Kafka源码阅读(14)-Controller之副本状态机ReplicaStateMachine
基于开源 kafka 2.5 版本。
如无特殊说明,文中代码片段将删除 debug 信息、异常触发、英文注释等代码,以便观看核心代码。
在上一篇中,多次出现了分区/副本状态机的身影,当时我们只知道,只需要将分区/副本状态转换成功后就可以对外提供服务了,但是并没有深究到底什么是“状态转换”,这篇就来聊聊其中的副本状态机这个组件。
副本状态机通过broker、分区等当前状态来给副本赋上一个当前的状态,这么做的目的其实是只需要通过状态机这么一个组件,就能去转换和获取当前副本的状态,而不需要去很麻烦地去访问好几个不同的组件,让副本状态管理收口在一个ReplicaStateManchine类中,让代码更加清晰简洁。
状态定义
副本状态机定义了以下7个状态:
- NewReplica:副本新创建的状态
- OnlineReplica:副本在线状态,在这个状态下,副本可以接收“成为leader”或者“成为follower”请求
- OfflineReplica:副本离线状态,当broker宕机的时候就会变成这个状态
- ReplicaDeletionStarted:副本正在删除状态
- ReplicaDeletionSuccessful:副本删除成功状态,当副本在broker上物理删除成功后进入该状态
- ReplicaDeletionIneligible:副本已经开启了删除,但暂时无法被删除(比如broker下线)。设置成这个状态以便后续重试删除
- NonExistentReplica:副本不存在状态,在ReplicaDeletionSuccessful状态下,进一步地从分区副本分配信息中移除该副本后进入该状态
状态图如下:
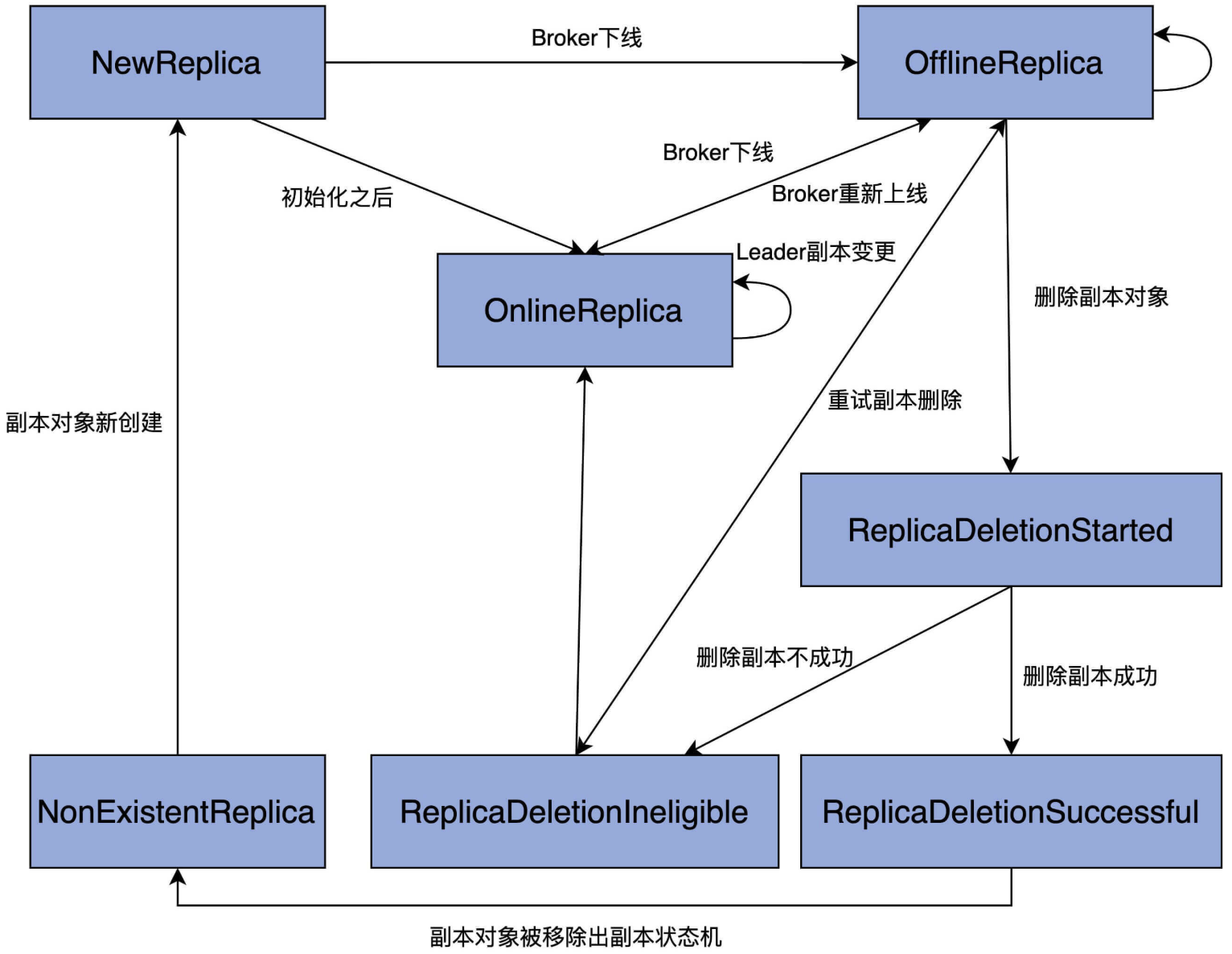
图中的单向箭头表示只允许单向状态转换,双向箭头则表示转换方向可以是双向的。比如,OnlineReplica和OfflineReplica之间有一根双向箭头,这就说明,副本可以在OnlineReplica和OfflineReplica状态之间随意切换。
结合这张图,我再详细解释下各个状态的含义,以及它们的流转过程。
当副本对象首次被创建出来后,它会被置于NewReplica状态。经过一番初始化之后,当副本对象能够对外提供服务之后,状态机会将其调整为OnlineReplica,并一直以该状态持续工作。
如果副本所在的Broker关闭或者是因为其他原因不能正常工作了,副本需要从OnlineReplica变更为OfflineReplica,表明副本已处于离线状态。
一旦开启了如删除主题这样的操作,状态机会将副本状态跳转到ReplicaDeletionStarted,以表明副本删除已然开启。倘若删除成功,则置为ReplicaDeletionSuccessful,倘若不满足删除条件(如所在Broker处于下线状态),那就设置成ReplicaDeletionIneligible,以便后面重试。
当副本对象被删除后,其状态会变更为NonExistentReplica,副本状态机将移除该副本数据。
这就是一个基本的状态管理流程。
ReplicaStateMachine
首先看一下副本状态机这个抽象类,负责管理 kafka 分区副本的状态机:
abstract class ReplicaStateMachine(controllerContext: ControllerContext) extends Logging {
// 在控制器选举成功后调用
def startup()
// 在控制器关闭时调用
def shutdown()
// 初始化所有分区副本的状态
private def initializeReplicaState()
// 处理状态变更的抽象方法
def handleStateChanges(replicas: Seq[PartitionAndReplica], targetState: ReplicaState)
}
前三个方法在抽象类中已经有实现:
// startup分为两步走:
// 1. initializeReplicaState初始化元数据缓存中这些副本的状态
// 2. handleStateChanges真正执行转换这些副本的状态
def startup(): Unit = {
initializeReplicaState()
val (onlineReplicas, offlineReplicas) = controllerContext.onlineAndOfflineReplicas
handleStateChanges(onlineReplicas.toSeq, OnlineReplica)
handleStateChanges(offlineReplicas.toSeq, OfflineReplica)
}
private def initializeReplicaState(): Unit = {
// 遍历所有副本
controllerContext.allPartitions.foreach { partition =>
val replicas = controllerContext.partitionReplicaAssignment(partition)
replicas.foreach { replicaId =>
val partitionAndReplica = PartitionAndReplica(partition, replicaId)
if (controllerContext.isReplicaOnline(replicaId, partition)) {
// 状态标记为OnlineReplica
controllerContext.putReplicaState(partitionAndReplica, OnlineReplica)
} else {
// startup方法是controller在进行故障转移的时候才调用的,此时可能会有broker宕机,而新controller又无法及时监听到broker宕机的情况,导致没有将副本状态及时转换为ReplicaDeletionIneligible
// 因此采用最保守的做法,当controller故障转移时先将这些副本直接标记为较为安全的ReplicaDeletionIneligible
controllerContext.putReplicaState(partitionAndReplica, ReplicaDeletionIneligible)
}
}
}
}
// 关闭状态机,没什么要做的
def shutdown(): Unit = {
info("Stopped replica state machine")
}
ZkReplicaStateMachine
就剩最后一个方法了,(哈哈,实际上里面还调用了好几个私有方法)。讲解方法前先看看这个类的一些成员字段:
class ZkReplicaStateMachine(
config: KafkaConfig,
stateChangeLogger: StateChangeLogger,
controllerContext: ControllerContext,
zkClient: KafkaZkClient,
// 用于给集群发送控制类请求
controllerBrokerRequestBatch: ControllerBrokerRequestBatch
) extends ReplicaStateMachine(controllerContext) with Logging
前几个字段不必多说,最后的controllerBrokerRequestBatch是一个helper类,用于给集群broker批量地发送请求。
// 将副本的状态变更为targetState
override def handleStateChanges(replicas: Seq[PartitionAndReplica], targetState: ReplicaState): Unit = {
if (replicas.nonEmpty) {
try {
controllerBrokerRequestBatch.newBatch()
// 按broker遍历
replicas.groupBy(_.replica).foreach { case (replicaId, replicas) =>
// 对broker上的副本进行状态变更
// 期间会产生多条控制类请求,均暂存在controllerBrokerRequestBatch中
doHandleStateChanges(replicaId, replicas, targetState)
}
// 将控制类请求批量地发送给该broker
controllerBrokerRequestBatch.sendRequestsToBrokers(controllerContext.epoch)
} catch {
case e: ControllerMovedException =>
error(s"Controller moved to another broker when moving some replicas to $targetState state", e)
throw e
case e: Throwable => error(s"Error while moving some replicas to $targetState state", e)
}
}
}
重头戏在doHandleStateChanges这个方法中,不同的目标状态由不同的case分支进行处理,代码整体结构如下:
private def doHandleStateChanges(replicaId: Int, replicas: Seq[PartitionAndReplica], targetState: ReplicaState): Unit = {
// 对于元数据缓存中不存在的副本,状态初始化为NonExistentReplica
replicas.foreach(replica => controllerContext.putReplicaStateIfNotExists(replica, NonExistentReplica))
val (validReplicas, invalidReplicas) = controllerContext.checkValidReplicaStateChange(replicas, targetState)
// 对于非法状态转换,打印一下
invalidReplicas.foreach(replica => logInvalidTransition(replica, targetState))
// 处理合法的状态转换
targetState match {
case NewReplica => // ...
case OnlineReplica => // ...
case OfflineReplica => // ...
case ReplicaDeletionStarted => // ...
case ReplicaDeletionIneligible => // ...
case ReplicaDeletionSuccessful => // ...
case NonExistentReplica => // ...
}
}
为了方便阅读,我们将不同分支各自单独拎出来讲。
转入NewReplica
case NewReplica =>
// 遍历待处理副本
validReplicas.foreach { replica =>
// 获取副本所在的分区以及副本当前状态
val partition = replica.topicPartition
val currentState = controllerContext.replicaState(replica)
// 尝试获取分区的信息(包括分区leader、ISR、controller epoch等)
controllerContext.partitionLeadershipInfo.get(partition) match {
// 拿到分区的信息
case Some(leaderIsrAndControllerEpoch) =>
if (leaderIsrAndControllerEpoch.leaderAndIsr.leader == replicaId) {
// leader副本,leader是不能转入NewReplica状态的,打印错误日志
val exception = new StateChangeFailedException(s"Replica $replicaId for partition $partition cannot be moved to NewReplica state as it is being requested to become leader")
logFailedStateChange(replica, currentState, OfflineReplica, exception)
} else {
// 普通副本,通知副本所在broker处理该新副本,并通知集群所有broker更新元数据
controllerBrokerRequestBatch.addLeaderAndIsrRequestForBrokers(Seq(replicaId),
replica.topicPartition,
leaderIsrAndControllerEpoch,
controllerContext.partitionFullReplicaAssignment(replica.topicPartition),
isNew = true)
logSuccessfulTransition(replicaId, partition, currentState, NewReplica)
// 元数据中副本状态更新为NewReplica
controllerContext.putReplicaState(replica, NewReplica)
}
// 没拿到分区的信息
case None =>
// 元数据中副本状态更新为NewReplica
logSuccessfulTransition(replicaId, partition, currentState, NewReplica)
controllerContext.putReplicaState(replica, NewReplica)
}
}
转入OnlineReplica
case OnlineReplica =>
// 遍历待处理副本
validReplicas.foreach { replica =>
// 获取副本所在的分区以及副本当前状态
val partition = replica.topicPartition
val currentState = controllerContext.replicaState(replica)
currentState match {
// 如果是从NewReplica转入OnlineReplica
case NewReplica =>
// 获取分区对应的副本信息
val assignment = controllerContext.partitionFullReplicaAssignment(partition)
// 如果元信息缓存显示分区不包含副本,那么将其加入
if (!assignment.replicas.contains(replicaId)) {
error(s"Adding replica ($replicaId) that is not part of the assignment $assignment")
val newAssignment = assignment.copy(replicas = assignment.replicas :+ replicaId)
controllerContext.updatePartitionFullReplicaAssignment(partition, newAssignment)
}
// 如果是从其它状态转入OnlineReplica
case _ =>
controllerContext.partitionLeadershipInfo.get(partition) match {
case Some(leaderIsrAndControllerEpoch) =>
// 通知副本所在broker处理该副本,并通知集群所有broker更新元数据
controllerBrokerRequestBatch.addLeaderAndIsrRequestForBrokers(Seq(replicaId),
replica.topicPartition,
leaderIsrAndControllerEpoch,
controllerContext.partitionFullReplicaAssignment(partition), isNew = false)
case None =>
}
}
logSuccessfulTransition(replicaId, partition, currentState, OnlineReplica)
// 元数据中副本状态更新为OnlineReplica
controllerContext.putReplicaState(replica, OnlineReplica)
}
值得注意的是,从NewReplica转入OnlineReplica不需要发送请求,我理解是因为之前NewReplica状态的时候已经发过一次,因此不需要再发。而从其他状态转入OnlineReplica,比如broker宕机重启,就会从OfflineReplica转入OnlineReplica,此时就需要主动发送请求通知broker。
转入OfflineReplica
case OfflineReplica =>
// 通知这些副本所在broker停止副本,不再从leader那里复制数据
validReplicas.foreach { replica =>
controllerBrokerRequestBatch.addStopReplicaRequestForBrokers(Seq(replicaId), replica.topicPartition, deletePartition = false)
}
// 将副本分为所在分区有leader信息的副本集合,以及无leader信息的副本集合
val (replicasWithLeadershipInfo, replicasWithoutLeadershipInfo) = validReplicas.partition { replica =>
controllerContext.partitionLeadershipInfo.contains(replica.topicPartition)
}
// 对有leader的副本,将副本从分区的ISR中移除
val updatedLeaderIsrAndControllerEpochs = removeReplicasFromIsr(replicaId, replicasWithLeadershipInfo.map(_.topicPartition))
updatedLeaderIsrAndControllerEpochs.foreach { case (partition, leaderIsrAndControllerEpoch) =>
if (!controllerContext.isTopicQueuedUpForDeletion(partition.topic)) {
val recipients = controllerContext.partitionReplicaAssignment(partition).filterNot(_ == replicaId)
controllerBrokerRequestBatch.addLeaderAndIsrRequestForBrokers(recipients,
partition,
leaderIsrAndControllerEpoch,
controllerContext.partitionFullReplicaAssignment(partition), isNew = false)
}
val replica = PartitionAndReplica(partition, replicaId)
val currentState = controllerContext.replicaState(replica)
logSuccessfulTransition(replicaId, partition, currentState, OfflineReplica)
controllerContext.putReplicaState(replica, OfflineReplica)
}
replicasWithoutLeadershipInfo.foreach { replica =>
val currentState = controllerContext.replicaState(replica)
logSuccessfulTransition(replicaId, replica.topicPartition, currentState, OfflineReplica)
controllerBrokerRequestBatch.addUpdateMetadataRequestForBrokers(controllerContext.liveOrShuttingDownBrokerIds.toSeq, Set(replica.topicPartition))
controllerContext.putReplicaState(replica, OfflineReplica)
}
将副本从ISR移除的逻辑如下,里面用了很多Either,就代码上来说拆解起来挺费时,直接看注释就行:
private def removeReplicasFromIsr(
replicaId: Int,
partitions: Seq[TopicPartition]
): Map[TopicPartition, LeaderIsrAndControllerEpoch] = {
var results = Map.empty[TopicPartition, LeaderIsrAndControllerEpoch]
var remaining = partitions
while (remaining.nonEmpty) {
// 将副本从isr移除
val (finishedRemoval, removalsToRetry) = doRemoveReplicasFromIsr(replicaId, remaining)
// 将需要重试的副本记录下来,下次循环重试
remaining = removalsToRetry
finishedRemoval.foreach {
case (partition, Left(e)) =>
// 移除失败,打印日志
val replica = PartitionAndReplica(partition, replicaId)
val currentState = controllerContext.replicaState(replica)
logFailedStateChange(replica, currentState, OfflineReplica, e)
case (partition, Right(leaderIsrAndEpoch)) =>
// 移除成功,记录新的LeaderIsrAndControllerEpoch
results += partition -> leaderIsrAndEpoch
}
}
results
}
private def doRemoveReplicasFromIsr(
replicaId: Int,
partitions: Seq[TopicPartition]
): (Map[TopicPartition, Either[Exception, LeaderIsrAndControllerEpoch]], Seq[TopicPartition]) = {
// 获取zk上的分区leader信息,返回的结果分为:
// 有leader的分区信息、没有leader的分区信息
val (leaderAndIsrs, partitionsWithNoLeaderAndIsrInZk) = getTopicPartitionStatesFromZk(partitions)
// 将有leader信息的分区分为两类:
// leaderAndIsrsWithReplica:包含需要移除的副本的分区
// leaderAndIsrsWithoutReplica:不包含需要移除的副本的分区
val (leaderAndIsrsWithReplica, leaderAndIsrsWithoutReplica) = leaderAndIsrs.partition { case (_, result) =>
result.right.map { leaderAndIsr =>
leaderAndIsr.isr.contains(replicaId)
}.right.getOrElse(false)
}
// 将该离线副本从需要移除副本的分区中移除
// 将副本从ISR移除,并且如果副本是leader,将分区标记为无leader状态,触发重新选举
val adjustedLeaderAndIsrs: Map[TopicPartition, LeaderAndIsr] = leaderAndIsrsWithReplica.flatMap {
case (partition, result) =>
result.right.toOption.map { leaderAndIsr =>
val newLeader = if (replicaId == leaderAndIsr.leader) LeaderAndIsr.NoLeader else leaderAndIsr.leader
val adjustedIsr = if (leaderAndIsr.isr.size == 1) leaderAndIsr.isr else leaderAndIsr.isr.filter(_ != replicaId)
partition -> leaderAndIsr.newLeaderAndIsr(newLeader, adjustedIsr)
}
}
// 将修改后的分区leader信息更新到zk上
val UpdateLeaderAndIsrResult(finishedPartitions, updatesToRetry) = zkClient.updateLeaderAndIsr(
adjustedLeaderAndIsrs,
controllerContext.epoch,
controllerContext.epochZkVersion
)
//
val exceptionsForPartitionsWithNoLeaderAndIsrInZk: Map[TopicPartition, Either[Exception, LeaderIsrAndControllerEpoch]] =
partitionsWithNoLeaderAndIsrInZk.iterator.flatMap { partition =>
if (!controllerContext.isTopicQueuedUpForDeletion(partition.topic)) {
val exception = new StateChangeFailedException(
s"Failed to change state of replica $replicaId for partition $partition since the leader and isr " +
"path in zookeeper is empty"
)
Option(partition -> Left(exception))
} else None
}.toMap
val leaderIsrAndControllerEpochs: Map[TopicPartition, Either[Exception, LeaderIsrAndControllerEpoch]] =
(leaderAndIsrsWithoutReplica ++ finishedPartitions).map { case (partition, result: Either[Exception, LeaderAndIsr]) =>
(
partition,
result.right.map { leaderAndIsr =>
val leaderIsrAndControllerEpoch = LeaderIsrAndControllerEpoch(leaderAndIsr, controllerContext.epoch)
controllerContext.partitionLeadershipInfo.put(partition, leaderIsrAndControllerEpoch)
leaderIsrAndControllerEpoch
}
)
}
(
leaderIsrAndControllerEpochs ++ exceptionsForPartitionsWithNoLeaderAndIsrInZk,
updatesToRetry
)
}
转入ReplicaDeletionStarted
case ReplicaDeletionStarted =>
validReplicas.foreach { replica =>
val currentState = controllerContext.replicaState(replica)
logSuccessfulTransition(replicaId, replica.topicPartition, currentState, ReplicaDeletionStarted)
controllerContext.putReplicaState(replica, ReplicaDeletionStarted)
controllerBrokerRequestBatch.addStopReplicaRequestForBrokers(Seq(replicaId), replica.topicPartition, deletePartition = true)
}
转入ReplicaDeletionIneligible
case ReplicaDeletionIneligible =>
validReplicas.foreach { replica =>
val currentState = controllerContext.replicaState(replica)
logSuccessfulTransition(replicaId, replica.topicPartition, currentState, ReplicaDeletionIneligible)
controllerContext.putReplicaState(replica, ReplicaDeletionIneligible)
}
转入ReplicaDeletionSuccessful
case ReplicaDeletionSuccessful =>
validReplicas.foreach { replica =>
val currentState = controllerContext.replicaState(replica)
logSuccessfulTransition(replicaId, replica.topicPartition, currentState, ReplicaDeletionSuccessful)
controllerContext.putReplicaState(replica, ReplicaDeletionSuccessful)
}
转入NonExistentReplica
case NonExistentReplica =>
validReplicas.foreach { replica =>
val currentState = controllerContext.replicaState(replica)
val newAssignedReplicas = controllerContext
.partitionFullReplicaAssignment(replica.topicPartition)
.removeReplica(replica.replica)
controllerContext.updatePartitionFullReplicaAssignment(replica.topicPartition, newAssignedReplicas)
logSuccessfulTransition(replicaId, replica.topicPartition, currentState, NonExistentReplica)
controllerContext.removeReplicaState(replica)
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号