python调用mediainfo工具批量提取视频信息
写了2个脚本,分别是v1版本和v2版本
都是python调用mediainfo工具提取视频元数据信息
v1版本是使用pycharm中测试运行的,指定了视频路径
v2版本是最终交付给运营运行的,会把v2版本打成exe运行
先看v1版本
import os,subprocess,json,re,locale,sys
import xlwt,time,shutil
#获取当前文件所在绝对目录路径
# this_path=os.path.abspath('.')
# print('当前路径为----',this_path)
# dir_path=this_path
#视频文件所在目录
dir_path='I:\\3分钟便当'
# print(os.listdir(this_path))
print('---------------------------------')
print('--------------程序马上开始----------------')
# dir_path=this_path
#定义个列表存放每个文件绝对路径,便于后期操作
init_list=[]
# dir_path='F:\\玩具屋总视频'
#创建个方法,统计每个文件路径,并追加列表中。这里注释掉了递归,不获取子目录了,只获取dir_path下面的视频
def get_all_file(dir_path,init_list):
for file in os.listdir(dir_path):
# print(file)
filepath=os.path.join(dir_path,file)
# print(filepath)
if os.path.isdir(filepath):
print('遇到子目录---%s---此版本暂不提取子目录视频信息--'%(filepath))
time.sleep(2)
# get_all_file(filepath)
else:
if not file.endswith('exe'):
init_list.append(filepath)
return init_list
#执行上面方法,把每个文件绝对路径追加到列表中
file_list=get_all_file(dir_path,init_list)
print("文件读取完毕-----3秒后开始获取视频详细信息------------")
time.sleep(3)
#定义个方法,获取单个media文件的元数据,返回为字典数据
#此程序核心是调用了mediainfo工具来提取视频信息的
def get_media_info(file):
pname='D:\mediainfo_i386\MediaInfo.exe "%s" --Output=JSON'%(file)
result=subprocess.Popen(pname,shell=False,stdout=subprocess.PIPE).stdout
list_std=result.readlines()
str_tmp=''
for item in list_std:
str_tmp+=bytes.decode(item.strip())
json_data=json.loads(str_tmp)
return json_data
#定义个方法传递字典数据,返回自己想要的字段数据,返回值列表
def get_dict_data(json_data):
#获取文件大小
filesize=json_data['media']['track'][0]['FileSize']
#获取码率
malv=json_data['media']['track'][0]['OverallBitRate'][0:4]
#获取播放时长
duration=json_data['media']['track'][0]['Duration'].split('.')[0]
#获取文件类型
file_format=json_data['media']['track'][0]['Format']
#获取帧宽
samp_width=json_data['media']['track'][1]['Sampled_Width']
#获取帧高
samp_height=json_data['media']['track'][1]['Sampled_Height']
return [filesize,malv,duration,file_format,samp_width,samp_height]
#定义个方法,获取文件名,它是key,它的value就是目标列表,返回值是个字典,参数是文件列表
dict_all={}
#定义个日志存提取失败视频文件名
f_fail=open('提取失败日志.log','a',encoding='utf-8') # 追加模式
def get_all_dict(file_list,f_fail):
for file in file_list:
filename=os.path.split(file)[1]
print(filename)
time.sleep(0.1)
try:
info_list=get_dict_data(get_media_info(file))
dict_all[filename]=info_list
except Exception as e:
print(filename,'------提取此文件信息失败---------')
f_fail.write(filename+'\r\n')
f_fail.close()
get_all_dict(file_list,f_fail)
# for item in dict_all:
# print(item,dict_all[item])
#创建一个excel表存放文件路径信息,第一列是目录,第二列是文件名
wb = xlwt.Workbook()
sh = wb.add_sheet('元数据')
#写第一行
row_count=0
sh.write(row_count,0,"文件名")
sh.write(row_count,1,"文件大小")
sh.write(row_count,2,"码率")
sh.write(row_count,3,"总时长")
sh.write(row_count,4,"视频格式")
sh.write(row_count,5,"帧宽")
sh.write(row_count,6,"帧高")
#批量写入视频信息
row_count=1
for item in dict_all:
sh.write(row_count,0,item)
sh.write(row_count,1,dict_all[item][0])
sh.write(row_count,2,dict_all[item][1])
sh.write(row_count,3,dict_all[item][2])
sh.write(row_count,4,dict_all[item][3])
sh.write(row_count,5,dict_all[item][4])
sh.write(row_count,6,dict_all[item][5])
row_count+=1
#
wb.save("元数据统计.xls")
#
在看v2版本
v2版本是对当前目录下的视频进行提取
import os,subprocess,json,re,locale,sys
import xlwt,time,shutil
#获取当前文件所在绝对目录路径
this_path=os.path.abspath('.')
print('当前路径为----',this_path)
dir_path=this_path
# print(os.listdir(this_path))
print('---------------------------------')
print('--------------程序马上开始----------------')
# dir_path=this_path
#定义个列表存放每个文件路径,便于后期操作
init_list=[]
# dir_path='I:\\3分钟便当'
# dir_path='F:\\玩具屋总视频'
#创建个方法,统计每个文件路径,并追加列表中。用到了递归,这里不获取子目录了
def get_all_file(dir_path,init_list):
for file in os.listdir(dir_path):
# print(file)
filepath=os.path.join(dir_path,file)
# print(filepath)
if os.path.isdir(filepath):
print('遇到子目录---%s---此版本暂不提取子目录视频信息--'%(filepath))
time.sleep(2)
# get_all_file(filepath)
else:
if not file.endswith('exe'):
init_list.append(filepath)
return init_list
#执行上面方法,把每个文件绝对路径追加到列表中
file_list=get_all_file(dir_path,init_list)
print("文件读取完毕-----3秒后开始获取视频详细信息------------")
time.sleep(3)
#定义个方法,获取单个media文件的元数据,返回为字典数据
def get_media_info(file):
pname='D:\mediainfo_i386\MediaInfo.exe "%s" --Output=JSON'%(file)
result=subprocess.Popen(pname,shell=False,stdout=subprocess.PIPE).stdout
list_std=result.readlines()
str_tmp=''
for item in list_std:
str_tmp+=bytes.decode(item.strip())
json_data=json.loads(str_tmp)
return json_data
#定义个方法传递字典数据,返回自己想要的字段数据,返回值列表
def get_dict_data(json_data):
#获取文件大小
filesize=json_data['media']['track'][0]['FileSize']
#获取码率
malv=json_data['media']['track'][0]['OverallBitRate'][0:4]
#获取播放时长
duration=json_data['media']['track'][0]['Duration'].split('.')[0]
#获取文件类型
file_format=json_data['media']['track'][0]['Format']
#获取帧宽
samp_width=json_data['media']['track'][1]['Sampled_Width']
#获取帧高
samp_height=json_data['media']['track'][1]['Sampled_Height']
return [filesize,malv,duration,file_format,samp_width,samp_height]
#定义个方法,获取文件名,它是key,它的value就是目标列表,返回值是个字典,参数是文件列表
dict_all={}
f_fail=open('提取失败日志.log','a',encoding='utf-8') # 追加模式
def get_all_dict(file_list,f_fail):
for file in file_list:
filename=os.path.split(file)[1]
print(filename)
time.sleep(0.1)
try:
info_list=get_dict_data(get_media_info(file))
dict_all[filename]=info_list
except Exception as e:
print(filename,'------提取此文件信息失败---------')
f_fail.write(filename+'\r\n')
f_fail.close()
get_all_dict(file_list,f_fail)
# for item in dict_all:
# print(item,dict_all[item])
#创建一个excel表存放文件路径信息,第一列是目录,第二列是文件名
wb = xlwt.Workbook()
sh = wb.add_sheet('元数据')
#写第一行
row_count=0
sh.write(row_count,0,"文件名")
sh.write(row_count,1,"文件大小")
sh.write(row_count,2,"码率")
sh.write(row_count,3,"总时长")
sh.write(row_count,4,"视频格式")
sh.write(row_count,5,"帧宽")
sh.write(row_count,6,"帧高")
row_count=1
for item in dict_all:
sh.write(row_count,0,item)
sh.write(row_count,1,dict_all[item][0])
sh.write(row_count,2,dict_all[item][1])
sh.write(row_count,3,dict_all[item][2])
sh.write(row_count,4,dict_all[item][3])
sh.write(row_count,5,dict_all[item][4])
sh.write(row_count,6,dict_all[item][5])
row_count+=1
#
wb.save("元数据统计.xls")
把v2版本打成exe文件
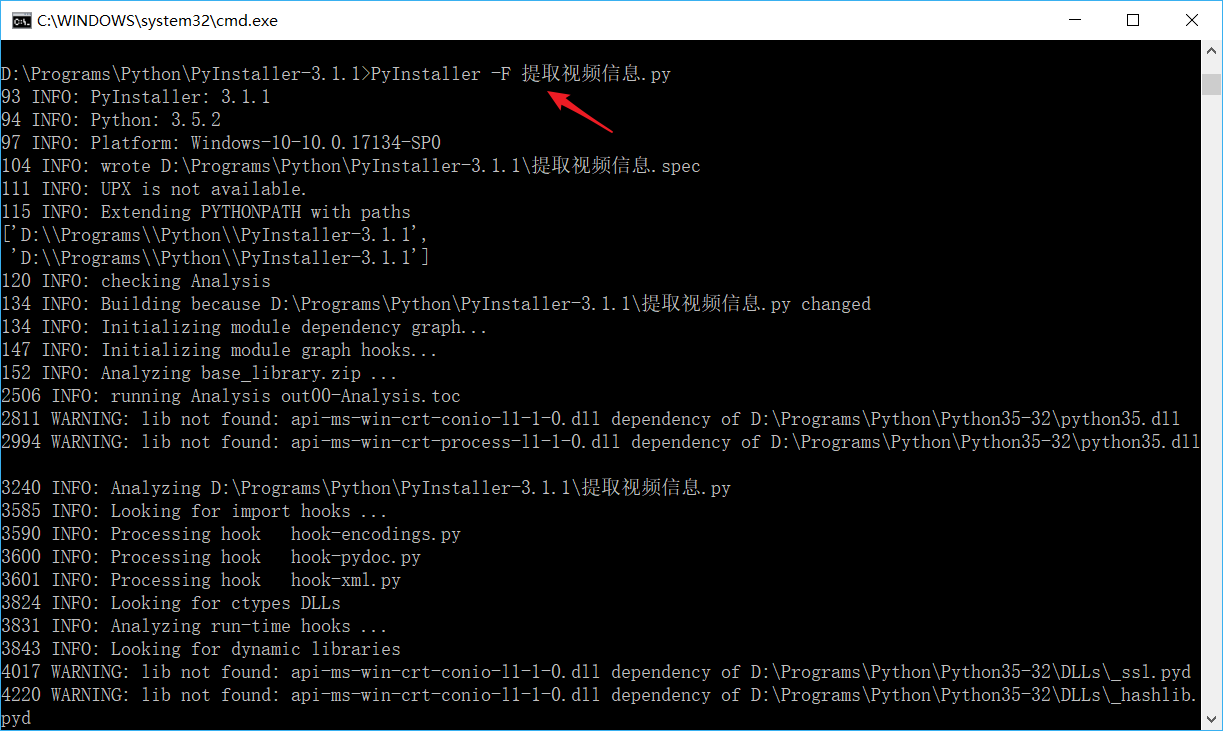
如下路径下拷贝此exe文件

这个程序交付给运营同事即可
测试和验证部分
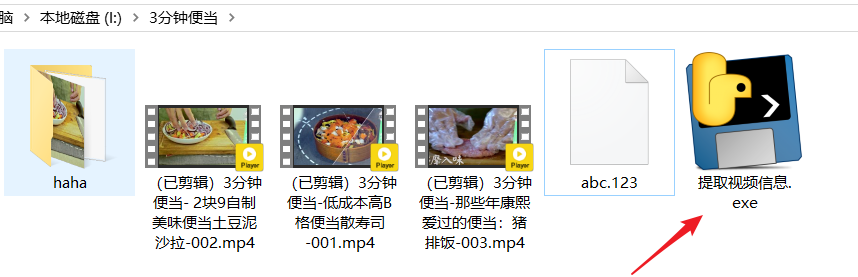
使用方式,把程序放在视频同级目录下
按照代码缩写,如果视频运行成功:
1、此程序不会对haha目录进行处理
2、对于无法识别的文件比如abc.123(可能不是视频文件,或者已经损坏的视频文件),此程序会记录日志,同时程序正常运行不会中断
3、程序运行之后会有一个失败日志.log文件,记录了提取信息失败的视频名,同时把提取成功的视频文件放在“元数据统计.xls”中
测试验证下
双击运行
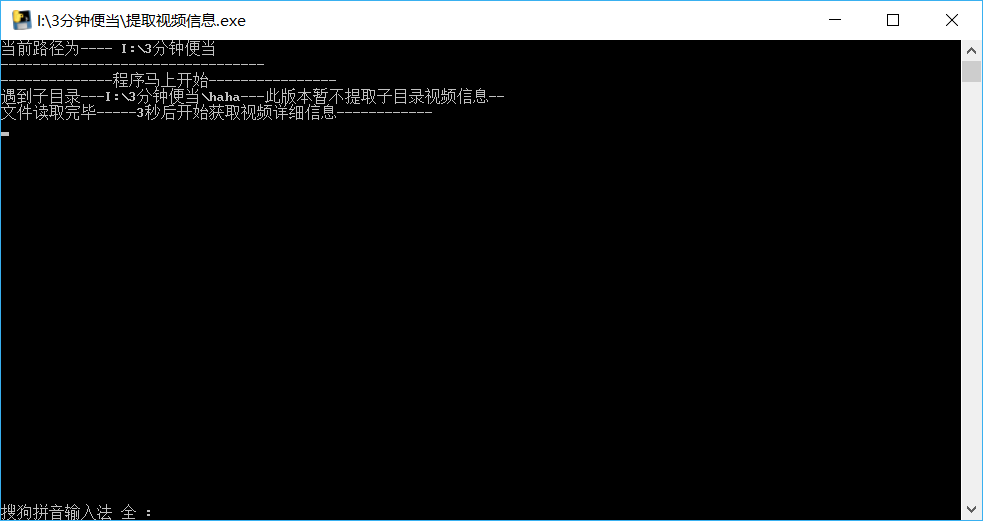
运行结束
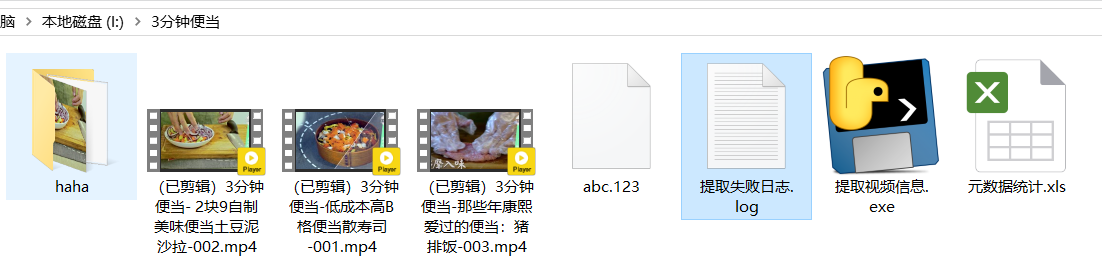

excel表信息
文件大小是字节,如果想显示为MB或者GB,使用excel表内置的公式即可处理
有很多字段,码率,时长等。这里因为运营只需要如下字段,就提取了这些

如果把此exe程序交付给运营同事使用,需要把D盘那个mediainfo_i386文件夹一起交给他们,此文件加必须放在D盘

 浙公网安备 33010602011771号
浙公网安备 33010602011771号