关于Adaboost学习笔记
内容来自B站 老弓的学习笔记
链接:https://www.bilibili.com/video/BV1x44y1r7Zc?spm_id_from=333.999.0.0
【Adaboost】
【视频一】
集成学习:集成学习通过构建并结合多个学习器来完成学习任务
优点:可以多个学习器结合,获得比单一学习器更加显著优越的泛化性能。
需要注意的问题:
1个体学习器如何训练得到 改变训练数据的权值或概率分布
2如何讲个体学习器组合 线性相加还是其他方法?
- boosting 个体学习器存在强依赖关系,必须串行生成的序列化方法
- 工作机制:提高前一轮被弱分类器分错的样本的权值,减小哪些在前一轮被弱分类器分对的样本的权值,使误分类的样本在后续受到更多的关注。
- 体现了串行
- 【加法模型】将弱分类器进行【线性组合】
- 代表算法
- adaboose
- GBDT
- XGBoost
- LightGBM
- bagging
- 个体之间不存在强依赖关系,可同时生成的并行化方法。
- 工作机制:1从原始样本集抽出k个训练集 。 2 k个训练集分别训练,得到k个模型 体现了并行。 3 将上部分得到的k个模型,通过一定的方式组合起来(自助法,有放回抽样,可能抽到重复的样本。随机森林中还会抽取一定的特征)(分来问题【投票的方式】回归问题【均值】)
- 代表算法
- 随机森林
【视频二】
Adaboost解决的问题是二分类问题

 相当于改变了样本数量
相当于改变了样本数量
【视频三】
算法流程:
- 二分类训练数据集

- 定义基分类器G(x)
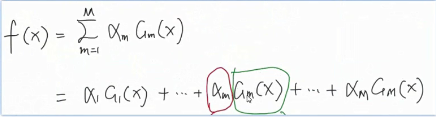
一般基分类器都是同一种类型,比如都是逻辑回归。定下了基分类器 那么训练方法也确定了 比如说交叉熵损失。
- 循环M次 每次训练一个
- 初始化\更新当前【训练数据的权值分布】
- if初始化
![]()
- if更新
![]()
主要功能就是降低正确分类样本的权重 升高分类错误的权重
- if初始化
- 训练当前基分类器Gm(x)
- 使用具有权值分布Dm的训练数据集学习 得到基分类器Gm(x)
- 计算当前基分类器的权值am
- 由Gm(x)的分类误差率决定。如果分类误差率小,则将系数调大
- 1.计算Gm(x)在训练数据集上的【分类误差率】
![]()
- 2.根据【分类误差率em】,计算基分类器Gm(x)的权重系数
![]()
- 1.计算Gm(x)在训练数据集上的【分类误差率】
- 由Gm(x)的分类误差率决定。如果分类误差率小,则将系数调大
- 将amGm(x)更新到加法模型f(x)中
- 判断是否满足循环退出条件
- 分类器个数是否达到M
- 总分类器误差率是否低于设定的精度
- 初始化\更新当前【训练数据的权值分布】
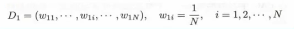

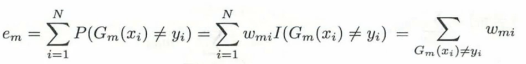
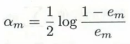
【视频四】
【例题】
二分类数据集

定义弱分类器
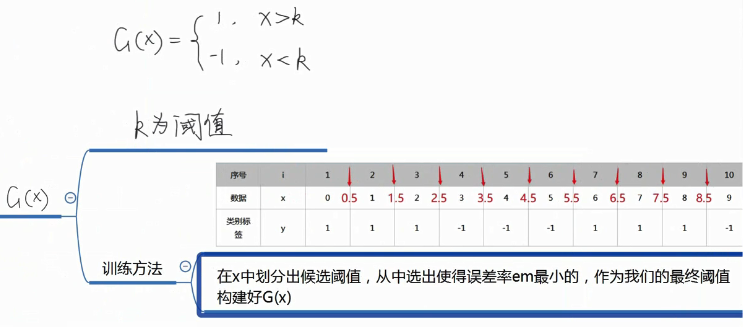
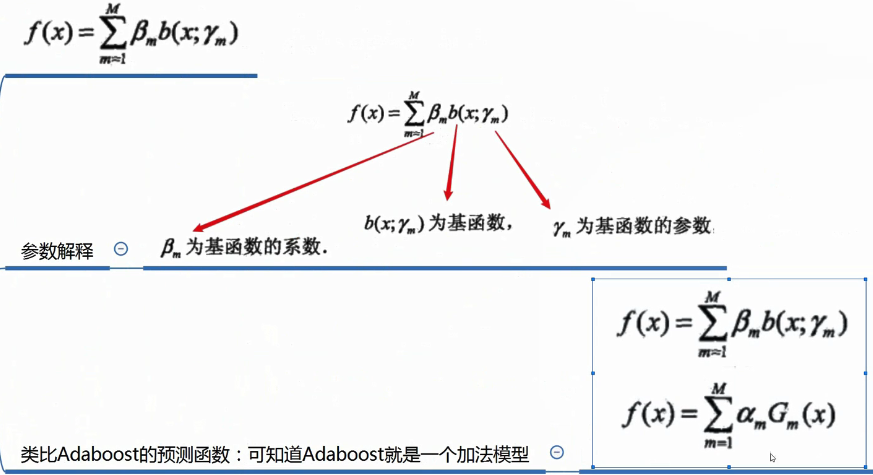
加法模型
预测函数:
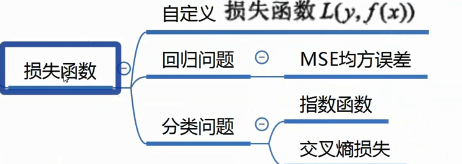
损失函数:
优化方法:
梯度下降的方法是复杂度高



 浙公网安备 33010602011771号
浙公网安备 33010602011771号