
spark相关介绍-提取hive表(一)
本文环境说明
centos服务器
jupyter的scala核spylon-kernel
spark-2.4.0
scala-2.11.12
hadoop-2.6.0
本文主要内容
- spark读取hive表的数据,主要包括直接sql读取hive表;通过hdfs文件读取hive表,以及hive分区表的读取。
- 通过jupyter上的cell来初始化sparksession。
- 文末还有通过spark提取hdfs文件的完整示例
jupyter配置文件
- 我们可以在jupyter的cell框里面,对spark的session做出对应的初始化,具体可以见下面的示例。
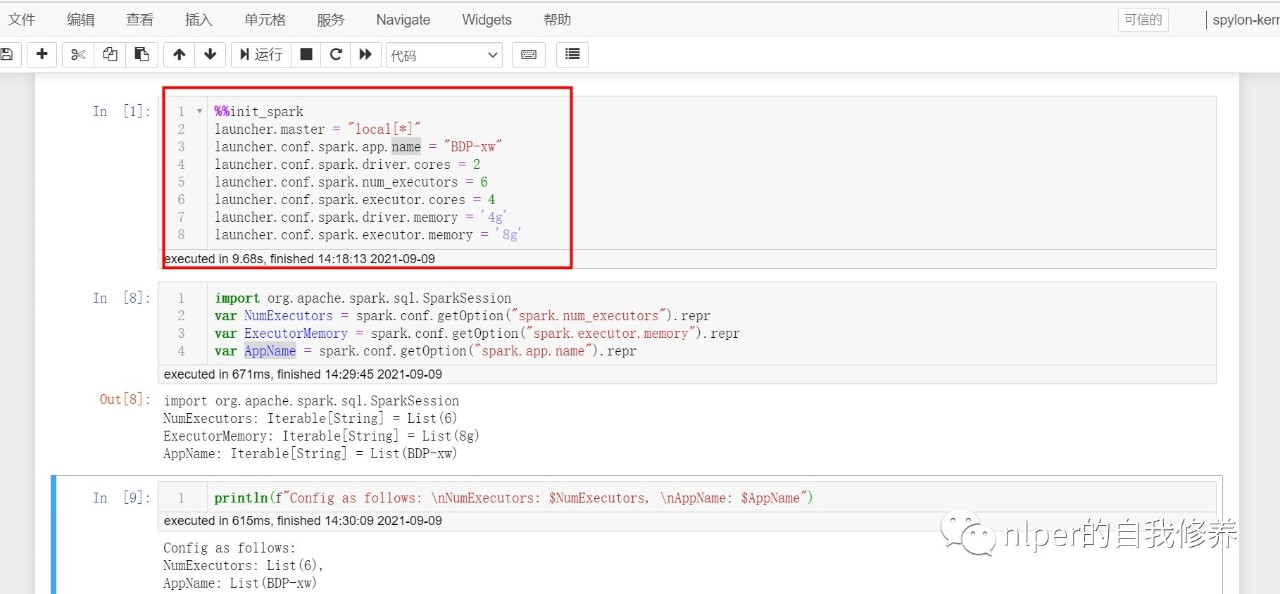
%%init_spark
launcher.master = "local[*]"
launcher.conf.spark.app.name = "BDP-xw"
launcher.conf.spark.driver.cores = 2
launcher.conf.spark.num_executors = 3
launcher.conf.spark.executor.cores = 4
launcher.conf.spark.driver.memory = '4g'
launcher.conf.spark.executor.memory = '4g'
// launcher.conf.spark.serializer = "org.apache.spark.serializer.KryoSerializer"
// launcher.conf.spark.kryoserializer.buffer.max = '4g'
import org.apache.spark.sql.SparkSession
var NumExecutors = spark.conf.getOption("spark.num_executors").repr
var ExecutorMemory = spark.conf.getOption("spark.executor.memory").repr
var AppName = spark.conf.getOption("spark.app.name").repr
var max_buffer = spark.conf.getOption("spark.kryoserializer.buffer.max").repr
println(f"Config as follows: \nNumExecutors: $NumExecutors, \nAppName: $AppName,\nmax_buffer:$max_buffer")
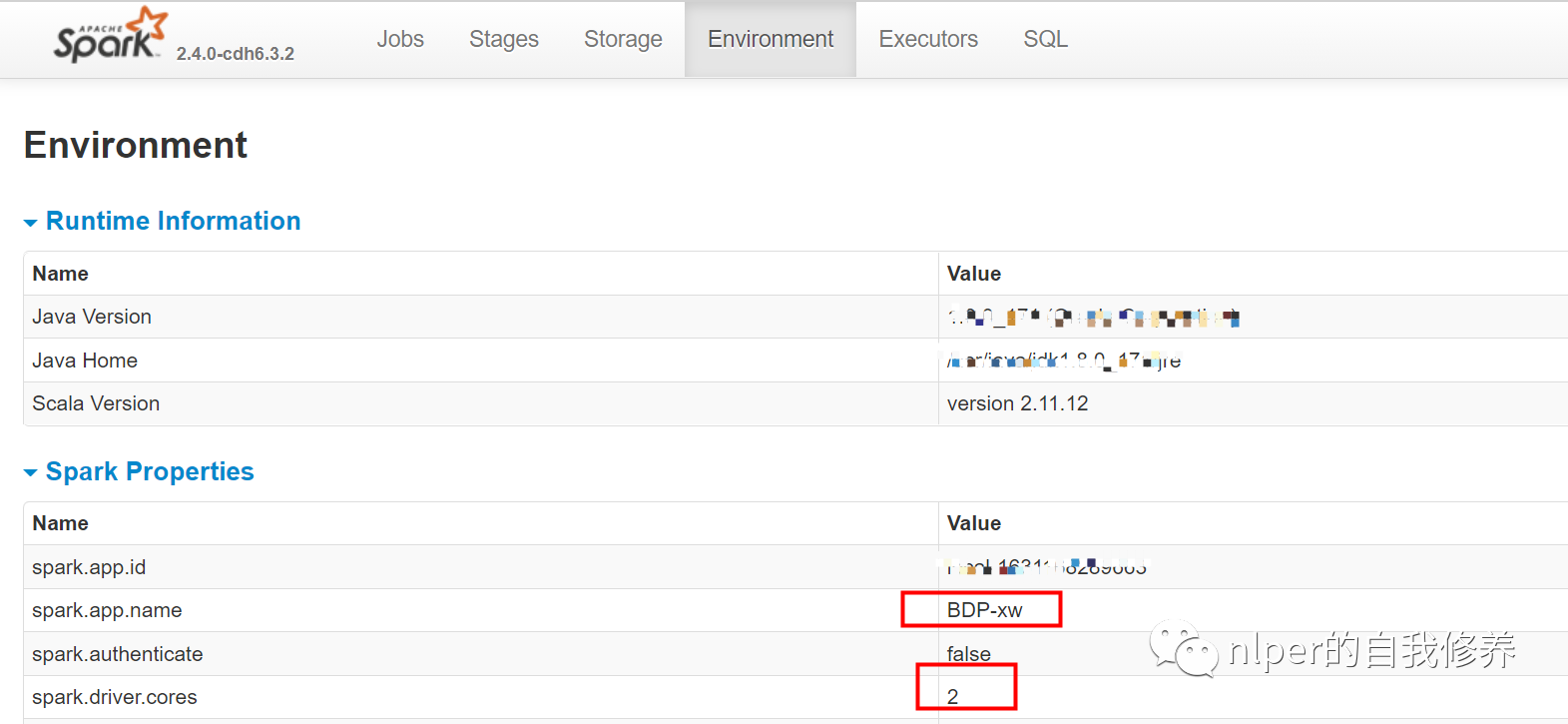
- 直接查看我们初始化的sparksession对应的环境各变量
从hive中取数
直接sparksql走起
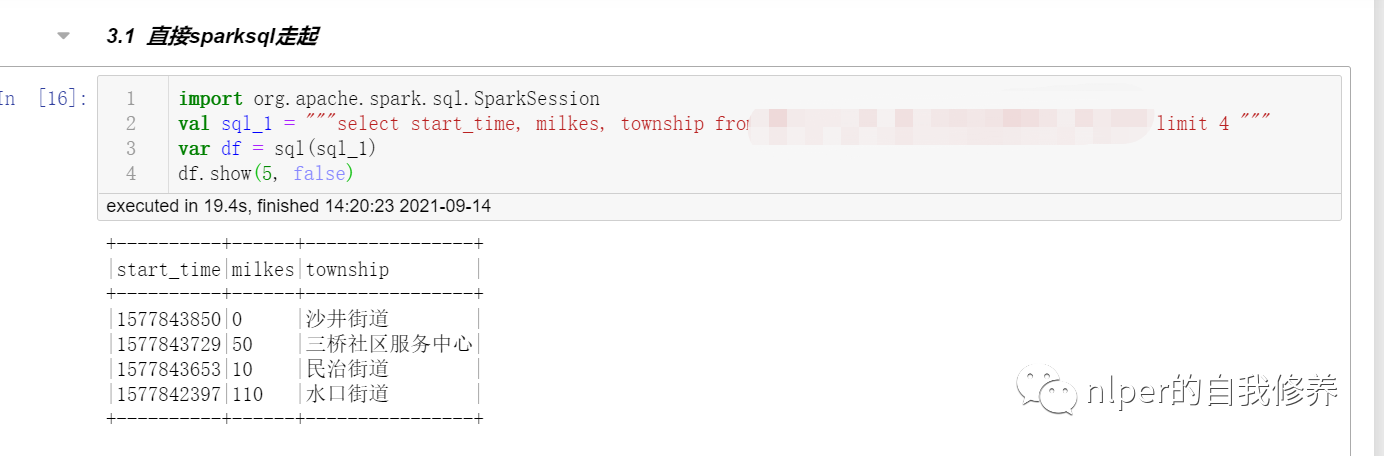
import org.apache.spark.sql.SparkSession
val sql_1 = """select * from tbs limit 4 """
var df = sql(sql_1)
df.show(5, false)
通过hdfs取数
- 具体示例可以参考文末的从hdfs取数完整脚本示例
object LoadingData_from_hdfs_base extends mylog{// with Logging
...
def main(args: Array[String]=Array("tb1", "3", "\001", "cols", "")): Unit = {
if (args.length < 2) {
println("Usage: LoadingData_from_hdfs <tb_name, parts. sep_line, cols, paths>")
System.err.println("Usage: LoadingData_from_hdfs <tb_name, parts, sep_line, cols, paths>")
System.exit(1)
}
log.warn("开始啦调度")
val tb_name = args(0)
val parts = args(1)
val sep_line = args(2)
val select_col = args(3)
val save_paths = args(4)
val select_cols = select_col.split("#").toSeq
log.warn(s"Loading cols are : \n $select_cols")
val gb_sql = s"DESCRIBE FORMATTED ${tb_name}"
val gb_desc = sql(gb_sql)
val hdfs_address = gb_desc.filter($"col_name".contains("Location")).take(1)(0).getString(1)
val hdfs_address_cha = s"$hdfs_address/*/"
val Cs = new DataProcess_base(spark)
val tb_desc = Cs.get_table_desc(tb_name)
val raw_data = Cs.get_hdfs_data(hdfs_address)
val len1 = raw_data.map(item => item.split(sep_line)).first.length
val names = tb_desc.filter(!$"col_name".contains("#")).dropDuplicates(Seq("col_name")).sort("id").select("col_name").take(len1).map(_(0)).toSeq.map(_.toString)
val schema1 = StructType(names.map(fieldName => StructField(fieldName, StringType)))
val rawRDD = raw_data.map(_.split(sep_line).map(_.toString)).map(p => Row(p: _*)).filter(_.length == len1)
val df_data = spark.createDataFrame(rawRDD, schema1)//.filter("custommsgtype = '1'")
val df_desc = select_cols.toDF.join(tb_desc, $"value"===$"col_name", "left")
val df_gb_result = df_data.select(select_cols.map(df_data.col(_)): _*)//.limit(100)
df_gb_result.show(5, false)
...
// spark.stop()
}
}
val cols = "area_name#city_name#province_name"
val tb_name = "tb1"
val sep_line = "\u0001"
// 执行脚本
LoadingData_from_hdfs_base.main(Array(tb_name, "4", sep_line, cols, ""))
)
判断路径是否为文件夹
- 方式1
def pathIsExist(spark: SparkSession, path: String): Boolean = {
val filePath = new org.apache.hadoop.fs.Path( path )
val fileSystem = filePath.getFileSystem( spark.sparkContext.hadoopConfiguration )
fileSystem.exists( filePath )
}
pathIsExist(spark, hdfs_address)
// 得到结果如下:
// pathIsExist: (spark: org.apache.spark.sql.SparkSession, path: String)Boolean
// res4: Boolean = true
- 方式2
import java.io.File
val d = new File("/usr/local/xw")
d.isDirectory
// 得到结果如下:
// d: java.io.File = /usr/local/xw
// res3: Boolean = true
分区表读取源数据
- 对分区文件需要注意下,需要保证原始的hdfs上的raw文件里面是否有对应的分区字段值
- 如果分区字段在hdfs中的原始文件中,则可以直接通过通过hdfs取数
- 若原始文件中,不包括分区字段信息,则需要按照以下方式取数啦
- 具体示例可以参考文末的从hdfs取数完整脚本示例
单个文件读取
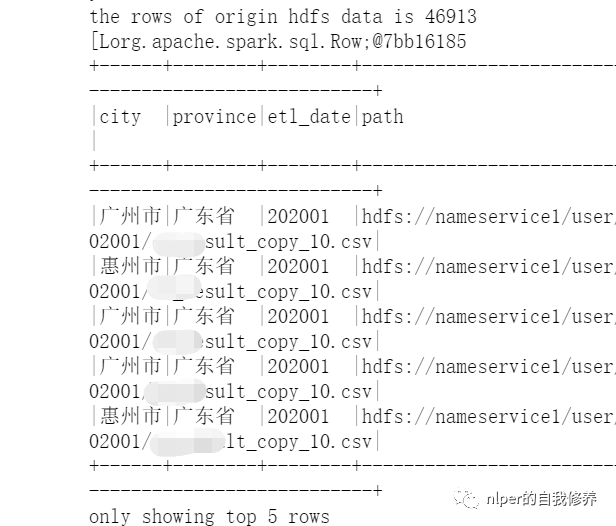
object LoadingData_from_hdfs_onefile_with_path extends mylog{
def main(args: Array[String]=Array("tb_name", "hdfs:/", "3","\n", "\001", "cols", "")): Unit = {
...
val hdfs_address = args(1)
val len1 = raw_data.map(item => item.split(sep_line)).first.length
val rawRDD = raw_data.flatMap(line => line.split(sep_text)).map(word => (word.split(sep_line):+hdfs_address)).map(p => Row(p: _*))
println(rawRDD.take(2))
val names = tb_desc.filter(!$"col_name".contains("#")).dropDuplicates(Seq("col_name")).sort("id").select("col_name").take(len1).map(_(0)).toSeq.map(_.toString)
import org.apache.spark.sql.types.StructType
val schema1 = StructType(names.map(fieldName => StructField(fieldName, StringType)))
val new_schema1 = schema1.add(StructField("path", StringType))
val df_data = spark.createDataFrame(rawRDD, new_schema1)
val df_desc = select_cols.toDF.join(tb_desc, $"value"===$"col_name", "left")
// df_desc.show(false)
val df_gb_result = df_data.select(select_cols.map(df_data.col(_)): _*)//.limit(100)
df_gb_result.show(5, false)
...
// spark.stop()
}
}
val file1 = "hdfs:file1.csv"
val tb_name = "tb_name"
val sep_text = "\n"
val sep_line = "\001"
val cols = "city#province#etl_date#path"
// 执行脚本
LoadingData_from_hdfs_onefile_with_path.main(Array(tb_name, file1, "4", sep_line, sep_text, cols, ""))
多个文件读取尝试1
- 通过wholeTextFiles读取文件夹里面的文件时,保留文件名信息;
- 具体示例可以参考文末的从hdfs取数完整脚本示例
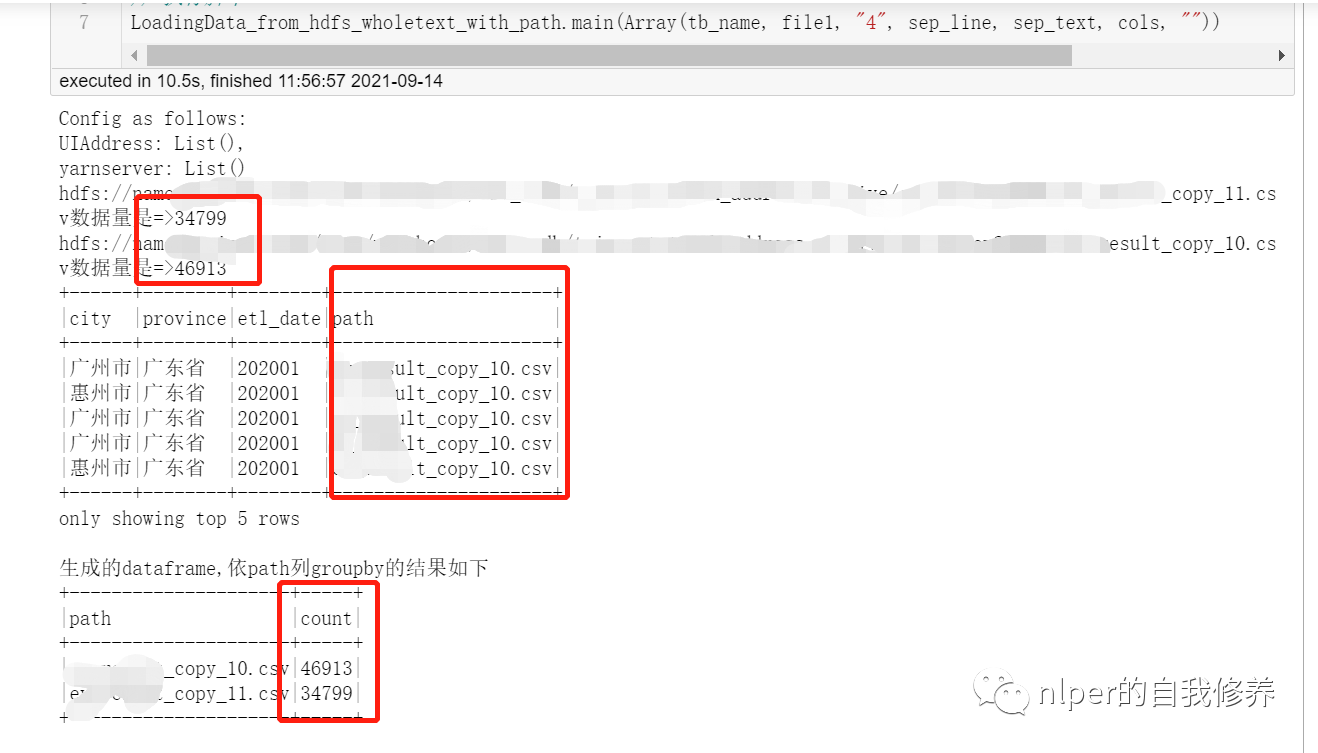
object LoadingData_from_hdfs_wholetext_with_path extends mylog{// with Logging
...
def main(args: Array[String]=Array("tb1", "hdfs:/", "3","\n", "\001", "cols", "")): Unit = {
...
val tb_name = args(0)
val hdfs_address = args(1)
val parts = args(2)
val sep_line = args(3)
val sep_text = args(4)
val select_col = args(5)
val save_paths = args(6)
val select_cols = select_col.split("#").toSeq
val Cs = new DataProcess_get_data(spark)
val tb_desc = Cs.get_table_desc(tb_name)
val rddWhole = spark.sparkContext.wholeTextFiles(s"$hdfs_address", 10)
rddWhole.foreach(f=>{
println(f._1+"数据量是=>"+f._2.split("\n").length)
})
val files = rddWhole.collect
val len1 = files.flatMap(item => item._2.split(sep_text)).take(1).flatMap(items=>items.split(sep_line)).length
val names = tb_desc.filter(!$"col_name".contains("#")).dropDuplicates(Seq("col_name")).sort("id").select("col_name").take(len1).map(_(0)).toSeq.map(_.toString)
import org.apache.spark.sql.types.StructType
// 解析wholeTextFiles读取的结果并转化成dataframe
val wordCount = files.map(f=>f._2.split(sep_text).map(g=>g.split(sep_line):+f._1.split("/").takeRight(1)(0))).flatMap(h=>h).map(p => Row(p: _*))
val schema1 = StructType(names.map(fieldName => StructField(fieldName, StringType)))
val new_schema1 = schema1.add(StructField("path", StringType))
val rawRDD = sc.parallelize(wordCount)
val df_data = spark.createDataFrame(rawRDD, new_schema1)
val df_desc = select_cols.toDF.join(tb_desc, $"value"===$"col_name", "left")
//df_desc.show(false)
val df_gb_result = df_data.select(select_cols.map(df_data.col(_)): _*)
df_gb_result.show(5, false)
println("生成的dataframe,依path列groupby的结果如下")
df_gb_result.groupBy("path").count().show(false)
...
// spark.stop()
}
}
val file1 = "hdfs:file1_1[01].csv"
val tb_name = "tb_name"
val sep_text = "\n"
val sep_line = "\001"
val cols = "city#province#etl_date#path"
// 执行脚本
LoadingData_from_hdfs_wholetext_with_path.main(Array(tb_name, file1, "4", sep_line, sep_text, cols, ""))
读取多文件且保留文件名为列名技术实现
-
以下实现功能
- 将
Array[(String, String)]类型的按(String, String)拆成多行; - 将(String, String)中的第2个元素,按照
\n分割符分成多行,按\?分隔符分成多列; - 将(String, String)中的第1个元素,分别加到2中的每行后面。在dataframe中呈现的就是新增一列啦
- 将
-
业务场景
- 如果要一次读取多个文件,且相对合并后的数据集中,对数据来源于哪一个文件作出区分。
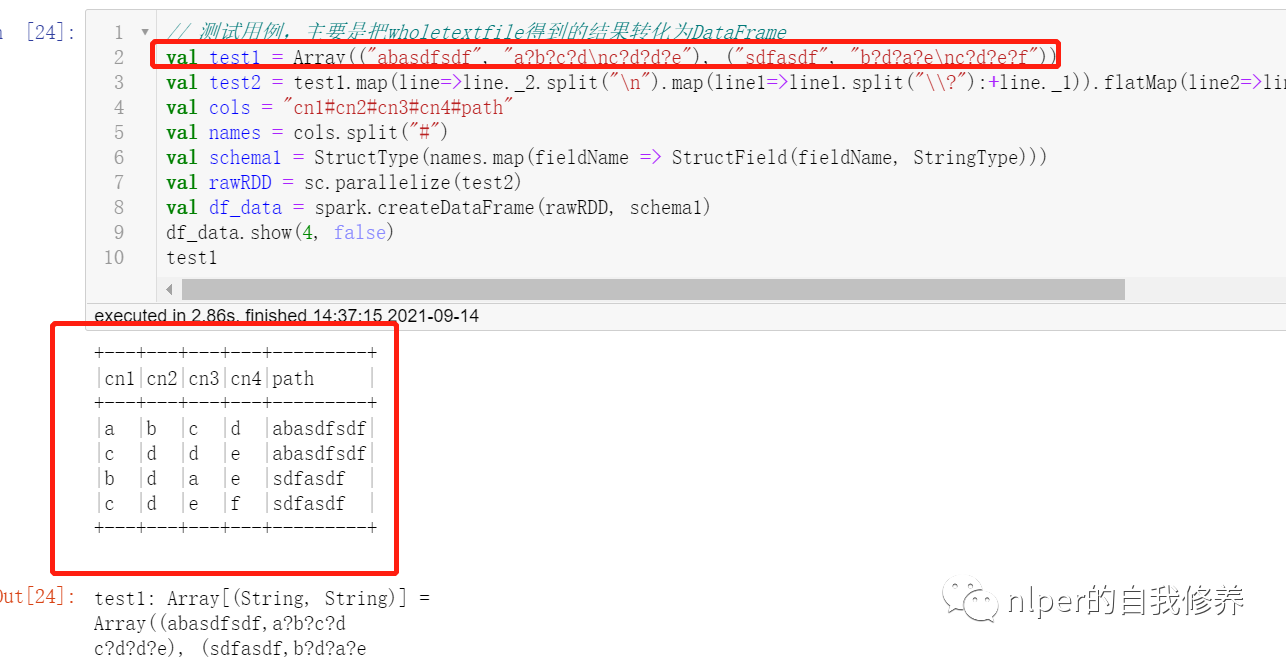
// 测试用例,主要是把wholetextfile得到的结果转化为DataFrame
val test1 = Array(("abasdfsdf", "a?b?c?d\nc?d?d?e"), ("sdfasdf", "b?d?a?e\nc?d?e?f"))
val test2 = test1.map(line=>line._2.split("\n").map(line1=>line1.split("\\?"):+line._1)).flatMap(line2=>line2).map(p => Row(p: _*))
val cols = "cn1#cn2#cn3#cn4#path"
val names = cols.split("#")
val schema1 = StructType(names.map(fieldName => StructField(fieldName, StringType)))
val rawRDD = sc.parallelize(test2)
val df_data = spark.createDataFrame(rawRDD, schema1)
df_data.show(4, false)
test1
多个文件读取for循环
- 通过for循环遍历读取文件夹里面的文件时,保留文件名信息;
- 具体示例可以参考文末的从hdfs取数完整脚本示例
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Row}
import org.apache.spark.sql.SparkSession
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql.functions.monotonically_increasing_id
import org.apache.log4j.{Level, Logger}
import org.apache.spark.sql.types.{StructType, StructField, StringType, IntegerType}
import org.apache.hadoop.fs.{FileSystem, Path}
Logger.getLogger("org").setLevel(Level.WARN)
// val log = Logger.getLogger(this.getClass)
@transient lazy val log:Logger = Logger.getLogger(this.getClass)
class DataProcess_get_data_byfor (ss: SparkSession) extends java.io.Serializable{
import ss.implicits._
import ss.sql
import org.apache.spark.sql.types.DataTypes
...
def union_dataframe(df_1:RDD[String], df_2:RDD[String]):RDD[String] ={
val count1 = df_1.map(item=>item.split(sep_line)).take(1)(0).length
val count2 = df_2.map(item=>item.split(sep_line)).take(1)(0).length
val name2 = df_2.name.split("/").takeRight(1)(0)
val arr2 = df_2.map(item=>item.split(sep_line):+name2).map(p => Row(p: _*))
println(s"运行到这儿了")
var name1 = ""
var arr1 = ss.sparkContext.makeRDD(List().map(p => Row(p: _*)))
// var arr1 = Array[org.apache.spark.sql.Row]
if (count1 == count2){
name1 = df_1.name.split("/").takeRight(1)(0)
arr1 = df_1.map(item=>item.split(sep_line):+name1).map(p => Row(p: _*))
// arr1.foreach(f=>print(s"arr1嘞$f" + f.length + "\n"))
println(s"运行到这儿了没?$count1~$count2 $name1/$name2")
arr1
}
else{
println(s"运行到这儿了不相等哈?$count1~$count2 $name1/$name2")
arr1 = df_1.map(item=>item.split(sep_line)).map(p => Row(p: _*))
}
var rawRDD = arr1.union(arr2)
// arr3.foreach(f=>print(s"$f" + f.length + "\n"))
// var rawRDD = sc.parallelize(arr3)
var sourceRdd = rawRDD.map(_.mkString(sep_line))
// var count31 = arr1.take(1)(0).length
// var count32 = arr2.take(1)(0).length
// var count3 = sourceRdd.map(item=>item.split(sep_line)).take(1)(0).length
// var nums = sourceRdd.count
// print(s"arr1: $count31、arr2: $count32、arr3: $count3, 数据量为:$nums")
sourceRdd
}
}
object LoadingData_from_hdfs_text_with_path_byfor extends mylog{// with Logging
...
def main(args: Array[String]=Array("tb1", "hdfs:/", "3","\n", "\001", "cols","data1", "test", "")): Unit = {
...
val hdfs_address = args(1)
...
val pattern = args(6)
val pattern_no = args(7)
val select_cols = select_col.split("#").toSeq
log.warn(s"Loading cols are : \n $select_cols")
val files = FileSystem.get(spark.sparkContext.hadoopConfiguration).listStatus(new Path(s"$hdfs_address"))
val files_name = files.toList.map(f=> f.getPath.getName)
val file_filter = files_name.filter(_.contains(pattern)).filterNot(_.contains(pattern_no))
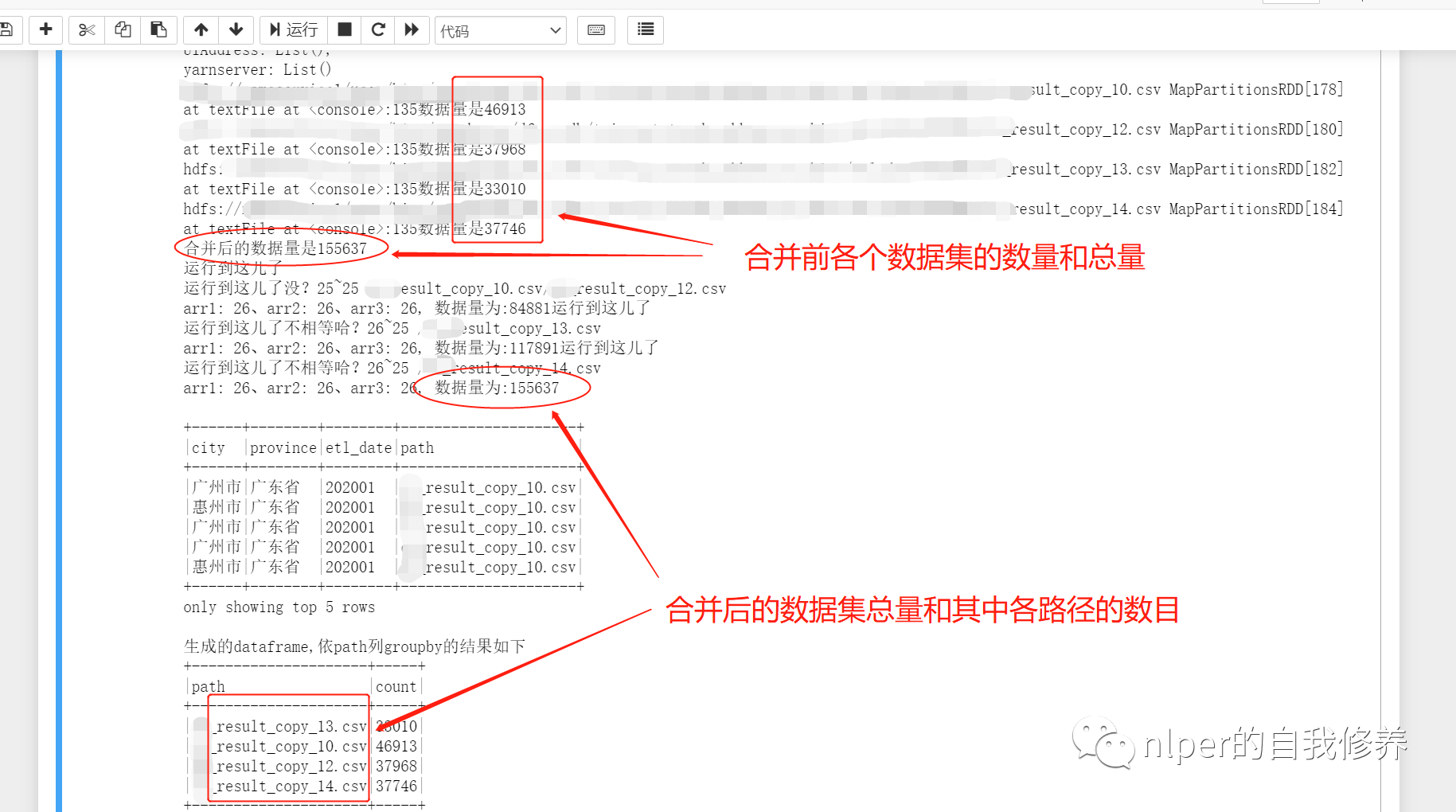
val df_1 = file_filter.map(item=> sc.textFile(s"$path1$item"))
df_1.foreach(f=>{
println(f + "数据量是" + f.count)
})
val df2 = df_1.reduce(_ union _)
println("合并后的数据量是" + df2.count)
val Cs = new DataProcess_get_data_byfor(spark)
...
// 将for循环读取的结果合并起来
val result = df_1.reduce((a, b)=>union_dataframe(a, b))
val result2 = result.map(item=>item.split(sep_line)).map(p => Row(p: _*))
val df_data = spark.createDataFrame(result2, new_schema1)
val df_desc = select_cols.toDF.join(tb_desc, $"value"===$"col_name", "left")
println("\n")
//df_desc.show(false)
val df_gb_result = df_data.select(select_cols.map(df_data.col(_)): _*)
df_gb_result.show(5, false)
println("生成的dataframe,依path列groupby的结果如下")
df_gb_result.groupBy("path").count().show(false)
...
// spark.stop()
}
}
val path1 = "hdfs:202001/"
val tb_name = "tb_name"
val sep_text = "\n"
val sep_line = "\001"
val cols = "city#province#etl_date#path"
val pattern = "result_copy_1"
val pattern_no = "1.csv"
// val file_filter = List("file1_10.csv", "file_12.csv", "file_11.csv")
// 执行脚本
LoadingData_from_hdfs_text_with_path_byfor.main(Array(tb_name, path1, "4", sep_line, sep_text, cols, pattern, pattern_no, ""))
执行脚本的完整示例
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Row}
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions.monotonically_increasing_id
import org.apache.log4j.{Level, Logger}
import org.apache.spark.sql.types.{StructType, StructField, StringType, IntegerType}
Logger.getLogger("org").setLevel(Level.WARN)
val log = Logger.getLogger(this.getClass)
class DataProcess_base (ss: SparkSession) extends java.io.Serializable{
import ss.implicits._
import ss.sql
import org.apache.spark.sql.types.DataTypes
def get_table_desc(tb_name:String="tb"):DataFrame ={
val gb_sql = s"desc ${tb_name}"
val gb_desc = sql(gb_sql)
val names = gb_desc.filter(!$"col_name".contains("#")).withColumn("id", monotonically_increasing_id())
names
}
def get_hdfs_data(hdfs_address:String="hdfs:"):RDD[String]={
val gb_data = ss.sparkContext.textFile(hdfs_address)
gb_data.cache()
val counts1 = gb_data.count
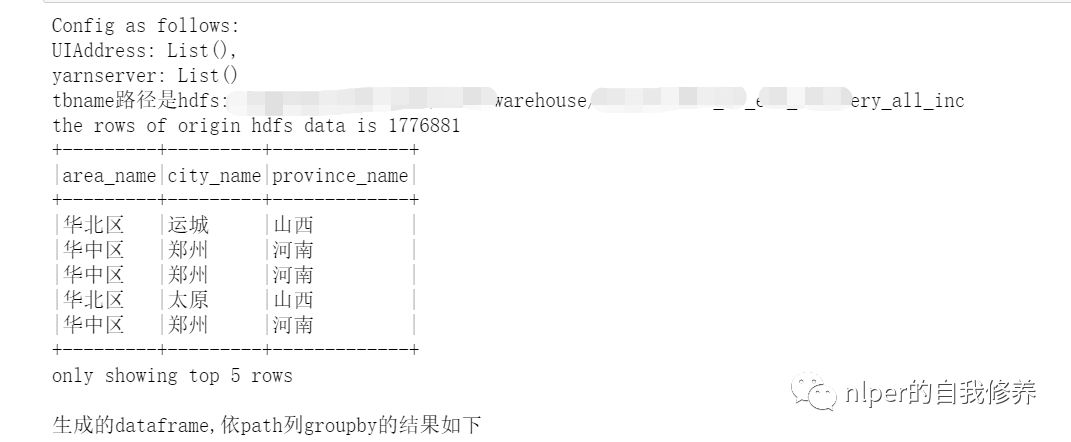
println(f"the rows of origin hdfs data is $counts1%-1d")
gb_data
}
}
object LoadingData_from_hdfs_base extends mylog{// with Logging
Logger.getLogger("org").setLevel(Level.WARN)
val conf = new SparkConf()
conf.setMaster("yarn")
conf.setAppName("LoadingData_From_hdfs")
conf.set("spark.home", System.getenv("SPARK_HOME"))
val spark = SparkSession.builder().config(conf).enableHiveSupport().getOrCreate()
import spark.implicits._
import spark.sql
var UIAddress = spark.conf.getOption("spark.driver.appUIAddress").repr
var yarnserver = spark.conf.getOption("spark.org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter.param.PROXY_URI_BASES").repr
println(f"Config as follows: \nUIAddress: $UIAddress, \nyarnserver: $yarnserver")
def main(args: Array[String]=Array("tb1", "3", "\001", "cols", "")): Unit = {
if (args.length < 2) {
println("Usage: LoadingData_from_hdfs <tb_name, parts. sep_line, cols, paths>")
System.err.println("Usage: LoadingData_from_hdfs <tb_name, parts, sep_line, cols, paths>")
System.exit(1)
}
log.warn("开始啦调度")
val tb_name = args(0)
val parts = args(1)
val sep_line = args(2)
val select_col = args(3)
val save_paths = args(4)
val select_cols = select_col.split("#").toSeq
log.warn(s"Loading cols are : \n $select_cols")
val gb_sql = s"DESCRIBE FORMATTED ${tb_name}"
val gb_desc = sql(gb_sql)
val hdfs_address = gb_desc.filter($"col_name".contains("Location")).take(1)(0).getString(1)
println(s"tbname路径是$hdfs_address")
val hdfs_address_cha = s"$hdfs_address/*/"
val Cs = new DataProcess_base(spark)
val tb_desc = Cs.get_table_desc(tb_name)
val raw_data = Cs.get_hdfs_data(hdfs_address)
val len1 = raw_data.map(item => item.split(sep_line)).first.length
val names = tb_desc.filter(!$"col_name".contains("#")).dropDuplicates(Seq("col_name")).sort("id").select("col_name").take(len1).map(_(0)).toSeq.map(_.toString)
val schema1 = StructType(names.map(fieldName => StructField(fieldName, StringType)))
val rawRDD = raw_data.map(_.split(sep_line).map(_.toString)).map(p => Row(p: _*)).filter(_.length == len1)
val df_data = spark.createDataFrame(rawRDD, schema1)//.filter("custommsgtype = '1'")
val df_desc = select_cols.toDF.join(tb_desc, $"value"===$"col_name", "left")
val df_gb_result = df_data.select(select_cols.map(df_data.col(_)): _*)//.limit(100)
df_gb_result.show(5, false)
println("生成的dataframe,依path列groupby的结果如下")
// val part = parts.toInt
// df_gb_result.repartition(part).write.mode("overwrite").option("header","true").option("sep","#").csv(save_paths)
// log.warn(f"the rows of origin data compare to mysql results is $ncounts1%-1d VS $ncounts3%-4d")
// spark.stop()
}
}
val cols = "area_name#city_name#province_name"
val tb_name = "tb1"
val sep_line = "\u0001"
// 执行脚本
LoadingData_from_hdfs_base.main(Array(tb_name, "4", sep_line, cols, ""))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号