pytorch中DataSet和DataLoader的使用详解(Subset,ConcatDataset)
1. 首先导入需要用到的包
from torch.utils.data import DataLoader,Dataset
2. 自定义Dataset
一般情况下我们使用Dataset,需要自定义一个类来继承Dataset,然后实现__getitem__()方法和__len__()方法
使用示例如下所示:
import torch
a = [[1,2,3,4],[4,5,6,7,9],[6,7,8,9,4,5],[4,3,2],[8,7,5,4],[4,8,7,1]]
b = [1,2,3,4,5,6]
class mydataset(Dataset):
def __init__(self,x,y):
self.feature = x
self.label = y
def __getitem__(self,item):
return torch.tensor(self.feature[item]),self.label[item] #根据需要进行设置
def __len__(self):
return len(self.feature)
dataset = mydataset(a,b)
print(dataset[0])
程序运行结果如下所示:
(tensor([1, 2, 3, 4]), 1)
3. 创建DataLoader
DataLoader需要传入几个参数,先看一下官方的定义:

常用到的几个参数解释如下:
# dataset:数据集,传入我们刚才创建的数据集即可;
# batch_size:每个batch的大小
# collate_fn:按照定义函数的方式进行取数据
# shuffle:是否将数据集中的数据进行打乱
使用示例如下所示:
def fun(x): # 根据自己的需求定义dataloader返回数据的格式
x.sort(key=lambda data:len(data[0]),reverse=True)
# print(x)
feature = []
label = []
length = []
for i in x:
feature.append(i[0])
label.append(i[1])
length.append(len(i[0]))
# feature = pad_sequence(feature,batch_first=True,padding_value=-1) # 可以适当的进行补齐操作
return feature,label,length
dataloader = DataLoader(dataset,batch_size=2,collate_fn=fun) # 定义DataLoader
for x,y,length in dataloader:
print(x,y,length)
print('------------------')
程序运行结果如下所示:
[tensor([4, 5, 6, 7, 9]), tensor([1, 2, 3, 4])] [2, 1] [5, 4]
------------------
[tensor([6, 7, 8, 9, 4, 5]), tensor([4, 3, 2])] [3, 4] [6, 3]
------------------
[tensor([8, 7, 5, 4]), tensor([4, 8, 7, 1])] [5, 6] [4, 4]
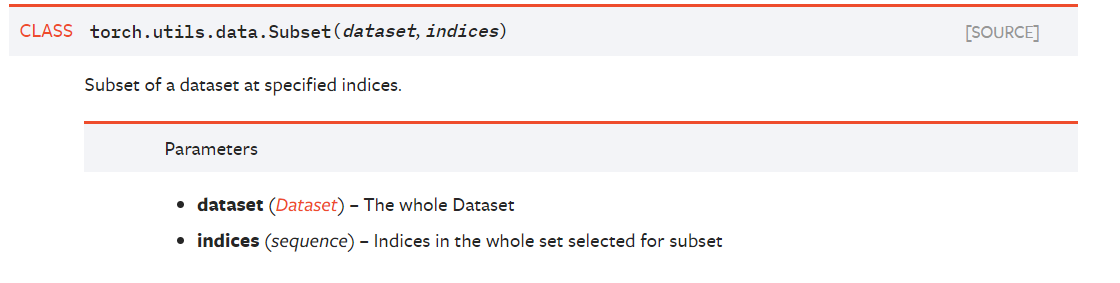
- Subset的使用
首先看一下官网的定义:
![]()
该类的用处是从一个大的数据集中取出一部分作为数据子集,其中indices是索引值,可以是列表形式。
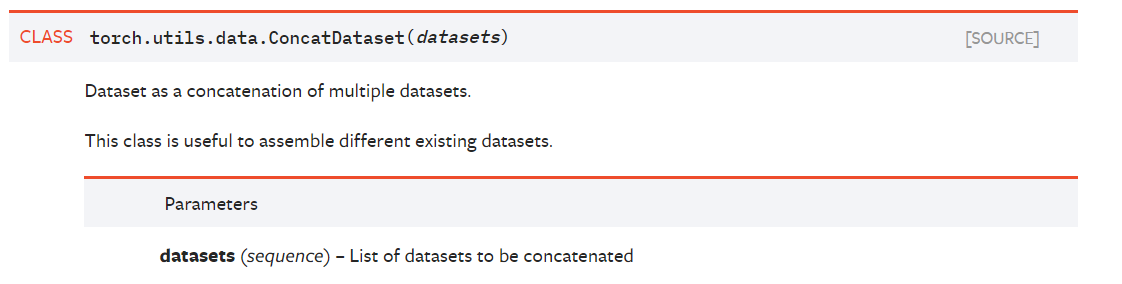
5.ConcatDataset的使用
官网的定义如下:
![]()
该类的用处是将多个数据子集合并为一个整的数据集,其中参数datasets是需要合并的数据子集集合,以列表的形式给出。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号