
爬虫笔记20211019
个人学习,笔记记录
引用模块
- os(读写储存爬取内容)
- requests(通过链接与请求头获得html页面内容)
- re(正则表达式筛选文字内容)
爬取对象与目标
- 纵横小说网的小说,爬取谋篇小说
步骤
分析网页
链接内容为点进去的小说的第一章节内容,而F12代码查看里面小说内容在content这个类里面,主要内容在p中,题目在title_txtbox中。
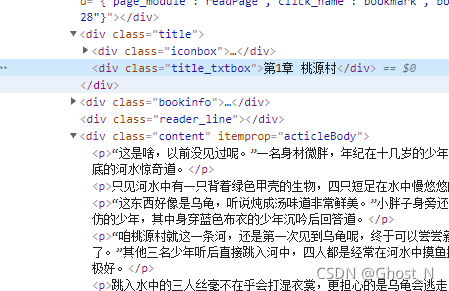
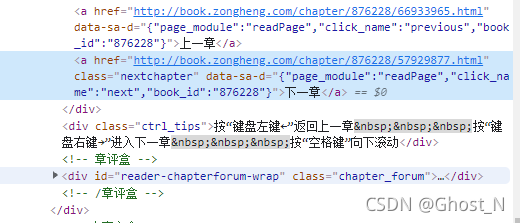
切换下一章节,在nextchapter这个类中
分部方法
链接为小说第一章内容,我们查阅下一章为点击下一章按钮进行跳转,据此我们需要准备的方法分解为:
- 加载单章内容
并非真实下载,只是加到缓存中
# 准备访问请求头,对应F12查看自己的请求头信息,User-Agent就够了,如有其他需要增加即可
headers={
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.106 Safari/537.36',
}
#下载单页的方法
def download_single_page(url):
# 用requests.get()方法以字符串的形式储存到url_page变量中
url_page=requests.get(url,headers=headers)
# 随意两个字段,利用 re.findall()方法拆出标题和内容,“(.*?)”这个内容为里面为保留的内容,前后为那两个字符之间
a =re.findall('<div class="title_txtbox">(.*?)</div>',url_page.text)
b =re.findall('<p>(.*?)</p>',url_page.text)
# 准备书写到电脑文本里的内容
txt=''
for i in b:
txt=txt+i+'\n'
txtf=url+'\n'+a[0] + '\n'+txt
return txtf,a
- 加载各章节链接
为批量下载方法做准备,传入第一页链接与数量参数,利用正则表达式与简单循环获得各个章节链接地址,返回到一个链接地址列表中
def url_page(url_frist,n):
i = 1
url_list = [url_frist]
while i < n:
url_page = requests.get(url_frist, headers=headers)
url1=re.findall('<a href="(.*?)" class="nextchapter"',url_page.text)
print(url1[0]+r'已加入下载队列......')
url_list.append(url1[0])
url_frist=url1[0]
i += 1
print(r'''"\@_"\@_"\@_所有队列已准备完成"\@_"\@_"\@_''')
return url_list
- 写入文件的方法
利用os模块,在指定目录下,将标题跟文件写入,这个测试储存的格式为txt
def write_file(filename,txtf,title):
if not os.path.exists(filename):
os.mkdir(filename)
with open (filename+title[0]+'.txt','w',encoding='utf-8') as f:
f.write(txtf)
print(title[0]+r'''缓存已下载完成......''')
- 批量爬取小说主方法
利用以上方法,通过传入准备好的文件夹地址,第一页链接与想要往后爬取的数量,进行小说批量下载
def group_page(filename,url,n):
url_list= url_page(url,n)
for i in url_list:
txtf,a=download_single_page(i)
write_file(filename,txtf,a)
运行抓取
我准备的文件夹是这个小说的名字,也可以随意写一个名字在上面补充识别路径没有创建的方法,中间是第一页的小说链接,下载测试下载了10章。这个是比较简易的,自己查资料的一个尝试,作为日记一样记录下来,一个学习笔记吧最近打算养成的一个习惯,后面不断的记录学习变强吧。后面的一些登录认证什么的还爬取不了,get到在记录吧
group_page('轮回神仙道\\','http://book.zongheng.com/chapter/876228/57924115.html',10)
 posted on
posted on

 浙公网安备 33010602011771号
浙公网安备 33010602011771号