模式化为从一种状态到另一种状态的转换。转换被表示为一条从一点到相邻点的有向边。合法的转换是向右或者向上。
- 临界区:对于线程i,操作共享变量cnt内容的指令构成了一个临界区。
- 互斥的访问:确保每个线程在执行它的临界区中的指令时,拥有对共享变量的互斥的访问。
- 安全轨迹线:绕开不安全区的轨迹线
不安全轨迹线:接触到任何不安全区的轨迹线就叫做不安全轨迹线 - 任何安全轨迹线都能正确的更新共享计数器。
信号量
- 当有多个线程在等待同一个信号量时,你不能预测V操作要重启哪一个线程。
- 信号量不变性:一个正在运行的程序绝不能进入这样一种状态,也就是一个正确初始化了的信号量有一个负值。
使用信号量来实现互斥
- 二元信号量:将每个共享变量与一个信号量s联系起来,然后用P(S)和V(s)操作将这种临界区包围起来,这种方式来保护共享变量的信号量。
- 互斥锁:以提供互斥为目的的二元信号量
- 加锁:一个互斥锁上执行P操作称为对互斥锁加锁,执行V操作称为对互斥锁解锁。对一个互斥锁加了锁但还没有解锁的线程称为占用了这个互斥锁。
- 计数信号量:一个呗用作一组可用资源的计数器的信号量
利用信号量来调度共享资源
- 信号量的作用:(1)提供互斥(2)调度对共享资源的访问
- 生产者—消费者问题:生产者产生项目并把他们插入到一个有限的缓冲区中,消费者从缓冲区中取出这些项目,然后消费它们。
- 读者—写者问题:
- 读者优先,要求不让读者等待,除非已经把使用对象的权限赋予了一个写者。
- 写者优先,要求一旦一个写者准备好可以写,它就会尽可能地完成它的写操作。
- 饥饿就是一个线程无限期地阻塞,无法进展。
使用线程提高并行性
- 写顺序程序只有一条逻辑流,写并发程序有多条并发流,并行程序是一个运行在多个处理器上的并发程序。并行程序的集合是并发程序集合的真子集。
其他并发问题
线程安全
- 线程安全:当且仅当被多个并发线程反复地调用时,它会一直产生正确的结果。
- 线程不安全:如果一个函数不是线程安全的,就是线程不安全的。
- 线程不安全的类:
- 不保护共享变量的函数
- 保持跨越多个调用的状态的函数。
- 返回指向静态变量的指针的函数。解决办法:重写函数和加锁拷贝。
- 调用线程不安全函数的函数。
可重入性
- 可重入函数:当它们被多个线程调用时,不会引用任何共享数据。可重入函数是线程安全函数的一个真子集 。
- 关键思想是我们用一个调用者传递进来的指针取代了静态的next变量。
- 显式可重入:没有指针,没有引用静态或全局变量
- 隐式可重入:允许它们传递指针
- 可重入性即使调用者也是被调用者的属性,并不只是被调用者单独的属性。
在线程化的程序中使用已存在的库函数
- 使用线程不安全函数的可重入版本,名字以_r为后缀结尾。
竞争
- 竞争:当一个程序的正确性依赖于一个线程要在另一个线程到达y点之前到达它的控制流中的x点时,就会发生竞争。
- 线程化的程序必须对任何可行的轨迹线都正确工作。
- 消除方法:动态的为每个整数ID分配一个独立的块,并且传递给线程例程一个指向这个块的指针
死锁
- 死锁:一组线程被阻塞了,等待一个永远也不会为真的条件。
- 程序员使用P和V操作不当,以至于两个信号量的禁止区域重叠。
- 重叠的禁止区域引起了一组称为死锁区域的状态。
- 死锁是不可预测的。
实践
condvar.c
#include <stdlib.h>
#include <pthread.h>
#include <stdlib.h>
typedef struct _msg{
struct _msg * next;
int num;
} msg;
msg *head;
pthread_cond_t has_product = PTHREAD_COND_INITIALIZER;
pthread_mutex_t lock = PTHREAD_MUTEX_INITIALIZER;
void *consumer ( void * p )
{
msg * mp;
for( ;; ) {
pthread_mutex_lock( &lock );
while ( head == NULL )
pthread_cond_wait( &has_product, &lock );
mp = head;
head = mp->next;
pthread_mutex_unlock ( &lock );
printf( "Consume %d tid: %d\n", mp->num, pthread_self());
free( mp );
sleep( rand() % 5 );
}
}
void *producer ( void * p )
{
msg * mp;
for ( ;; ) {
mp = malloc( sizeof(msg) );
pthread_mutex_lock( &lock );
mp->next = head;
mp->num = rand() % 1000;
head = mp;
printf( "Produce %d tid: %d\n", mp->num, pthread_self());
pthread_mutex_unlock( &lock );
pthread_cond_signal( &has_product );
sleep ( rand() % 5);
}
}
int main(int argc, char *argv[] )
{
pthread_t pid1, cid1;
pthread_t pid2, cid2;
srand(time(NULL));
pthread_create( &pid1, NULL, producer, NULL);
pthread_create( &pid2, NULL, producer, NULL);
pthread_create( &cid1, NULL, consumer, NULL);
pthread_create( &cid2, NULL, consumer, NULL);
pthread_join( pid1, NULL );
pthread_join( pid2, NULL );
pthread_join( cid1, NULL );
pthread_join( cid2, NULL );
return 0;
}-
运行结果:
![]()
- 不知道为啥都是负的。。讲道理不应该。。
- 消费者等待生产者产出产品后才打印,否则消费者阻塞等待生产者生产。
- 线程间同步的一种情况:线程A需要等某个条件成立才能继续往下执行,现在这个条件不成立,线程A就阻塞等待,而线程B在执行过程中使这个条件成立了,就唤醒线程A继续执行。
-
在pthread库中通过条件变量(Condition Variable)来阻塞等待一个条件,或者唤醒等待这个条件的线程。
- wait函数中condtion是和mutext一起使用的,基本流程如下:
- 消费者获取资源锁,如果当前无可用资源则调用cond_wait函数释放锁,并等待condtion通知。
- 生产者产生资源后,获取资源锁,放置资源后嗲用cond_signal函数通知。并释放资源锁。
- 消费者的cond_wait函数等到condtion通知后,重新获取资源锁,消费资源后再次释放资源锁。
- 从代码中可以看到,mutex用于保护资源,wait函数用于等待信号,signal函数用于通知信号。其中wait函数中有一次对mutex的释放和重新获取操作,因此生产者和消费者并不会出现死锁。

count.c
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
#define NLOOP 5000
int counter;
void *doit( void * );
int main(int argc, char **argv)
{
pthread_t tidA, tidB;
pthread_create( &tidA ,NULL, &doit, NULL );
pthread_create( &tidB ,NULL, &doit, NULL );
pthread_join( tidA, NULL );
pthread_join( tidB, NULL );
return 0;
}
void * doit( void * vptr)
{
int i, val;
for ( i=0; i<NLOOP; i++ ) {
val = counter++;
printf("%x: %d \n", (unsigned int) pthread_self(), val + 1);
counter = val + 1;
}
}-
运行结果:
![]()
-
这是一个不加锁的创建两个线程共享同一变量都实现加一操作的程序,在这个程序中虽然每个线程都给count加了5000,但是结果出现了互相覆盖。

countwithmutex.c
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
#define NLOOP 5000
int counter;
pthread_mutex_t counter_mutex = PTHREAD_MUTEX_INITIALIZER;
void *doit( void * );
int main(int argc, char **argv)
{
pthread_t tidA, tidB;
pthread_create( &tidA ,NULL, &doit, NULL );
pthread_create( &tidB ,NULL, &doit, NULL );
pthread_join( tidA, NULL );
pthread_join( tidB, NULL );
return 0;
}
void * doit( void * vptr)
{
int i, val;
for ( i=0; i<NLOOP; i++ ) {
pthread_mutex_lock( &counter_mutex );
val = counter++;
printf("%x: %d \n", (unsigned int) pthread_self(), val + 1);
counter = val + 1;
pthread_mutex_unlock( &counter_mutex );
}
return NULL;
}-
运行结果:
![]()
-
这次的运行结果和我们期望的就是一样的,因此对于多线程的程序,访问冲突的问题是很普遍的,解决的办法就是引入互斥锁(Mutex),获得锁的线程可以完成”读-修改-写”的操作,然后释放锁给其它线程,没有获得锁的线程只能等待而不能访问共享数据,这样”读-修改-写”三步操作组成一个原子操作,要么都执行,要么都不执行,不会执行到中间被打断,也不会在其它处理器上并行做这个操作。

cp_t.c
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <sys/types.h>
#include <fcntl.h>
#include <unistd.h>
#include <sys/mman.h>
#include <pthread.h>
typedef struct {
char *src_address;
char *dest_address;
int len;
} arg_t;
static void err_sys(const char *s);
static int get_file_length(int fd);
static int extend(int fd, int len);
arg_t map_src_dest(const char *src, const char *dest);
static void *cpy(void *arg);
void divide_thread(int pnum, arg_t arg_file);
int main(int argc, char *argv[])
{
arg_t arg_file;
if (argc != 4) {
fprintf(stderr, "Usage:%s file1 file2 thread_num", argv[0]);
exit(1);
}
arg_file = map_src_dest(argv[1], argv[2]);
divide_thread(atoi(argv[3]), arg_file);
munmap(arg_file.src_address, arg_file.len);
munmap(arg_file.dest_address, arg_file.len);
return 0;
}
static void err_sys(const char *s)
{
perror(s);
exit(1);
}
static int get_file_length(int fd)
{
int position = lseek(fd, 0, SEEK_CUR);
int length = lseek(fd, 0, SEEK_END);
lseek(fd, position, SEEK_SET);
return length;
}
static int extend(int fd, int len)
{
int file_len = get_file_length(fd);
if (file_len >= len) {
return -1;
}
lseek(fd, len - file_len - 1, SEEK_END);
write(fd, "", 1);
return 0;
}
arg_t map_src_dest(const char *src, const char *dest)
{
int fd_src, fd_dest, len;
char *src_address, *dest_address;
arg_t arg_file;
fd_src = open(src, O_RDONLY);
if (fd_src < 0) {
err_sys("open src");
}
len = get_file_length(fd_src);
src_address = mmap(NULL, len, PROT_READ, MAP_SHARED, fd_src, 0);
if (src_address == MAP_FAILED) {
err_sys("mmap src");
}
close(fd_src);
fd_dest = open(dest, O_RDWR | O_CREAT | O_TRUNC, 0644);
if (fd_dest < 0) {
err_sys("open dest");
}
extend(fd_dest, len);
dest_address = mmap(NULL, len, PROT_WRITE, MAP_SHARED, fd_dest, 0);
if (dest_address == MAP_FAILED) {
err_sys("mmap dest");
}
close(fd_dest);
arg_file.len = len;
arg_file.src_address = src_address;
arg_file.dest_address = dest_address;
return arg_file;
}
static void *cpy(void *arg)
{
char *src_address, *dest_address;
int len;
src_address = ((arg_t *) arg)->src_address;
dest_address = ((arg_t *) arg)->dest_address;
len = ((arg_t *) arg)->len;
memcpy(dest_address, src_address, len);
return NULL;
}
void divide_thread(int pnum, arg_t arg_file)
{
int i, len;
char *src_address, *dest_address;
pthread_t *pid;
arg_t arg[pnum];
len = arg_file.len;
src_address = arg_file.src_address;
dest_address = arg_file.dest_address;
pid = malloc(pnum * sizeof(pid));
if (pnum > len) {
fprintf(stderr,
"too many threads, even larger than length, are you crazy?!\n");
exit(1);
}
for (i = 0; i < pnum; i++) {
arg[i].src_address = src_address + len / pnum * i;
arg[i].dest_address = dest_address + len / pnum * i;
if (i != pnum - 1) {
arg[i].len = len / pnum;
} else {
arg[i].len = len - len / pnum * i;
}
pthread_create(&pid[i], NULL, cpy, &arg[i]);
}
for (i = 0; i < pnum; i++) {
pthread_join(pid[i], NULL);
}
free(pid);
}-
用法:./cp_t [源文件名] [目的文件名] [创建线程数
semphore.c
#include <stdio.h>
#include <pthread.h>
#include <stdlib.h>
#include <semaphore.h>
#define NUM 5
int queue[NUM];
sem_t blank_number, product_number;
void *producer ( void * arg )
{
static int p = 0;
for ( ;; ) {
sem_wait( &blank_number );
queue[p] = rand() % 1000;
printf("Product %d \n", queue[p]);
p = (p+1) % NUM;
sleep ( rand() % 5);
sem_post( &product_number );
}
}
void *consumer ( void * arg )
{
static int c = 0;
for( ;; ) {
sem_wait( &product_number );
printf("Consume %d\n", queue[c]);
c = (c+1) % NUM;
sleep( rand() % 5 );
sem_post( &blank_number );
}
}
int main(int argc, char *argv[] )
{
pthread_t pid, cid;
sem_init( &blank_number, 0, NUM );
sem_init( &product_number, 0, 0);
pthread_create( &pid, NULL, producer, NULL);
pthread_create( &cid, NULL, consumer, NULL);
pthread_join( pid, NULL );
pthread_join( cid, NULL );
sem_destroy( &blank_number );
sem_destroy( &product_number );
return 0;
}-
运行结果:
![]()
-
semaphore表示信号量,semaphore变量的类型为sem_t,sem_init()初始化一个semaphore变量,value参数表示可用资源 的数量,pshared参数为0表示信号量用于同一进程的线程间同步。在用完semaphore变量之后应该调用sem_destroy()释放与semaphore相关的资源。调用sem_wait()可以获得资源,使semaphore的值减1,如果调用sem_wait()时semaphore的值已 经是0,则挂起等待。如果不希望挂起等待,可以调用sem_trywait()。调用sem_post()可以释放资 源,使semaphore的值加1,同时唤醒挂起等待的线程。

share.c
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
#include <unistd.h>
char buf[BUFSIZ];
void *thr_fn1( void *arg )
{
printf("thread 1 returning %d\n", getpid());
printf("pwd:%s\n", getcwd(buf, BUFSIZ));
*(int *)arg = 11;
return (void *) 1;
}
void *thr_fn2( void *arg )
{
printf("thread 2 returning %d\n", getpid());
printf("pwd:%s\n", getcwd(buf, BUFSIZ));
pthread_exit( (void *) 2 );
}
void *thr_fn3( void *arg )
{
while( 1 ){
printf("thread 3 writing %d\n", getpid());
printf("pwd:%s\n", getcwd(buf, BUFSIZ));
sleep( 1 );
}
}
int n = 0;
int main( void )
{
pthread_t tid;
void *tret;
pthread_create( &tid, NULL, thr_fn1, &n);
pthread_join( tid, &tret );
printf("n= %d\n", n );
printf("thread 1 exit code %d\n", (int) tret );
pthread_create( &tid, NULL, thr_fn2, NULL);
pthread_join( tid, &tret );
printf("thread 2 exit code %d\n", (int) tret );
pthread_create( &tid, NULL, thr_fn3, NULL);
sleep( 3 );
pthread_cancel(tid);
pthread_join( tid, &tret );
printf("thread 3 exit code %d\n", (int) tret );
}
-
运行结果:
![]()
-
该代码主要是为了获得线程的终止状态,thr_fn 1,thr_fn 2和thr_fn 3三个函数对应终止线程的三种方法,即从线程函数return,调用pthread_exit终止自己和调用pthread_cancel终止同一进程中的另一个线程。

心得体会
春寒暮树,挂着季子的剑;而今确是寒冬,时见幽人独往来,飘缈孤鸿影。梦幻中,总是信手可让岩石泉涌,让沙漠开花;怎奈斯人已逝。难道能从无情的寒冬,吸取比冰和剑更震撼人心的的快乐不成?
3次实验代码分析博客链接
20145211《信息安全系统设计基础》实验二 固件设计
20145211《信息安全系统设计基础》实验四 驱动程序设计
20145211《信息安全系统设计基础》实验五 网络通信
本周代码托管截图
- 代码托管链接:click here
- 代码行数统计:
![]()

学习进度条
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 目标 | 5000行 | 30篇 | 400小时 | |
| 第一周 | 120/200 | 1/2 | 16/16 | 学习Linux核心命令 |
| 第二周 | 100/200 | 1/3 | 30/46 | 学习vim,gcc以及gdb的基本操作 |
| 第三周 | 30/230 | 1/4 | 15/61 | 对信息的表示和处理有更深入的理解 |
| 第四周 | 30/260 | 1/5 | 22/83 | 双系统的探索 |
| 第五周 | 130/390 | 1/6 | 25/108 | 汇编的深入学习 |
| 第六周 | 60/450 | 1/7 | 25/133 | 熟悉了Y86模拟器 |
| 第七周 | 60/510 | 2/9 | 20/153 | 掌握局部性原理 |
| 第八周 | 0/510 | 2/11 | 16/169 | 期中总结 |
| 第九周 | 132/642 | 1/12 | 21/190 | 深入理解系统级I/O |
| 第十周 | 132/642 | 1/13 | 20/210 | 对常用指令代码进行深入理解 |
| 第十一周 | 1003/1645 | 1/14 | 26/236 | 对系统调用有了更深的认识 |
| 第十二周 | 50/1695 | 3/17 | 20/256 | 深入学习前几章代码并思考 |
| 第十三周 | 1001/ 2696 | 1/18 | 20/276 | 熟悉网络编程,加深对多线程的理解 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号