刘知远团队 大模型公开课
课程来源:https://www.bilibili.com/video/BV1UG411p7zv?p=2&vd_source=7a1bf40d519bd5238c79a30456432f0d
22 注意力机制-原理介绍
attention的本质是对value向量的加权平均。
25 Transformer结构概述
27 Transformer结构-Encoder Block
29 优化tricks
1.checkpoint averaging 2.ADAM optimizer 3.Dropout 4.label smoothing 5 auto-agressive decoding with beam search and length penalities
31 优缺点
缺点 对参数敏感 优化困难。n方的计算复杂度。
36 transformers教程
42 Prompt learning 和 Delta-Tuning
44 PTM选取

上边这种的话不适合长文本(自己实验就是长文本 所以不适合 只能放在头部)
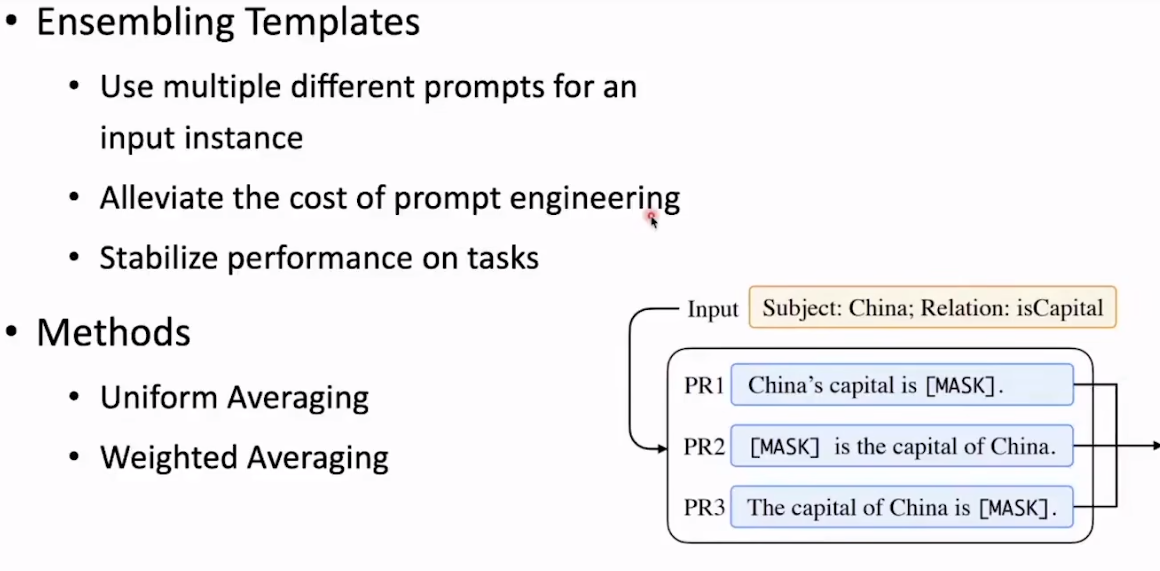
45 Template构造

可以采用多个prmopt的方式 进行融合
或者自动prompt
automatic search。
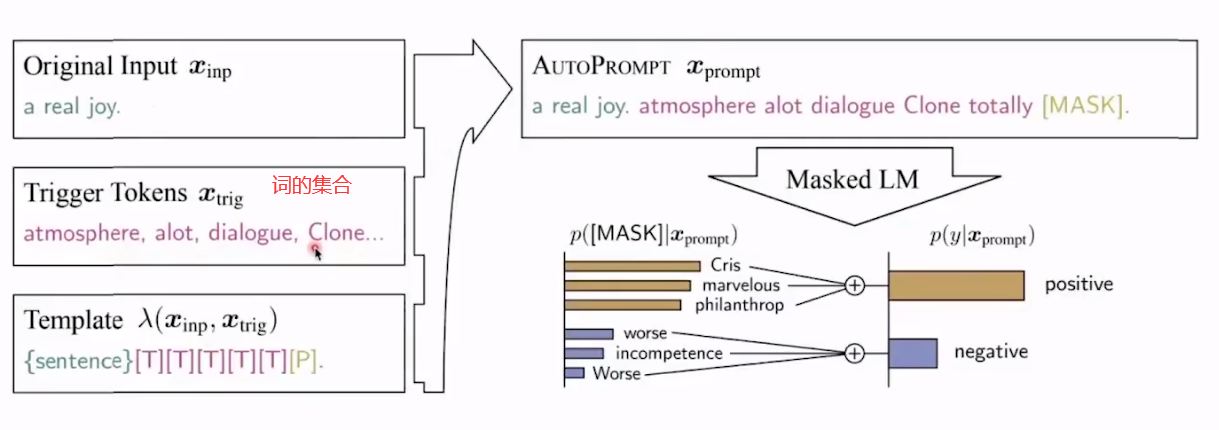
给我们的启示是不一定需要去用人的直觉去定义模板。可能就有一种最优。
46 Verbalizer构造

清华开发组件 OpenPrompt


 浙公网安备 33010602011771号
浙公网安备 33010602011771号