大模型高效、加速的运算 清华大模型课程
59 BMTrain工具包

先了解显存都去了哪里
1.模型的所有参数 2.模型的梯度 参数两和模型参数量是一个数量级的
3.中间的计算结果。4.优化器

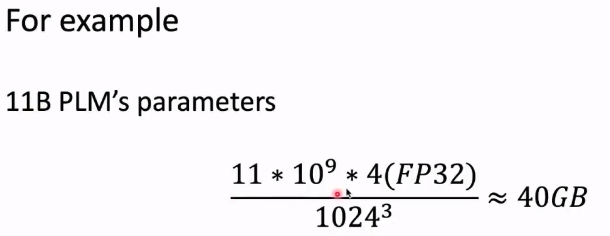
60 接下来看一下多个GPU之间的合作模式
数据并行
具体来说是参数被复制到每张显卡上,数据切成三份,各自前向传播 反向传播,然后梯度聚合。
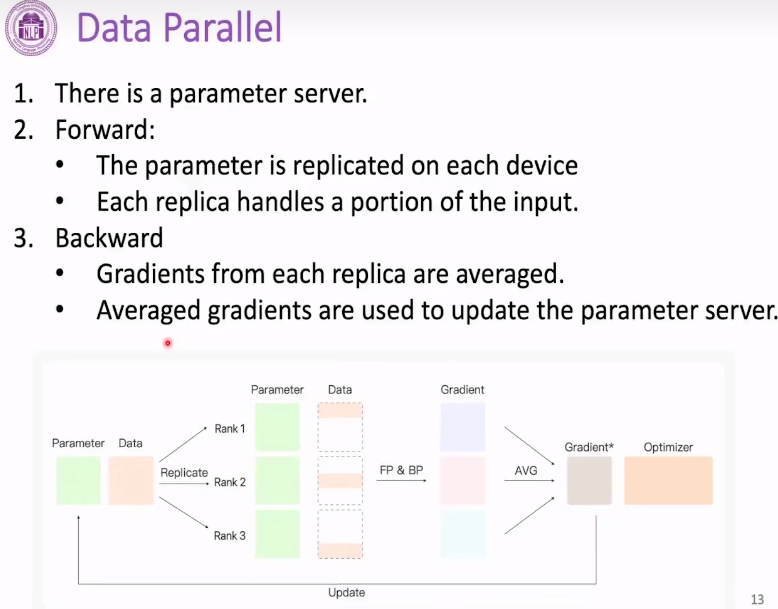
实际上参数显卡在0号,复制到1,2,3号显卡上, 1,2,3上的梯度显卡上的梯度聚合放到0号显卡上。
多张显卡的合作模式
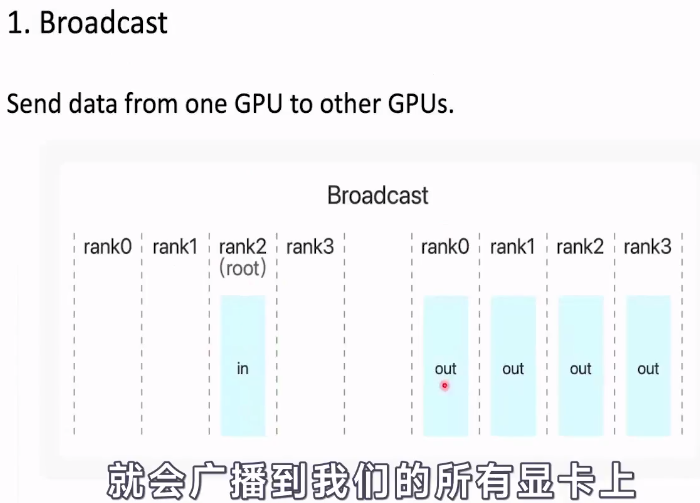
1.广播算子,Broadcast
2.Reduce规约 可以是求和 求平均

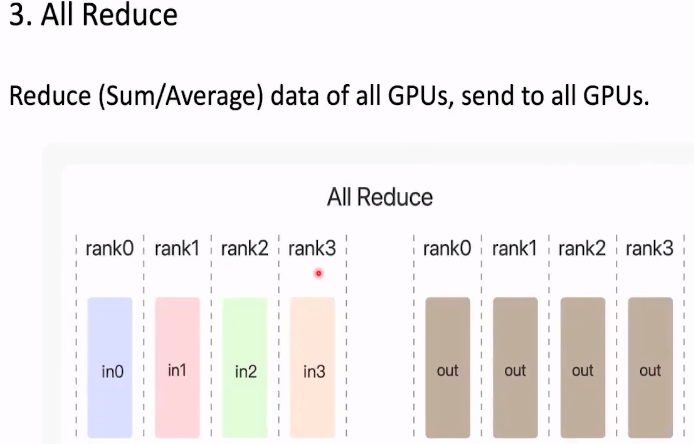
3.All Reduce
把规约得到的结果给所有的显卡
4 Reduce Scatter
每个GPU得到部分结果

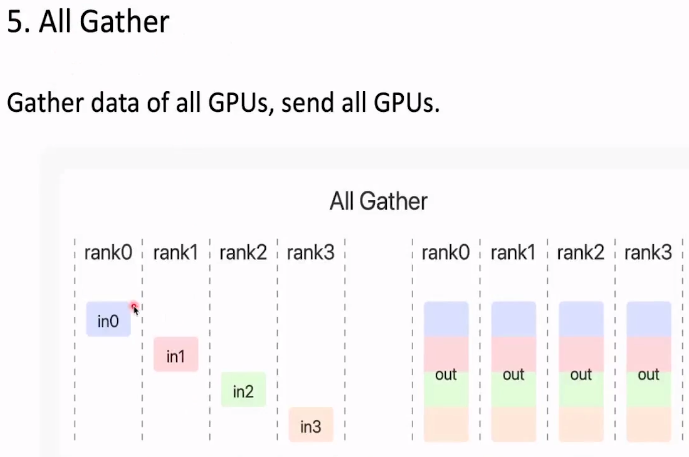
5.All Gather
把每张显卡的结果拼接 然后广播到所有显卡上
分布式数据并行
舍弃了参数服务器
同样是有一样的参数 得到部分数据 前向传播反向传播。使用all gather

分析data parallel带来的显存优化
数据并行的时候,每张显卡处理的batch大小变成了1/n。 中间结果量也有降低。 每张显卡至少分一个数据吧。
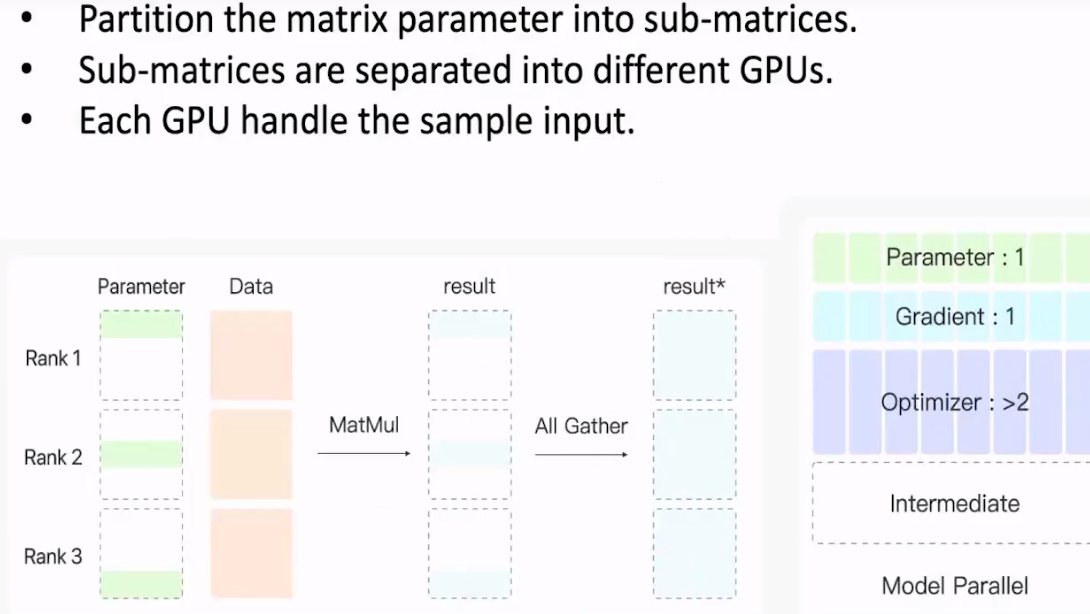
P61 模型的并行
把一个模型分成几个部分
62 Zero Redundancy Optimizer
基于数据并行建立的框架。每张显卡更新一部分梯度。

63 Pipeline Parallel 流水线并行
不同的层在不同的GPU上
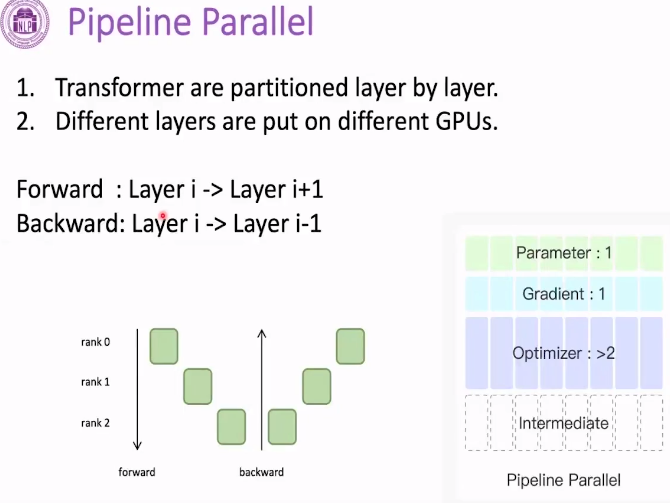
弊端在于计算资源的浪费 比如说1号卡在计算 0.2是不计算的
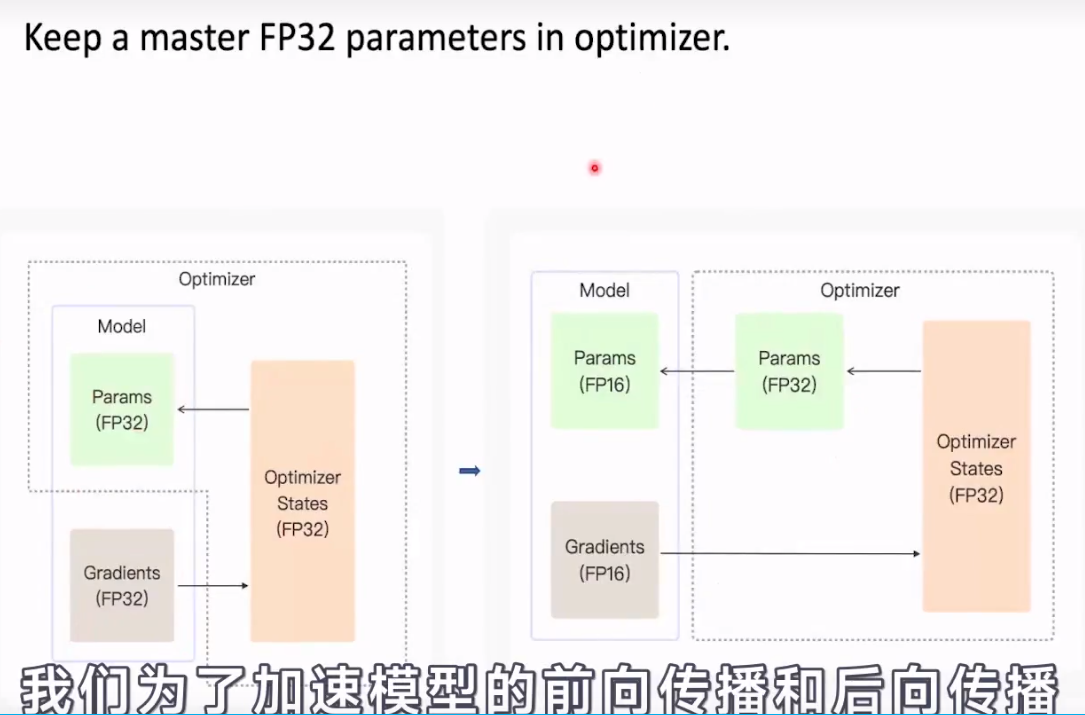
64 混合精度训练
fp16半进度 fp32单精度 默认是fp32

fp16的缺点:参数更新量约等于 gradient*lr
甚至更小 低于了fp16的参数表示范围。参数更新量就会产生丢失。在fp16下就会变成0。
65 offloading 不太懂
66 ovaerlapping
67 checkpointing


 浙公网安备 33010602011771号
浙公网安备 33010602011771号