Explanation Guided Contrastive Learning for Sequential Recommendation
背景:
现有的基于对比学习的方法不能保证通过对给定的锚用户序列进行随机增强(或序列采样)得到的正(或负)序列在语义上保持相似(或不同)。当阳性和阴性序列分别为假阳性和假阴性时,可能会导致推荐性能下降。
虽然现有的对比学习方法已被证明可以提高顺序推荐的性能,但由于现有的对比学习方法的用户增强序列和采样方法是随机执行的。
对于给定的用户序列,容易产生看起来非常不同的positive view和看起来非常相似的negative view。导致学习到的序列表示不理想,降低了推荐精度。

上面的例子中,我们看序列(a),它表示用户的原始序列以及推荐的下一项。可以看到其下一项是Hair Care相关,那么在原始序列中,Hair Care标签的物品表现为正相关。
接下来三个序列分别表示由随机遮盖增强得到的两个正样本和一个从其他用户抽样得来的负样本。
显然,对于Positive view 1,序列中有三个Hair Care相关的项,让它作为正样本是没毛病的。但是对于Positive view 2,只有一个Hair Care相关的项,我们用对比损失来靠近view1和view2就是不合理的。
同理,对于负样本,其中却有两个是Hair Care相关,让负样本和view2远离也是不合理的。这个例子的问题说明了随机增强和采样的方法有时会降低推荐精度。
本文通过提出解释引导增强(EGA)和解释引导对比学习序列推荐(EC4SRec)模型框架来解决上述问题。EGA的关键思想是利用解释方法来确定商品在用户序列中的重要性,并相应地推导出正负序列。然后,EC4SRec 在 EGA 操作生成的正负序列上结合自监督和监督对比学习,以改进序列表征学习以获得更准确的推荐结果。
实现:
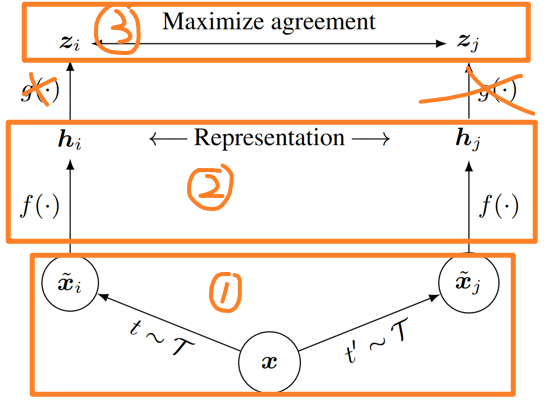
对于一个对比学习,我们可以将其分为三个部分:1.数据增强,2.通过编码器获得表征,3.对比学习。正如上图三个部分所示,其中g(·)表示的非线性映射层在之前的推荐系统研究中去除掉了。
那么知道了这些,我们可以直接来看本论文的框架(原图见源论文):
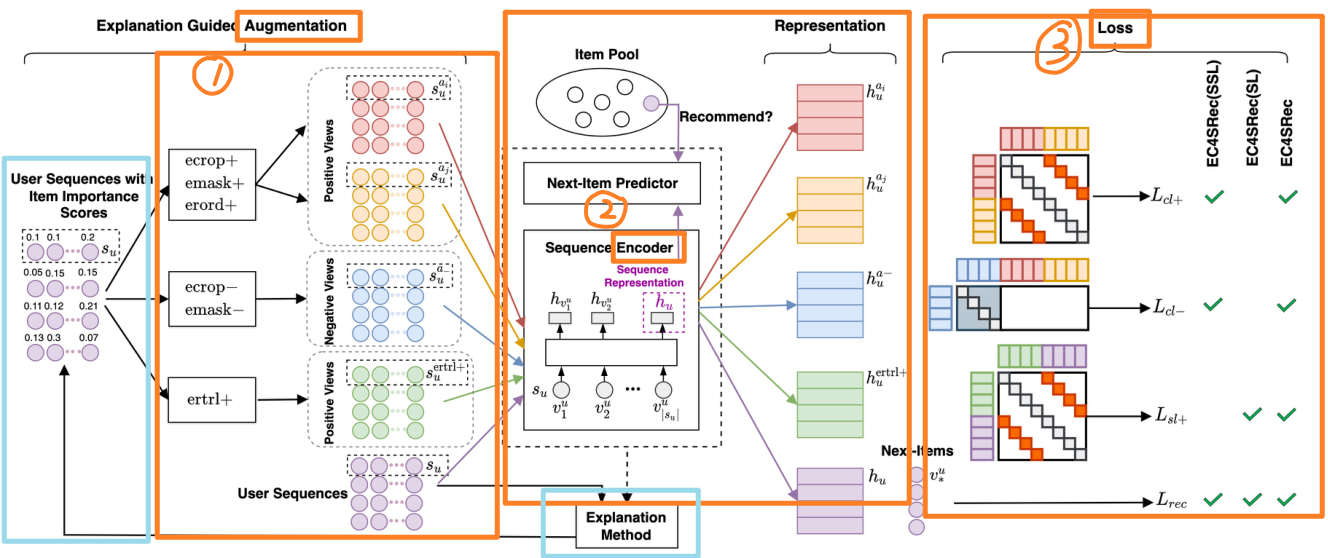
不难看出,每个红色方框其实都是对应的。蓝色方框则是多出来的那部分:解释学习方法。解释学习方法计算出序列中每一项的重要性得分,再通过这些得分来做数据增强。
很明确,这篇论文其实就是一个对比学习+一个计算项目重要性的方法。
解释学习方法:
解释学习方法是项目不可知的,本论文用了三个不同的解释学习方法分别实验效果。解释学习方法表示为:

数据增强:
前面几种数据增强方法都很简单,就最后一个ertrl+有点绕,我说一下个人理解。
首先我们得知道DuoRec中是如何构建正样本对的:对于原始序列S,我们从数据集中找到和S的下一项预测相同的序列,即为正样本。也就是说正样本对的下一项预测的物品是一样的。
ok,然后我们构建一个序列的集合,注意这个集合的元素都是和S与一样的序列,这个集合的元素都是和S是正样本对。我们通过重要性得分计算序列集合和S的相似度分布,然后通过该概率分布选取序列作为正样本。
概率分布:

其实总结说来就是:从下一项相同的序列集合中选出语义最和S相似的序列来构建正样本对。
损失函数:

具体项见源论文,都说的很清楚。
总结:
EC4SRec模型是第一次将顺序推荐与解释方法相结合。
本模型的重点在于使用了解释方法计算物品在用户序列中的重要性得分,并借此完成对比学习的数据增强,使得模型性能对于CL4Srec与DuoRec得到了较大的提升。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号