CNN模型:ResNet
https://zhuanlan.zhihu.com/p/31852747
ResNet: 深度残差网络。
解决了深度CNN模型训练难的问题。
- 14年VGG 19层;15年ResNet 152层;
- 靠深度取胜;利用残差学习使网络的深度发挥出作用。
1. 深度网络的退化问题 [Degradation Problem]
网络深度增加时,网络准确度出现饱和,甚至出现下降。
56层比20层效果还差,不会是过拟合的问题,因为56层网络的训练误差同样高。
深层网络存在着梯度消失或梯度爆炸的问题,因此使得深度学习模型很难训练。
- 利用如BatchNorm来缓解此问题。
- 出现深度网络的退化问题令人诧异。
2. 残差学习
Degradation Problem说明深度网络不宜训练;
考虑这样一个事实:
- 现有一个浅层网络;
- 你想通过向上堆积新层来建立深层网络;
- 一个极端情况是:
- 这些新增加的层什么也不学习,
- 仅仅复制浅层网络的特征,
- 这样的新层是恒等映射(identity mapping)。
- 至少可以期待,深层网络和浅层网络性能一样,也不应该出现退化现象。
- 不得不承认,肯定是训练方法有问题,才使得深层网络很难找到好的参数。
提出残差学习来解决退化问题。
- 对于一个堆积层结构,输入x,学习到特征H(x);
- 现在,希望它可以学习到残差F(x)=H(x)-x;
- 原始的学习特征是F(x)+x。
- 因为,残差学习相比原始特征直接学习更容易。【为什么?】
- 当残差为0,只是做了恒等映射,至少网络性能不会下降;
- 实际上残差不会为0
- 使得堆积层在输入特征的基础上学习到新的特征
- 从而拥有更好的性能。
- 短路连接(shortcut connection)。
为什么残差学习相对更容易?
- 直观上,残差学习需要学习的内容少,因为残差一般会比较小,学习难度小点。
- 从数学的角度来分析这个问题:
- 残差单元: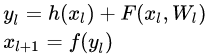
- 每个残差单元一般包含多层结构。
- F:残差函数;h():恒等映射;f():ReLU激活函数。
- 从浅层l到深层L的学习特征为:
- 利用链式规则,求得反向过程的梯度: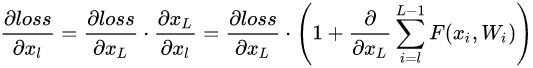
- 式子的第一个因子 表示的损失函数到达
的梯度,
- 小括号中的1表明短路机制可以无损地传播梯度,
- 另外一项残差梯度则需要经过带有weights的层,梯度不是直接传递过来的。
- 残差梯度不会那么巧全为-1,而且就算其比较小,有1的存在也不会导致梯度消失。
- 所以残差学习会更容易。要注意上面的推导并不是严格的证明。
3. ResNet网络结构
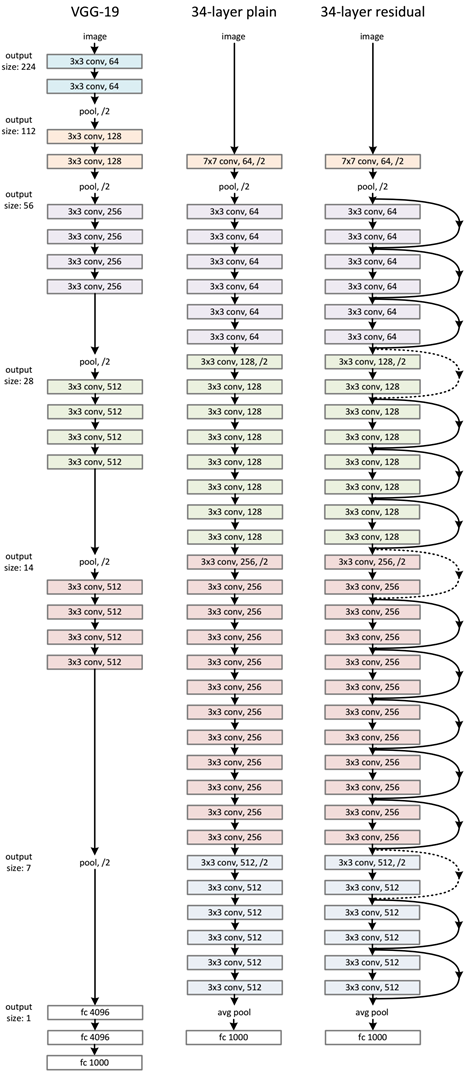
- ResNet网络是参考了VGG19网络,在其基础上进行了修改,并通过短路机制加入了残差单元,如图5所示。
- 变化主要体现在
- ResNet直接使用stride=2的卷积做下采样,
- 用global average pool层替换了全连接层。
ResNet的一个重要设计原则是:
- 当feature map大小降低一半时,feature map的数量增加一倍,
- 这保持了网络层的复杂度。
从图5中可以看到,
- ResNet相比普通网络每两层间增加了短路机制,这就形成了残差学习,
- 其中虚线表示feature map数量发生了改变。
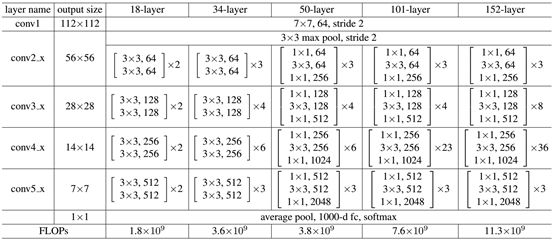
- 图5展示的34-layer的ResNet,还可以构建更深的网络如表1所示。
- 从表中可以看到,
- 对于18-layer和34-layer的ResNet,其进行的两层间的残差学习,
- 当网络更深时,其进行的是三层间的残差学习,三层卷积核分别是1x1,3x3和1x1,
- 一个值得注意的是隐含层的feature map数量是比较小的,并且是输出feature map数量的1/4。
- 分析残差单元
- 两种残差单元:
- 左图:浅层网络。右图:深层网络。
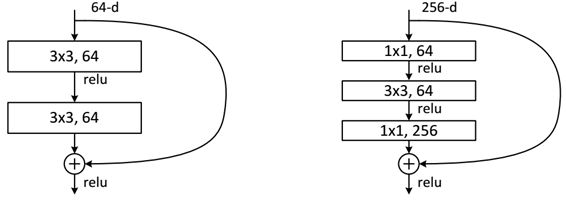
- 对于短路连接,
- 当输入和输出维度一致时,可以直接将输入加到输出上。
- 但是当维度不一致时(对应的是维度增加一倍),这就不能直接相加。
- 有两种策略:
(1)采用zero-padding增加维度,此时一般要先做一个downsamp,可以采用strde=2的pooling,这样不会增加参数;
(2)采用新的映射(projection shortcut),一般采用1x1的卷积,这样会增加参数,也会增加计算量。
短路连接除了直接使用恒等映射,当然都可以采用projection shortcut。
- 最优的残差结构
- 如图8所示。
- 改进前后一个明显的变化是采用pre-activation,BN和ReLU都提前了。
- 而且作者推荐短路连接采用恒等变换,这样保证短路连接不会有阻碍。感兴趣的可以去读读这篇文章:https://arxiv.org/abs/1603.05027

 浙公网安备 33010602011771号
浙公网安备 33010602011771号