redis学习笔记
概述以及背景
伴随数据量一步步增大,从单机mysql->缓存+mysql+垂直拆分->mysql主从读写分离->分库分表+水平拆分+mysql集群
阿里网站上图片什么的放在分布式文件系统,比如Hadoop的HDFS。热点数据(波段型)放在redis。内部搜索引擎用ISearch
传统型关系数据库需要使用范式、ER图等构建关系(1:1、1:N、N:N)建表。nosql不需要建表,json字符串即可,需要解析。
nosql使用BSON(Binary JSON)构建,实际上就是json字符串直接表示数据以及关系。

原因:分库分表技术
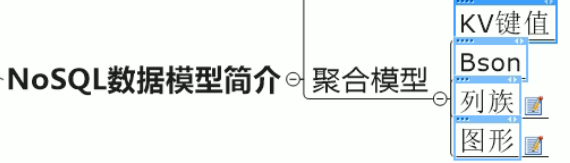
列族即value为json列表形式,不再横向拓展,改成纵向拓展。
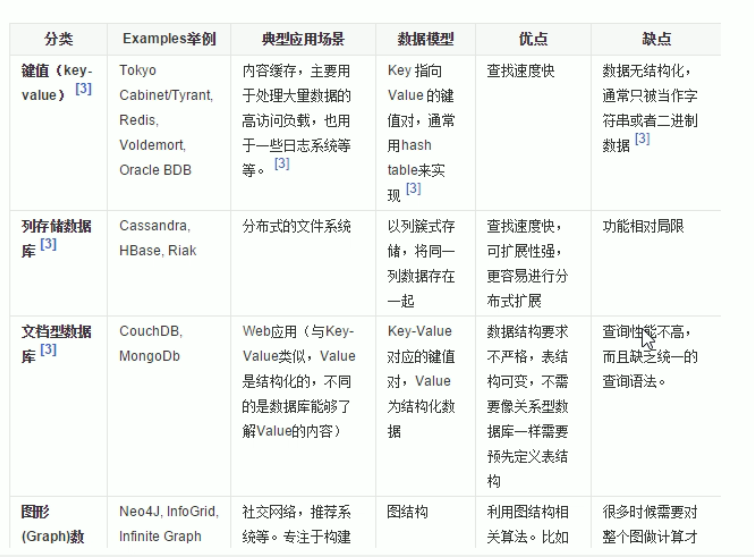
nosql数据库四种类型:
分布式数据库中CAP原理(CAP+BASE):CAP只能选两个,一般都是AP,即高可用以及分区容错。

Redis启动后的杂项基础知识


flushall 清空所有redis库,flushdb清空当前库。6379端口纪念merz redis作者名字
redis数据类型

redis string类型底层实现
没有使用c语言原始string,而是自己实现了sds的一个数据结构,可以O(1)的实现长度获取,并避免频繁内存分配,参考ArrayList的带容量的构造方式。另外c语言的字符串是通过判断是否有空字符\0判断结尾的,如果数据流本身含有\0就会出问题,redis的话通过len来判断字符串长度。





整理javaguide:

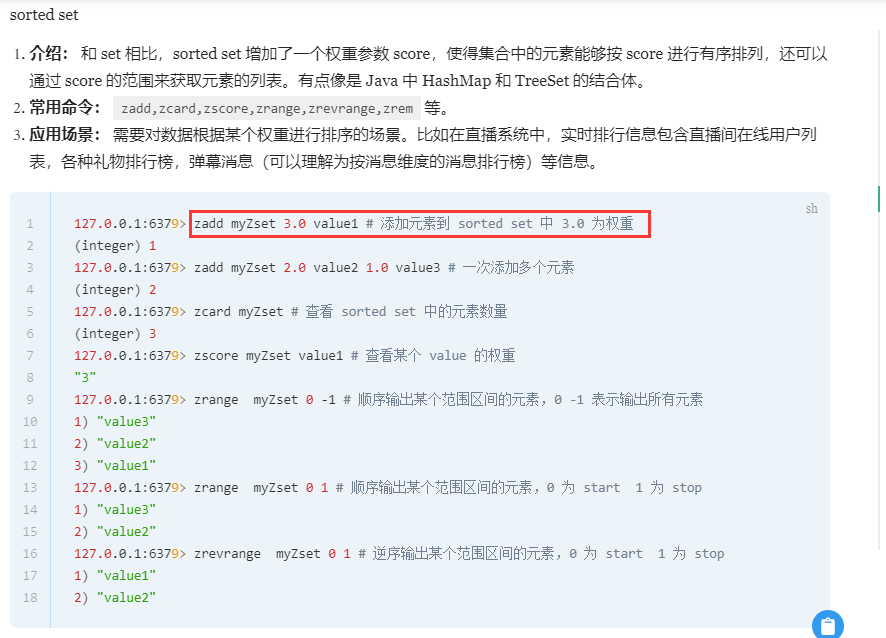
常用结构:

bitmap也可以实现布隆过滤器


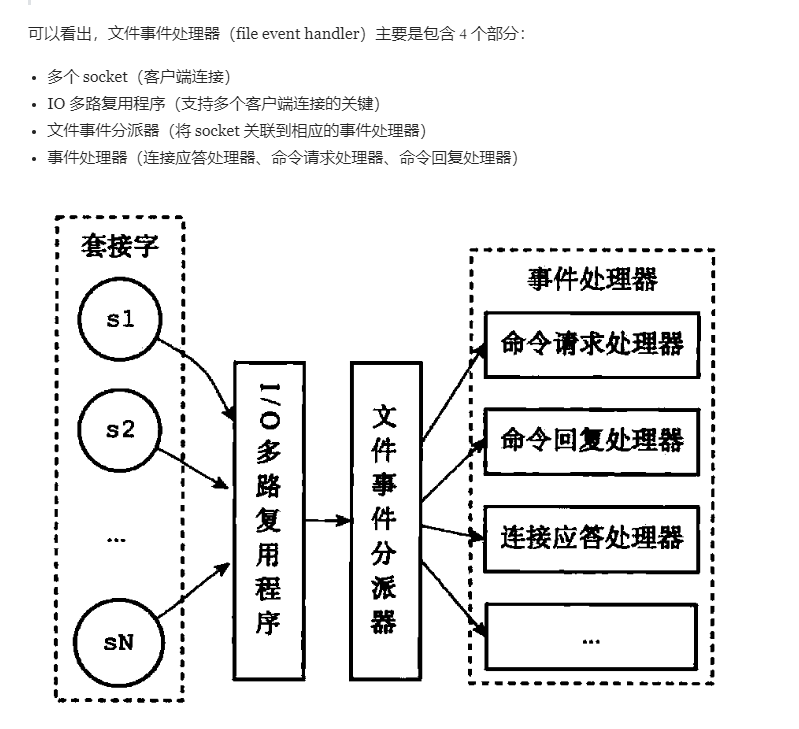
Redis 没有使用多线程?为什么不使用多线程?


Redis 给缓存数据设置过期时间有啥用?
1、主要还是缓解内存消耗,因为内存是有限的,如果缓存中的所有数据都是一直保存的话,分分钟直接 Out of memory。
2、业务场景就是需要某个数据只在某一时间段内存在,比如我们的短信验证码可能只在 1 分钟内有效,用户登录的 token 可能只在 1 天内有效。


内存淘汰机制:一个是针对已设置过期时间的key集合进行淘汰,分别为lru(最近最少用)、随机、最先过期。另外就是针对所有keys,防止某些key没有设置过期时间,分别是lru、随机淘汰。另外就是不淘汰,内存满了直接报错,这个一般没人用。


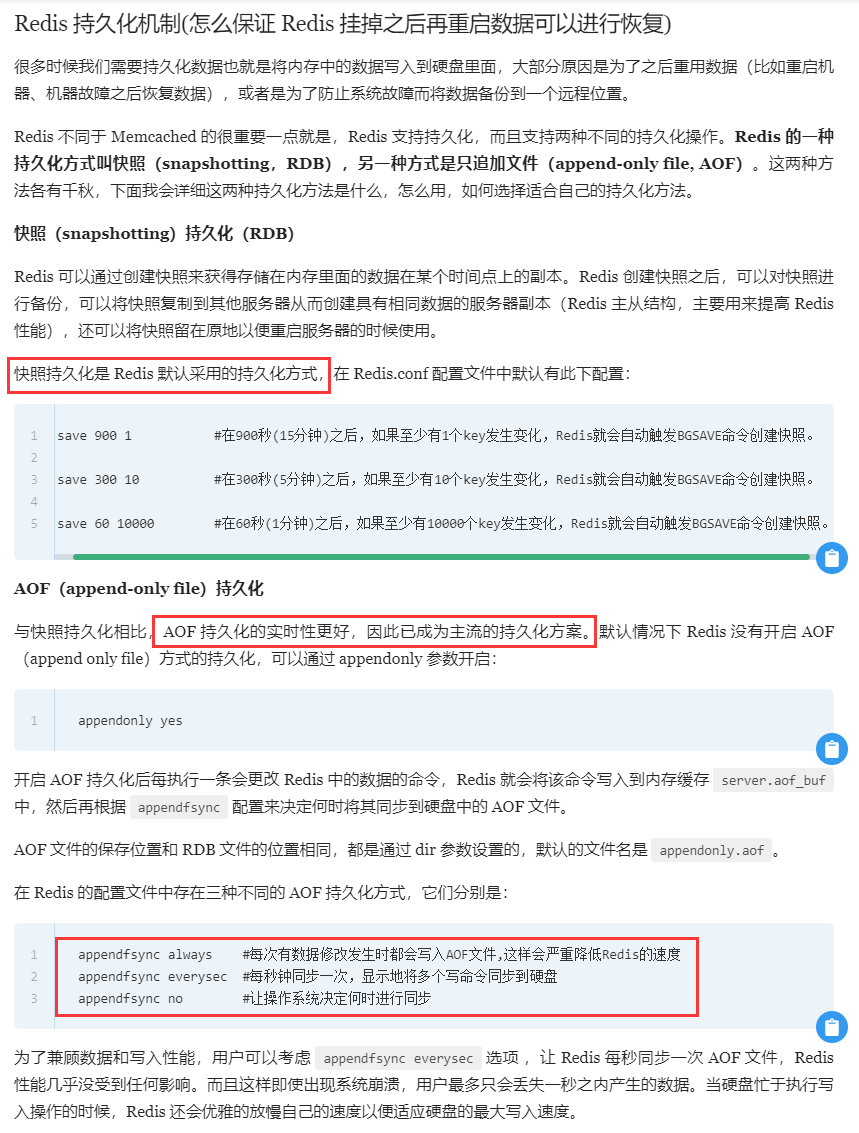
AOF重写
无须对现有 AOF 文件进行任何读入、分析或者写入操作。在执行 BGREWRITEAOF 命令时,Redis 服务器会维护一个 AOF 重写缓冲区,该缓冲区会在子进程创建新 AOF 文件期间,记录服务器执行的所有写命令。当子进程完成创建新 AOF 文件的工作之后,服务器会将重写缓冲区中的所有内容追加到新 AOF 文件的末尾,使得新的 AOF 文件保存的数据库状态与现有的数据库状态一致。最后,服务器用新的 AOF 文件替换旧的 AOF 文件,以此来完成 AOF 文件重写操作。
实际上就是把当前redis的快照以aof的形式重新保存下来替代旧aof。能够体现出当前redis的数据状态。

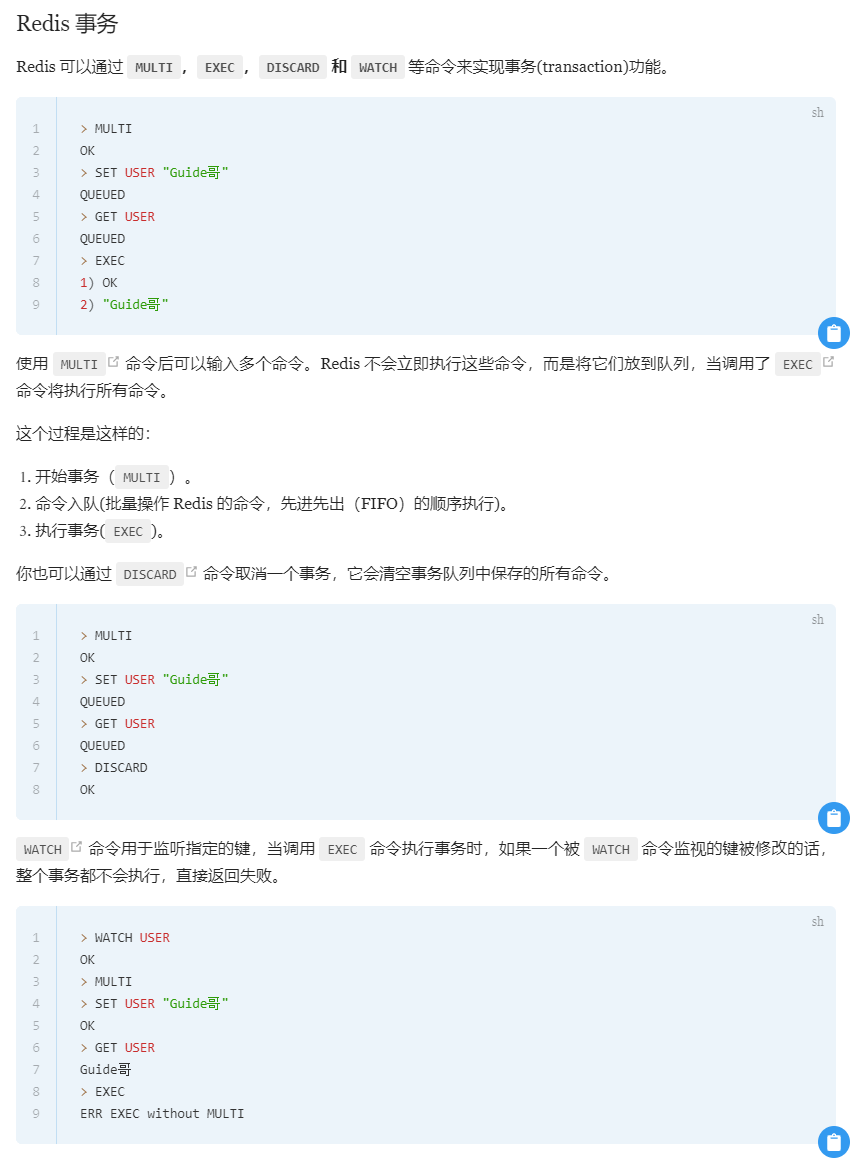
redis事务:通过multi和exec执行。multi事务开始,exec开始执行。Redis 是不支持 roll back 的,因而不满足原子性的(而且不满足持久性)。你可以将 Redis 中的事务就理解为 :Redis 事务提供了一种将多个命令请求打包的功能。然后,再按顺序执行打包的所有命令,并且不会被中途打断。如果执行错误不会回滚。
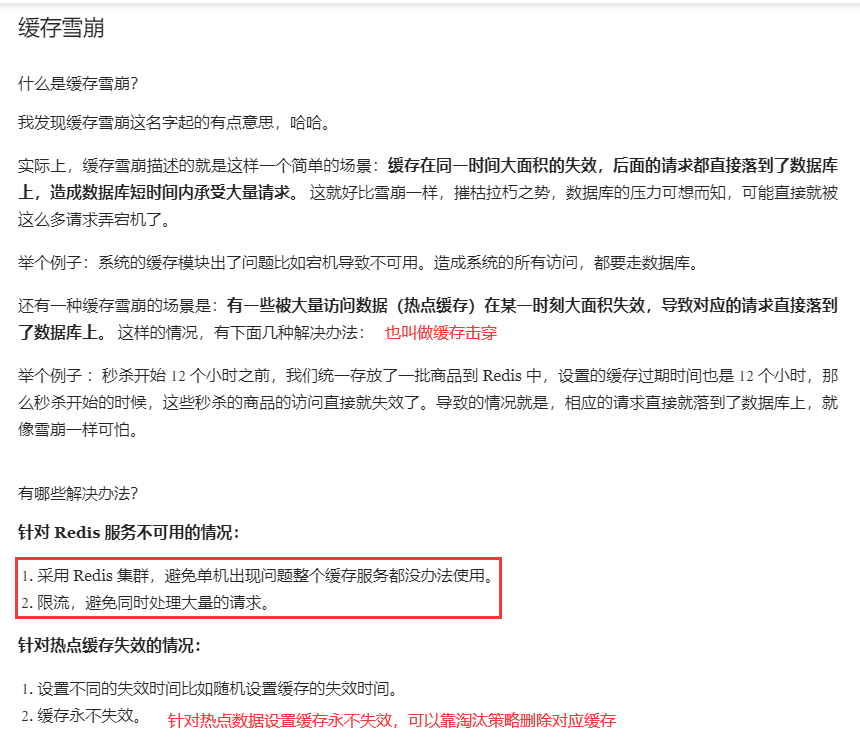
缓存穿透
缓存穿透说简单点就是大量请求的 key 根本不存在于缓存中,导致请求直接到了数据库上,根本没有经过缓存这一层。
解决办法:
1、缓存无效key,设置过期时间。即如果数据库拿到的数据为空,也放入redis缓存,并且设置过期时间。但是这样可能会产生很多无效缓存,不能从根本解决问题。
2、布隆过滤器(使用bitset实现)


布隆过滤器如何更新?或者删除一个key的时候,布隆过滤器怎么做保持一致性的?

缓存击穿还有一种解决方案就是设置锁,如果缓存不存在,先上锁再去查数据库,这样做对性能影响比较大。

redis的四种运行模式
https://blog.csdn.net/yizhiniu_xuyw/article/details/109121531
crc16算法产生65535hash值,redis为什么设置16384个槽位?
参考链接:https://blog.csdn.net/TineAine/article/details/106765068

 浙公网安备 33010602011771号
浙公网安备 33010602011771号