如何处理句对文本分类的数据问题?
将要做试验了突然发现不会这个问题。
来源链接:CSDN https://blog.csdn.net/qq_42464569/article/details/123239558
处理句子对
有时可能需要将一对句子送入模型。比如,我们需要判断两个句子是否相似;或我们在使用问答模型,需要将文本和问题送入模型。对于BERT模型,句子对需要转化为如下形式:[CLS] Sequence A [SEP] Sequence B [SEP]
在使用Transformers处理句子对时,我们需要将两个句子以不同的变量传入文本标记器中(注意,并不是像之前那样整合成列表,而是两个分开的变量)。然后我们会得到一个对应的字典,如下例:
从结果我们可以看出token_type_ids的作用:它们告诉模型输入的那个部分属于第一个句子,那个部分属于第二个句子。需要注意的是,并不是所有模型都需要token_tyoe_ids。默认情况下,文本标记器只会返回与模型相关的期望输入。你可以传入一些如return_token_type_ids或return_length的参数来改变文本标记器的输出。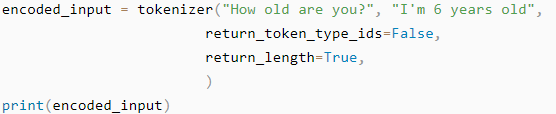
输出:
{'input_ids': [101, 1731, 1385, 1132, 1128, 136, 102, 146, 112, 182, 127, 1201, 1385, 102], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], 'length': 14}
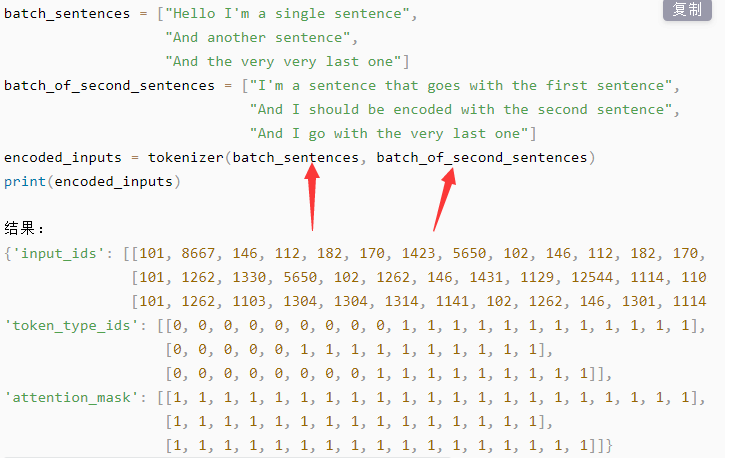
同样,如果你向一次性处理多条语句,你可以分别传入两个文本列表。如下:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号